







介绍
这里用简单的网络来预测CSDN的阅读量。
我希望训练后的模型,给它前7天的阅读量,让它预测出第八天的阅读量。
阅读量的数据(很少)采用CSDN提供的excel文件:

这里采用xrld工具包来读取文件。
def get_readings():
book = xlrd.open_workbook('./data/article_readings.xlsx')
sheet1 = book.sheet_by_name('sheet1') # excel中一个文件有多个表格,因为数据量小,所以就一个表格
cols = sheet1.col_values(1) # 获取第一列的数据,也就是阅读量
readings = []
for i in range(8, len(cols)): # 要8天的数据,7天作为输入,第8天作为损失函数的比较参数
pre_days = []
for j in range(i - 7, i):
pre_days.append(int(cols[j]))
pre_days.append(int(cols[i]))
readings.append(pre_days)
return readings # 每一列都是这样的:[34, 10, 62, 50, 7, 10, 7, 48]
训练的xlsx文件:
阿里云盘
链接:https://www.aliyundrive.com/s/eQcRpbuWakp
百度网盘
链接:https://pan.baidu.com/s/1Icz5QOtFWe58pX37XhcPsw
提取码:91dt
效果
loss的下降趋势:

环境
pytorch=1.10.1
xlrd=1.2.0
步骤
1.准备数据
其中目录结构为:
所有代码都在train.py中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UhS7ZzLM-1645973735995)(D:/FeiYang/AppData/Typora/Figure/image-20220227224257043.png)]](https://img-blog.csdnimg.cn/7b674200887b43edbad6769385ab96ac.png)
def get_readings():
book = xlrd.open_workbook('./data/article_readings.xlsx')
sheet1 = book.sheet_by_name('sheet1')
cols = sheet1.col_values(1)
readings = []
for i in range(8, len(cols)):
pre_days = []
for j in range(i - 7, i):
pre_days.append(int(cols[j]))
pre_days.append(int(cols[i]))
readings.append(pre_days)
return readings
2.定义网络
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(7, 16, bias=True),
nn.ReLU(),
nn.Linear(16, 32, bias=True),
nn.ReLU(),
nn.Linear(32, 1, bias=True)
)
self.optimizer = torch.optim.Adam(self.fc.parameters(), lr=LR) # LR是在外部定义的,也可以作为参数传入网络
self.loss_fn = nn.MSELoss()
def forward(self, input):
return self.fc(input)
3.定义训练方法
def train(model: MyNet, readings: list[[int, int]]):
loss_list = [] # matplotlib作图用,记录每一次的损失值
for reading in readings:
predict = torch.tensor(reading[:7], dtype=torch.float) # reading[:7] 索引0~6的是前7天的数据,因为是列表,所以不用resize
predict = model(predict)
target = reading[7]
target = torch.tensor(target, dtype=torch.float)
target = torch.unsqueeze(target, 0) # 在target的第一维增加一个维度,原本的size是(1, ),增加后变为(1, 1)
loss = model.loss_fn(target, predict) # 计算损失值,损失函数用的是均方误差
loss_list.append(loss.item())
model.optimizer.zero_grad()
loss.backward()
model.optimizer.step() # 更新参数
return loss_list
4.预测
def predict(model: MyNet, pre_reading) -> int:
pre_reading = torch.tensor(pre_reading, dtype=torch.float)
pre_reading
out = model(pre_reading).item()
return int(out)
train.py
__main__中epoch是要自己设定的,如果你有大量的数据可以随机取出,像文章中数据太少,大了很容易过拟合。
import random
import torch.optim
import xlrd
import torch.nn as nn
import matplotlib.pyplot as plt
LR = 0.01
def get_readings():
book = xlrd.open_workbook('./data/article_readings.xlsx')
sheet1 = book.sheet_by_name('sheet1')
cols = sheet1.col_values(1)
readings = []
for i in range(8, len(cols)):
pre_days = []
for j in range(i - 7, i):
pre_days.append(int(cols[j]))
pre_days.append(int(cols[i]))
readings.append(pre_days)
return readings
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(7, 16, bias=True),
nn.ReLU(),
nn.Linear(16, 32, bias=True),
nn.ReLU(),
nn.Linear(32, 1, bias=True)
)
self.optimizer = torch.optim.Adam(self.fc.parameters(), lr=LR)
self.loss_fn = nn.MSELoss()
def forward(self, input):
return self.fc(input)
def train(model: MyNet, readings: list[[int, int]]):
loss_list = []
for reading in readings:
predict = torch.tensor(reading[:7], dtype=torch.float)
# predict = torch.unsqueeze(predict, 0)
predict = model(predict)
target = reading[7]
target = torch.tensor(target, dtype=torch.float)
target = torch.unsqueeze(target, 0)
loss = model.loss_fn(target, predict)
loss_list.append(loss.item())
model.optimizer.zero_grad()
loss.backward()
model.optimizer.step()
return loss_list
def predict(model: MyNet, pre_reading) -> int:
pre_reading = torch.tensor(pre_reading, dtype=torch.float)
pre_reading
out = model(pre_reading).item()
return int(out)
if __name__ == "__main__":
model = MyNet()
readings = get_readings()
print(readings)
pre_reading = readings[random.randint(0, len(readings))]
real_reading = pre_reading[-1]
loss_list_y = []
epoch = 200 # 注意,这里的epoch是偏大的,因为数据量太小了,所以必然是过拟合的
for i in range(epoch):
loss_list_y.extend(train(model, readings))
print('train done!')
loss_list_x = [i + 1 for i in range(len(loss_list_y))]
plt.plot(loss_list_x, loss_list_y)
plt.show()
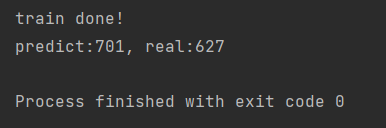
print(f'predict:{predict(model, pre_reading[:7])}, real:{real_reading}')















 4128
4128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









