







目录
1) 首先将 USB 摄像头插入到 Orange Pi 开发板的 USB 接口中
2) 然后通过 lsmod 命令可以看到内核自动加载了下面的模块
3) 通过 v4l2-ctl 命令可以看到 USB 摄像头的设备节点信息为/dev/video0
b . 安装完 fswebcam 后可以使用下面的命令来拍照 a)
c. 在服务器版的 linux 系统中,拍完照后可以使用 scp 命令将拍好的图片传到 Ubuntu PC 上镜像观看(这里直接使用FTP拖出去)
6) 使用 mjpg-streamer 测试 USB 摄像头
使用shell之bash解释器执行(目的是为了简化,不在到指定的目录下面去执行文件)
5.修改代码(uartTool.c)刷抖音项目的文件来修修改改,对应的头文件uartTool.h也要修改
main.c里面的pget_socket线程里面的功能是实现
一、阿里云平台垃圾分类接入
1、首先我们要通过调用阿里云|达摩院视觉智能开放平台 (aliyun.com)里面的垃圾分类平台来对垃圾进行识别
2、输入垃圾分类技术文档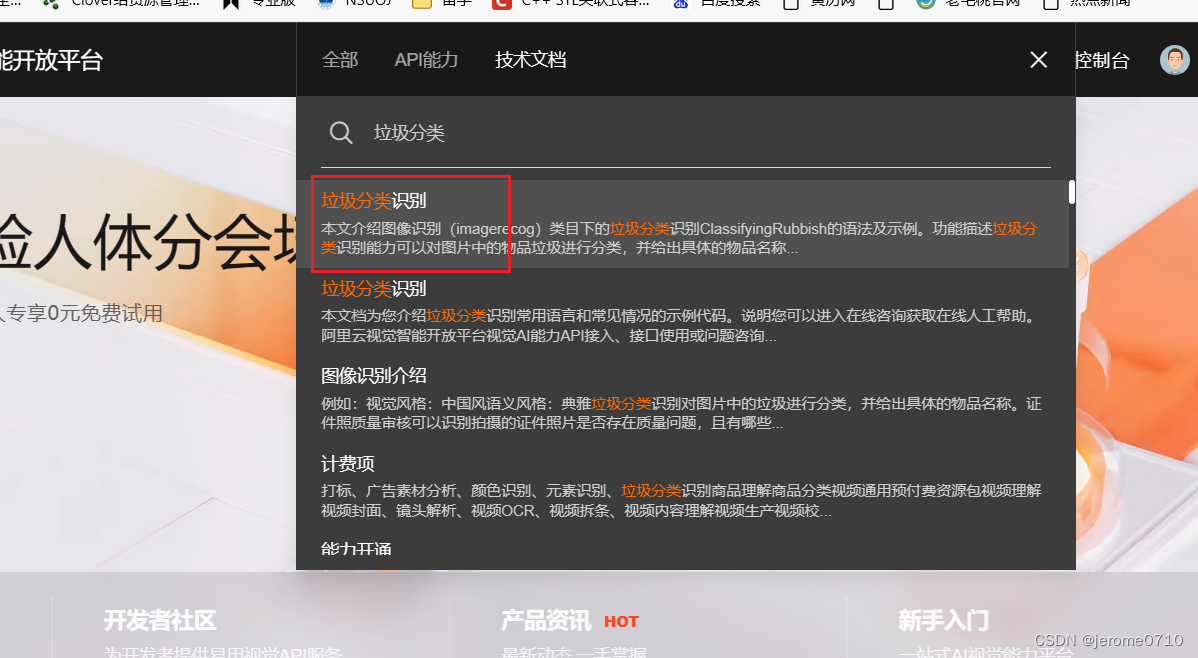
3、根据以下的技术文档的指引一步一步的操作
(这里说一下什么是AccessKey,它是一个账号用来与阿里云平台进行交互的,通过这个账号把图片传入到创建的阿里云账号里面,再调用对应的功能来进行识别)

4、参考6中的示例代码进行测试

