






首先加载numpy库和pandas库及数据
import numpy as np
import pandas as pd
df=pd.read_csv('train.csv')
df.head(3)
数据清洗简述
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能继续做后面的分析或建模,所以拿到数据的第一步是进行数据清洗,本章我们将学习缺失值、重复值、字符串和数据转换等操作,将数据清洗成可以分析或建模的样子
缺失值观察与处理
缺失值观察
- 请查看每个特征缺失值个数
- 请查看Age, Cabin, Embarked列的数据
df.info()
df.isnull().sum()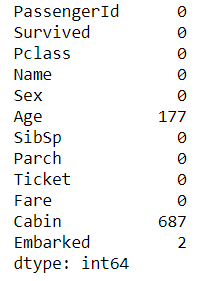
df[['Age','Cabin','Embarked']].head(3)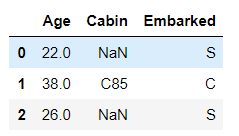
对缺失值进行处理
-
处理缺失值一般有几种思路
-
对Cabin列的数据的缺失值进行处理
-
不同的方法直接对整张表的缺失值进行处理
由前三行数据可以看出 Cabin列有两个缺失值,对其进行处理
df[df['Cabin']==None]=0
df.head(3)
df[df['Cabin'].isnull()] = 0
df.head(3)
df[df['Cabin'] == np.nan] = 0
df.head()
思考:检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
回答:数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan
df.dropna().head(3)
df.fillna(0).head(3)
重复值观察与处理
查看数据中的重复值
df[df.duplicated()]
对重复值进行处理
重复值有哪些处理方式,处理我们数据的重复值
df = df.drop_duplicates()
df.head()
前面清洗的数据保存为csv格式
df.to_csv('test_clear.csv')![]()
特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析
对年龄进行分箱(离散化)处理
-
分箱操作是什么?
-
将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
-
将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
-
将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
-
将上面的获得的数据分别进行保存,保存为csv格式
df['AgeBand'] = pd.cut(df['Age'], 5,labels = [1,2,3,4,5])
df.head()
保存为test_ave
df.to_csv('test_ave.csv')df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = [1,2,3,4,5])
df.head(3)
df.to_csv('test_cut.csv')df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = [1,2,3,4,5])
df.head()
df.to_csv('test_pr.csv')对文本变量进行转换
- 查看文本变量名及种类
- 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
- 将文本变量Sex, Cabin, Embarked用one-hot编码表示
查看文本变量名及种类,方法一
df['Sex'].value_counts()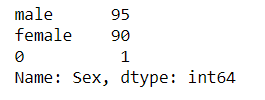
df['Cabin'].value_counts()
df['Embarked'].value_counts()
方法二
df['Sex'].unique()![]()
df['Sex'].nunique(2
将类别文本转换为12345,方法一
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
df.head()
方法二
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
df.head()















 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