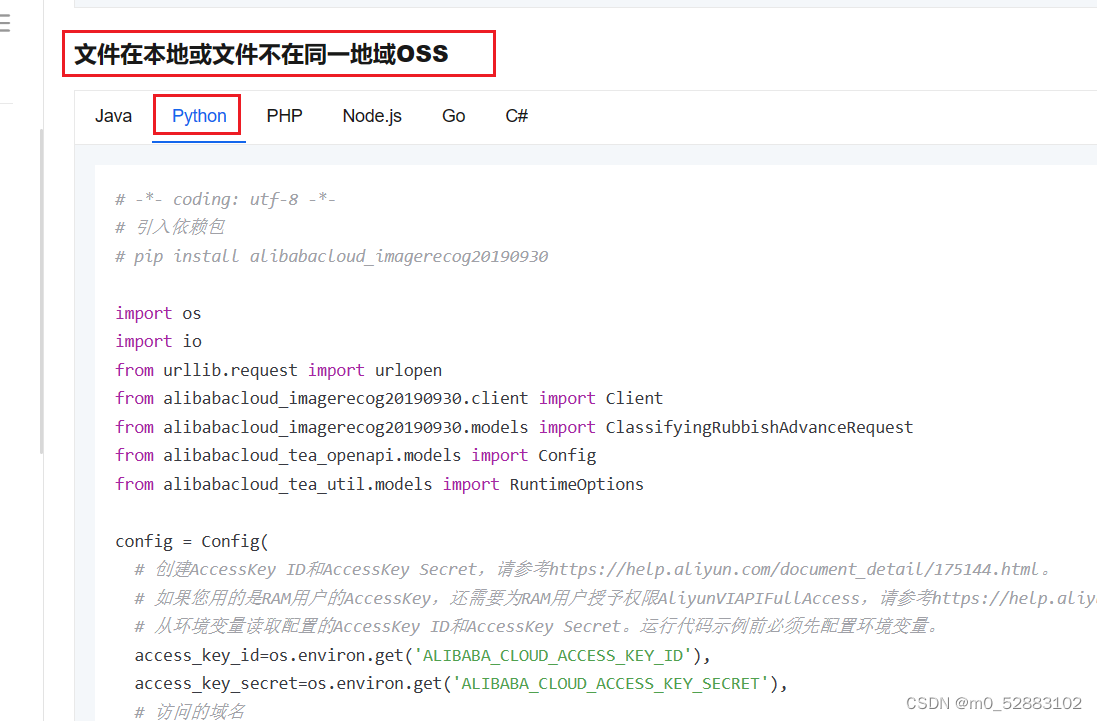
# -*- coding: utf-8 -*-
2 # 引入依赖包
3 # pip install alibabacloud_imagerecog20190930
4
5 import os
6 import io
7 from urllib.request import urlopen
8 from alibabacloud_imagerecog20190930.client import Client
9 from alibabacloud_imagerecog20190930.models import ClassifyingRubbishAdvanceRequest
10 from alibabacloud_tea_openapi.models import Config
11 from alibabacloud_tea_util.models import RuntimeOptions
12
13 config = Config(
14 # 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
15 # 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html
16 # 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
17 access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
18 access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
19 # 访问的域名
20 endpoint='imagerecog.cn-shanghai.aliyuncs.com',
21 # 访问的域名对应的region
22 region_id='cn-shanghai'
23 )
24 #场景一:文件在本地
25 img = open(r'/home/orangepi/Pictures/garbageCategory/guazike.jpg', 'rb')
26 #场景二:使用任意可访问的url
27 #url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/imagerecog/ClassifyingRubbish/ClassifyingRubbish1.jpg'
28 #img = io.BytesIO(urlopen(url).read())
29 classifying_rubbish_request = ClassifyingRubbishAdvanceRequest()
30 classifying_rubbish_request.image_urlobject = img
31 runtime = RuntimeOptions()
32 try:
33 # 初始化Client
34 client = Client(config)
35 response = client.classifying_rubbish_advance(classifying_rubbish_request, runtime)
36 # 获取整体结果
37 print(response.body)
except Exception as error:
39 # 获取整体报错信息
40 print(error)
41 # 获取单个字段
42 print(error.code)
~ 5、将其复制到OrangePi上面进行测试
a.首先测试的时候要关闭url,因为目前只是在本地进行测试
b.本地测试要修改图片的绝对路径 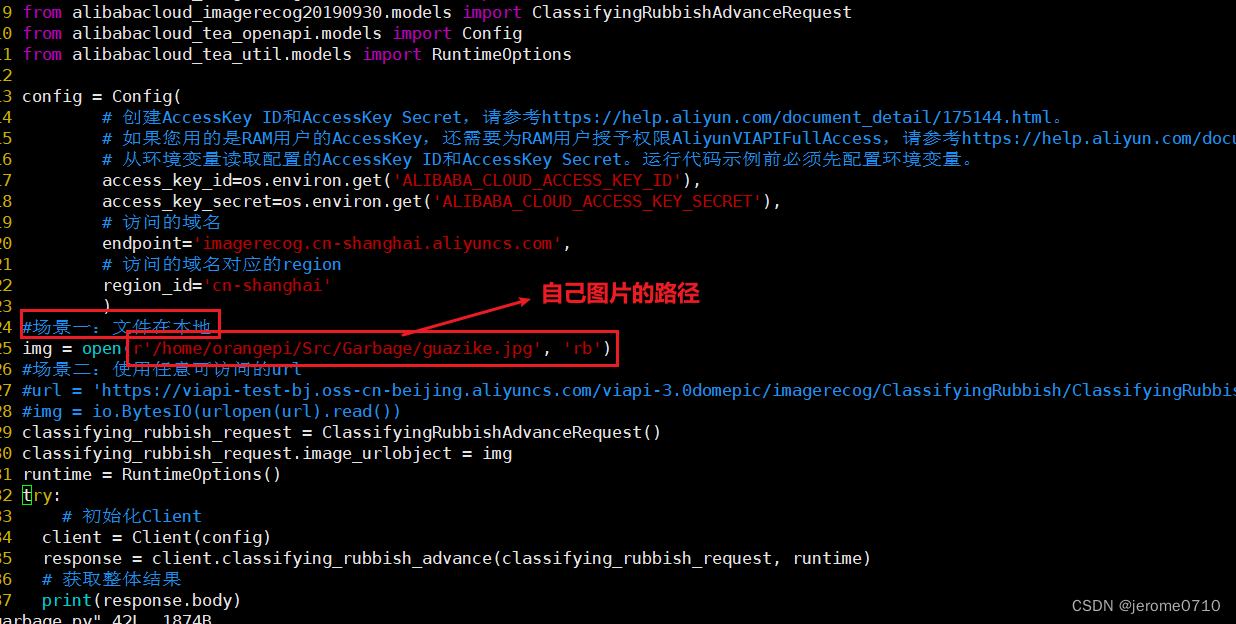
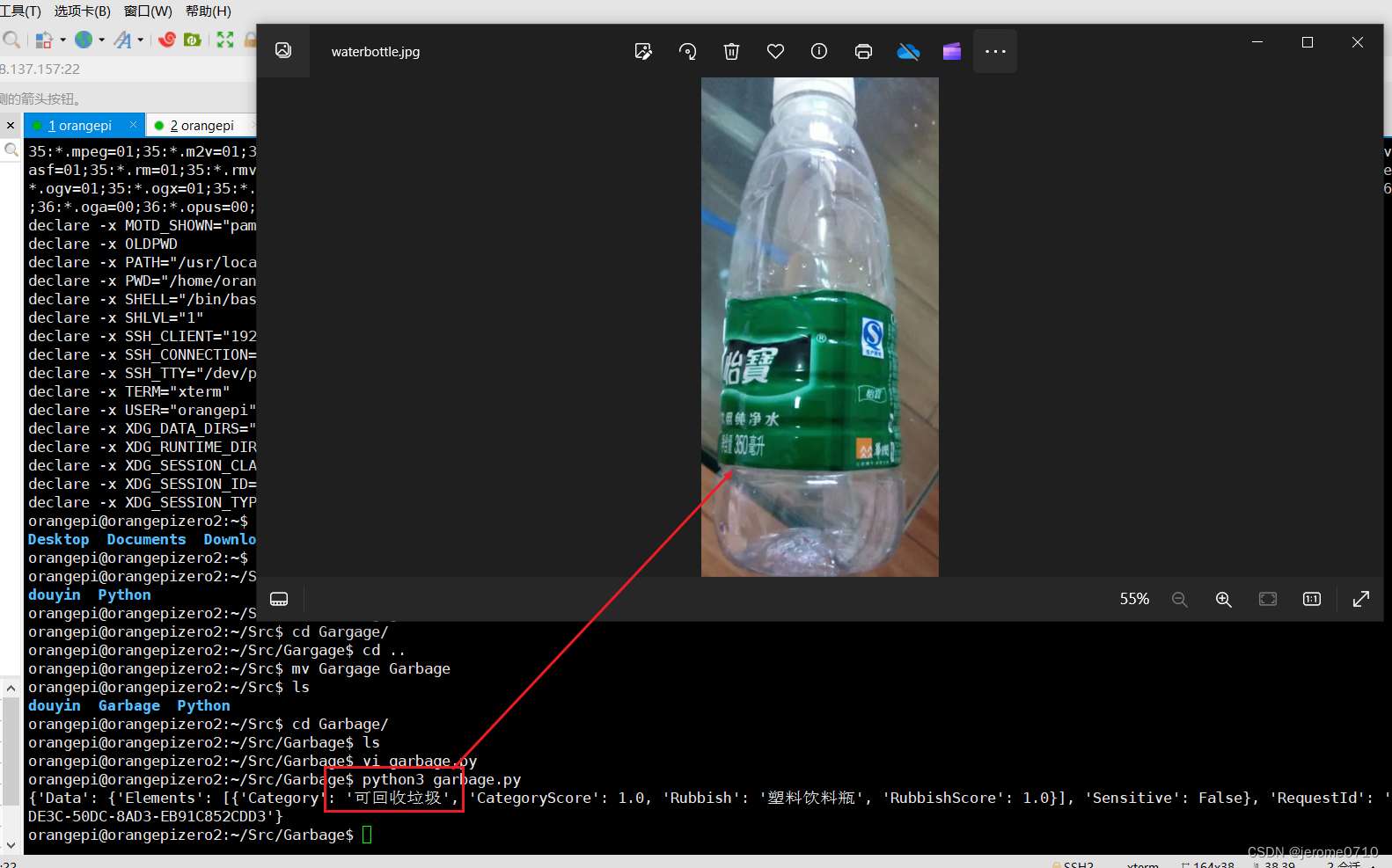
测试结果:
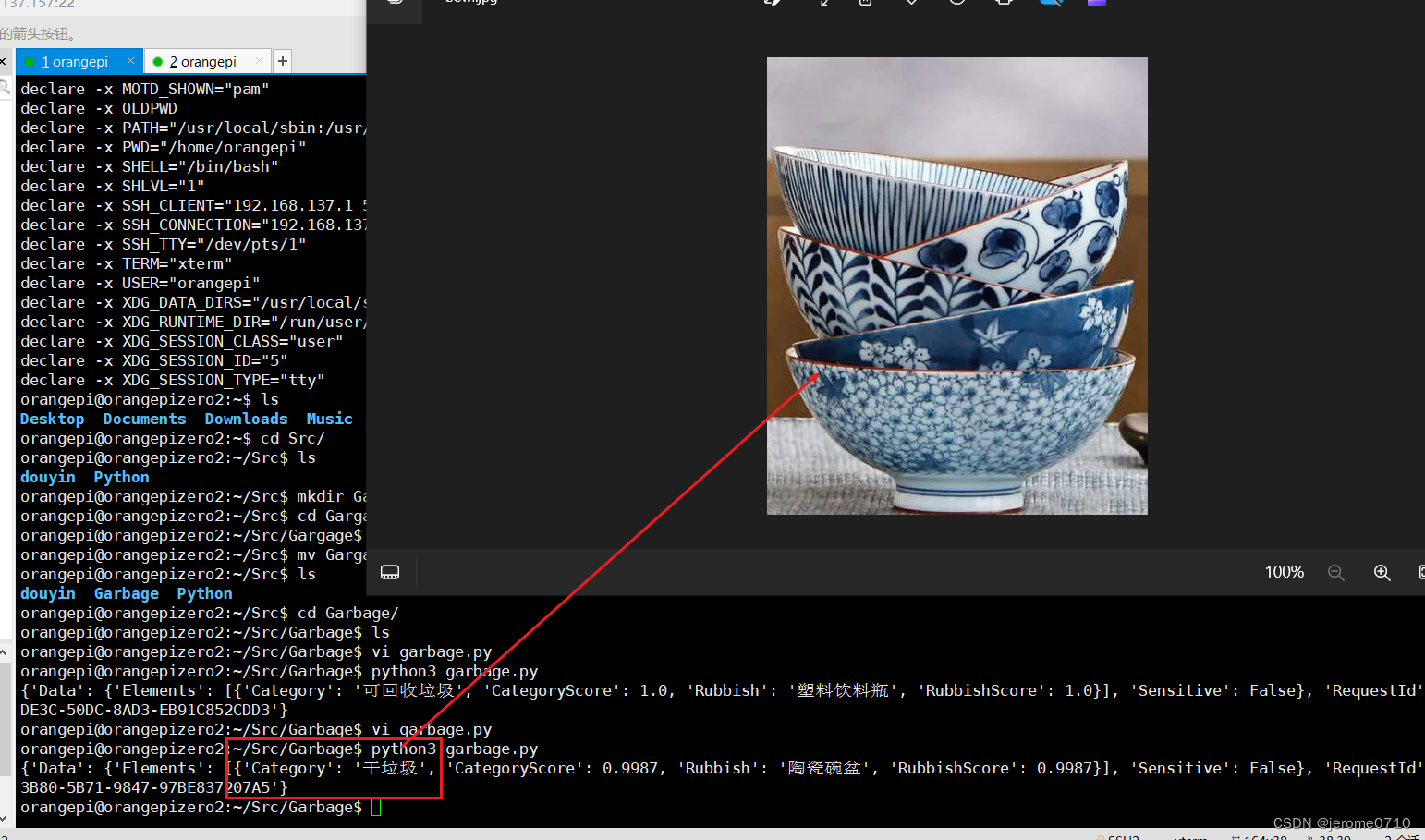 -------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------
二、用C语言调用阿里云Python的接口
1.首先将阿里云自启动
也就是首先配置环境变量,每次开机或者关闭终端时都要重新配置环境变量,所以就设置配置文件在一开机就先启动它
a.使用 vi Linux的~/.bashrc文件介绍-CSDN博客 ~/.bashrc 命令 Linux的~/.bashrc文件介绍-CSDN博客
b.
export ALIBABA_CLOUD_ACCESS_KEY_ID=“你的ID” #根据自己实际的ID填写
export ALIBABA_CLOUD_ACCESS_KEY_SECRET="你的SECRET"
c.再使用export命令查看是否显示,有显示则说明配置成功,打开新终端也能够自启动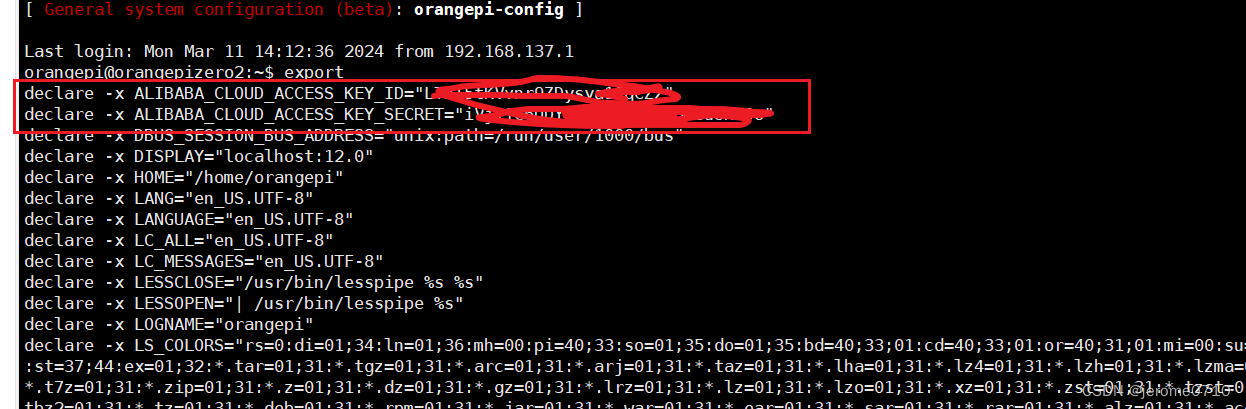
2.封装函数,方便C语言调用
将阿里云的代码封装成一个函数,方便后续用C语言进行调用
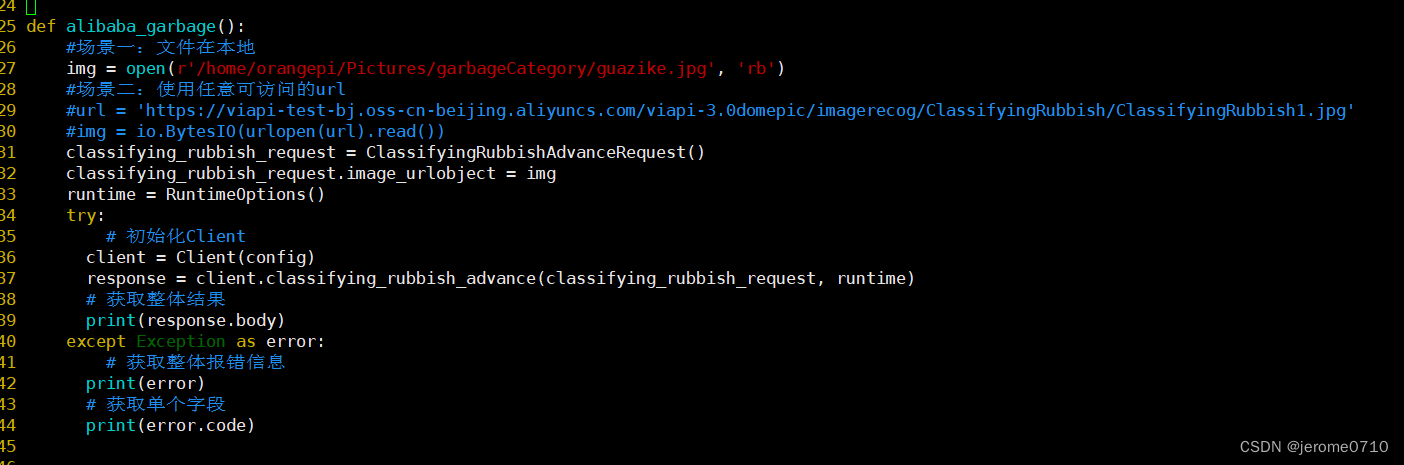


测试类的结果,结果为 ClassifyingRubbishResponseBody 这个类
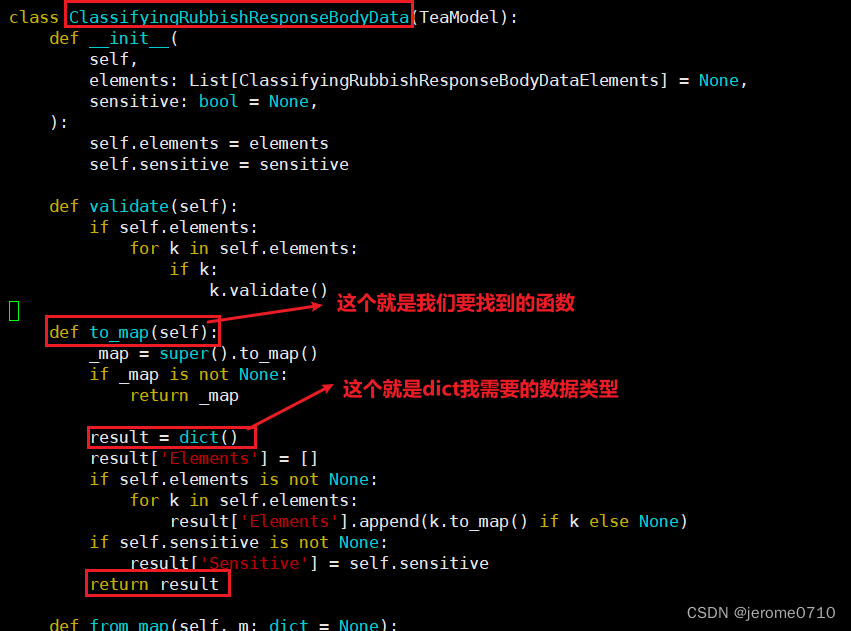
所以接下来我们要查找查找有什么函数或者方法能够把这些数据转换成dict数据类型
在安装图像的地方查找 输入:pip install alibabacloud_imagerecog20190930
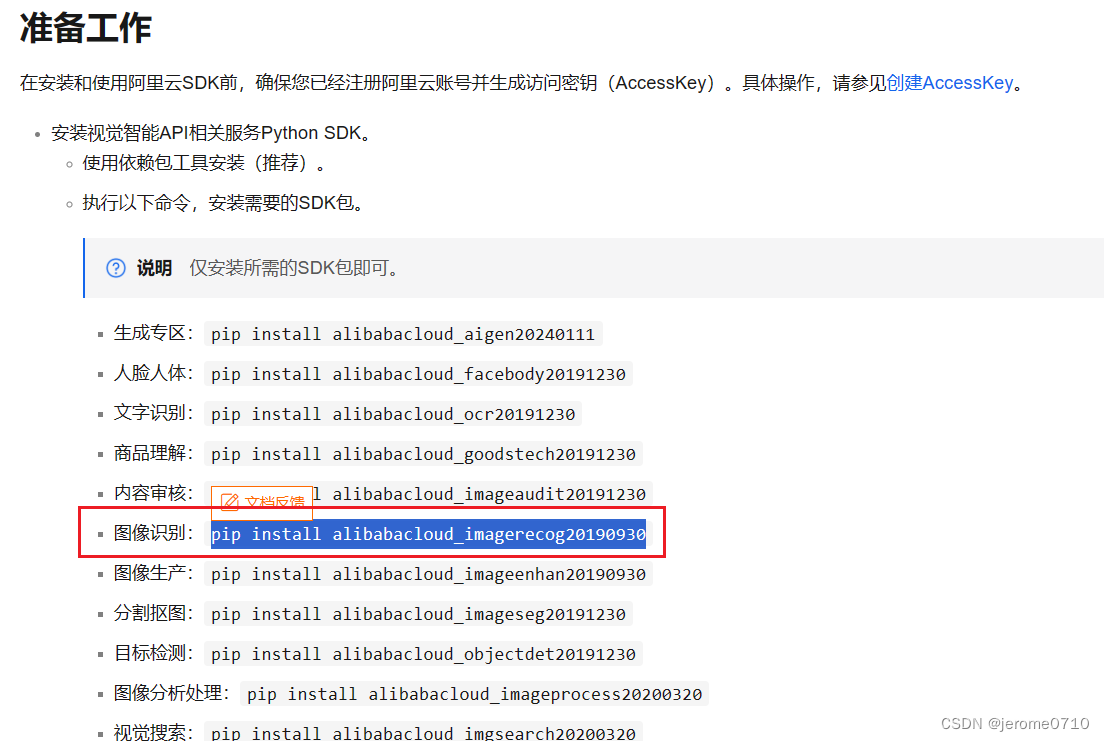
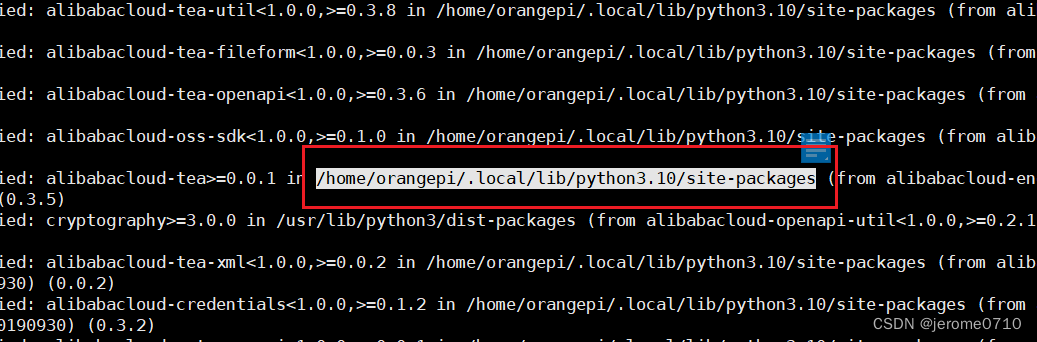
也就是查找alibaba的SDK包具体安装在Linux系统的哪个位置
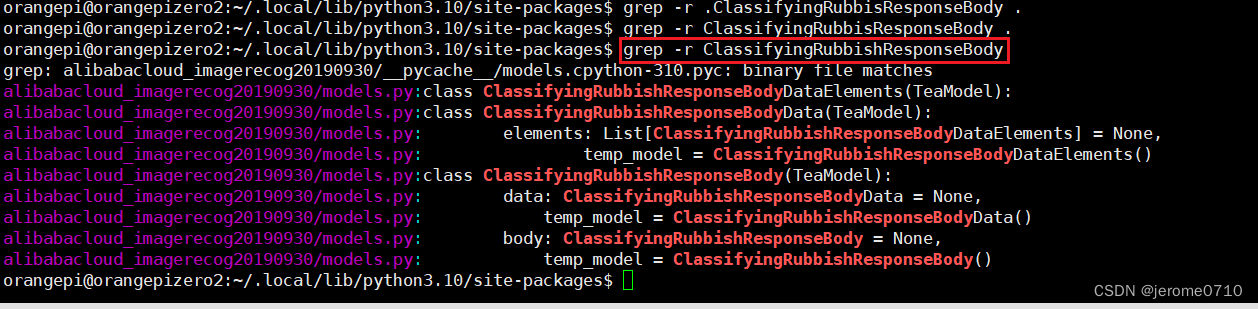
在该目录下查找我们刚才type出来的类 ,./alibabacloud_imagerecog20190930/models.py:class ClassifyingRubbishResponseBody(TeaModel):
这个类才是我们想要查找的类(完全重合)
使用vi 编辑器打开该类,然后看到我们想要的函数
在我们原本的.py文件里面修改打印出来的东西,看看是否能够打印出来dict数据类型
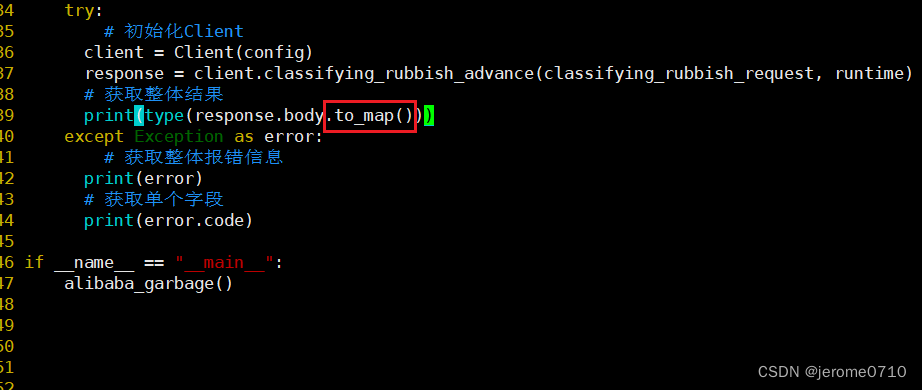
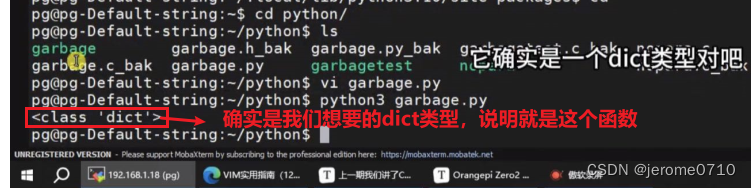
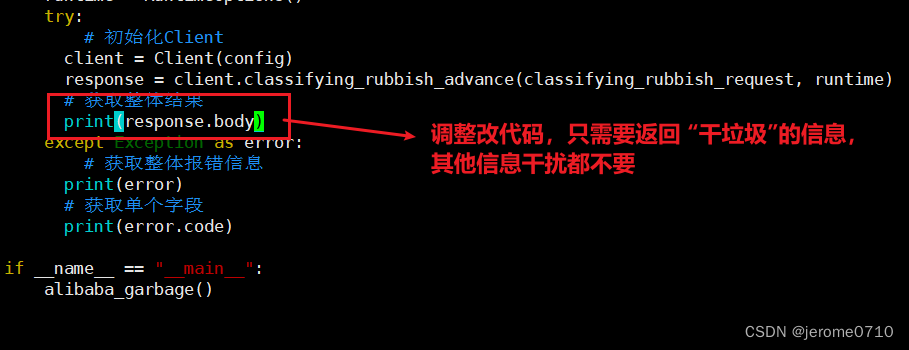
去除多余的信息,只保留关键的信息,这里就要使用Python里面的字典的方法



再次修改garbage.py文件,最终达到相应的效果
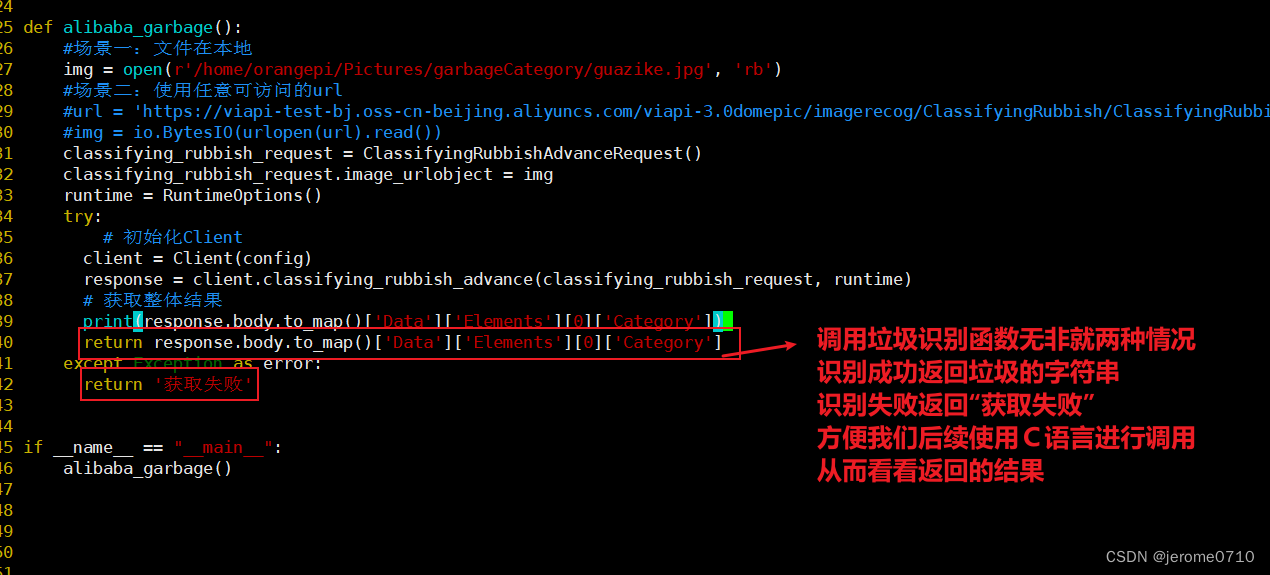
garbage.py
# -*- coding: utf-8 -*-
2 # 引入依赖包
3 # pip install alibabacloud_imagerecog20190930
4
5 import os
6 import io
7 from urllib.request import urlopen
8 from alibabacloud_imagerecog20190930.client import Client
9 from alibabacloud_imagerecog20190930.models import ClassifyingRubbishAdvanceRequest
10 from alibabacloud_tea_openapi.models import Config
11 from alibabacloud_tea_util.models import RuntimeOptions
12
13 config = Config(
14 # 创建AccessKey ID和AccessKey Secret,请参考https://help.aliyun.com/document_detail/175144.html。
15 # 如果您用的是RAM用户的AccessKey,还需要为RAM用户授予权限AliyunVIAPIFullAccess,请参考https://help.aliyun.com/document_detail/145025.html
16 # 从环境变量读取配置的AccessKey ID和AccessKey Secret。运行代码示例前必须先配置环境变量。
17 access_key_id=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_ID'),
18 access_key_secret=os.environ.get('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
19 # 访问的域名
20 endpoint='imagerecog.cn-shanghai.aliyuncs.com',
21 # 访问的域名对应的region
22 region_id='cn-shanghai'
23 )
24
25 def alibaba_garbage():
26 #场景一:文件在本地
27 img = open(r'/home/orangepi/Pictures/garbageCategory/guazike.jpg', 'rb')
28 #场景二:使用任意可访问的url
29 #url = 'https://viapi-test-bj.oss-cn-beijing.aliyuncs.com/viapi-3.0domepic/imagerecog/ClassifyingRubbish/ClassifyingRubbish1.jpg'
30 #img = io.BytesIO(urlopen(url).read())
31 classifying_rubbish_request = ClassifyingRubbishAdvanceRequest()
32 classifying_rubbish_request.image_urlobject = img
33 runtime = RuntimeOptions()
34 try:
# 初始化Client
36 client = Client(config)
37 response = client.classifying_rubbish_advance(classifying_rubbish_request, runtime)
38 # 获取整体结果
39 print(response.body.to_map()['Data']['Elements'][0]['Category'])
40 return response.body.to_map()['Data']['Elements'][0]['Category']
41 except Exception as error:
42 return '获取失败'
43
44
45 if __name__ == "__main__":
46 alibaba_garbage()
47
3、用C语言调用
使用之前的para.c文件修修改改

调用成功

修改函数 (garbage.py)


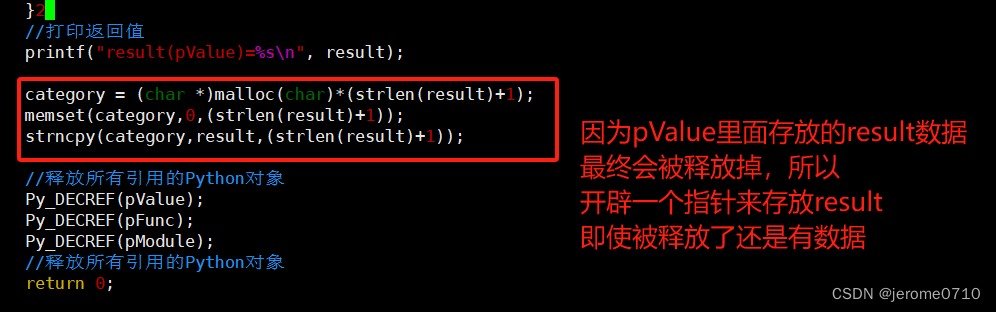
头文件的编写 )(garbage.h)

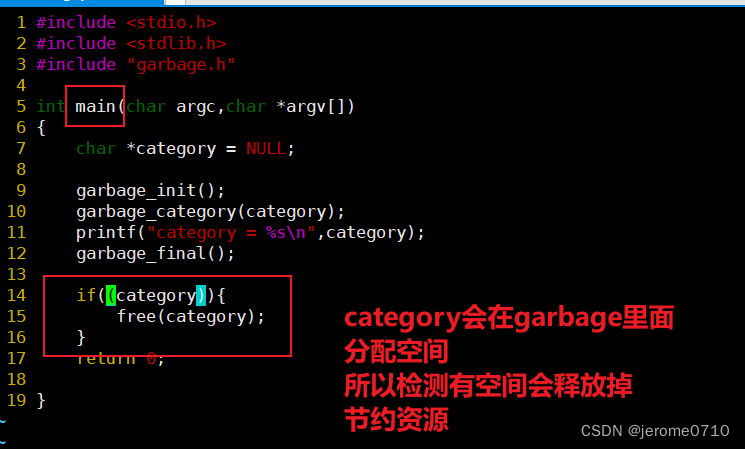
使用main函数进行调用(C文件)(garbage.c):

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









