






Linux系统问题
Ubuntu报错:“E:无法定位软件包”
解决:更新软件源
sudo apt-get update无法获得锁
解决:
方法一:使用ps aux命令,直接kill掉锁死的进程
方法二:强制解锁
把进程锁的缓存文件删除
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lockVMware Tools无法在Windows和Linux系统间复制粘贴文件
解决:
(1)卸载VMwareTools
sudo apt-get autoremove open-vm-tools(2)联网安装到桌面
sudo apt-get install open-vm-tools-desktop(3)重启
安装包
tensorboardX
tensorboard
scikit-learn >= 0.22.2
seqeval
pyahocorasick
scipy
statsmodels
biopython
pandas
pybedtools
sentencepiece==0.1.91
报错:zlib.h:没有那个文件或目录
解决:安装zlib包
sudo apt-get install zlib1g-dev报错:
ERROR: Directory './' is not installable. Neither 'setup.py' nor 'pyproject.toml' found.
apex安装未成功
报错:
03/23/2023 23:05:15 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False
Traceback (most recent call last):
File "/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/configuration_utils.py", line 225, in get_config_dict
raise EnvironmentError
OSError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "run_pretrain.py", line 885, in <module>
main()
File "run_pretrain.py", line 781, in main
config = config_class.from_pretrained(args.config_name, cache_dir=args.cache_dir)
File "/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/configuration_utils.py", line 176, in from_pretrained
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
File "/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/configuration_utils.py", line 241, in get_config_dict
raise EnvironmentError(msg)
OSError: Model name 'PATH_TO_DNABERT_REPO/src/transformers/dnabert-config/bert-config-6/config.json' was not found in model name list. We assumed 'https://s3.amazonaws.com/models.huggingface.co/bert/PATH_TO_DNABERT_REPO/src/transformers/dnabert-config/bert-config-6/config.json/config.json' was a path, a model identifier, or url to a configuration file named config.json or a directory containing such a file but couldn't find any such file at this path or url.解决:
更改路径
--config_name=/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/dnabert-config/bert-config-$KMER/config.json \ --output_dir $OUTPUT_PATH \
--model_type=dna \
--tokenizer_name=dna$KMER \
--config_name=/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/dnabert-config/bert-config-$KMER/config.json \
--do_train \
--train_data_file=$TRAIN_FILE \
--do_eval \
--eval_data_file=$TEST_FILE \
--mlm \
--gradient_accumulation_steps 25 \
--per_gpu_train_batch_size 10 \
--per_gpu_eval_batch_size 6 \
--save_steps 500 \
--save_total_limit 20 \
--max_steps 200000 \
--evaluate_during_training \
--logging_steps 500 \
--line_by_line \
--learning_rate 4e-4 \
--block_size 512 \
--adam_epsilon 1e-6 \
--weight_decay 0.01 \
--beta1 0.9 \
--beta2 0.98 \
--mlm_probability 0.025 \
--warmup_steps 10000 \
--overwrite_output_dir \
--n_process 24报错:
03/23/2023 23:24:11 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False
03/23/2023 23:24:11 - INFO - transformers.configuration_utils - loading configuration file /home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/dnabert-config/bert-config-6/config.json
03/23/2023 23:24:11 - INFO - transformers.configuration_utils - Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"do_sample": false,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_labels": 2,
"num_return_sequences": 1,
"num_rnn_layer": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pruned_heads": {},
"repetition_penalty": 1.0,
"rnn": "lstm",
"rnn_dropout": 0.0,
"rnn_hidden": 768,
"split": 10,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 4101
}
============================================================
<class 'transformers.tokenization_dna.DNATokenizer'>
Traceback (most recent call last):
File "run_pretrain.py", line 885, in <module>
main()
File "run_pretrain.py", line 789, in main
tokenizer = tokenizer_class.from_pretrained(args.tokenizer_name, cache_dir=args.cache_dir)
File "/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/tokenization_utils.py", line 377, in from_pretrained
return cls._from_pretrained(*inputs, **kwargs)
File "/home/zyp/project/DNABERT-master/DNABERT-master/src/transformers/tokenization_utils.py", line 479, in _from_pretrained
list(cls.vocab_files_names.values()),
OSError: Model name 'dna6' was not found in tokenizers model name list (dna3, dna4, dna5, dna6). We assumed 'dna6' was a path, a model identifier, or url to a directory containing vocabulary files named ['vocab.txt'] but couldn't find such vocabulary files at this path or url.OSError:在tokenizers模型名称列表(dna3, dna4, dna5, dna6)中没有找到模型名称“dna6”。我们假设'dna6'是一个路径、一个模型标识符或指向一个目录的url,该目录包含名为['vocab.txt']的词汇表文件,但在这个路径或url中找不到这样的词汇表文件。解决:
(1)查看transformers版本号:
pip list(2)更新transformers
pip install --upgrade transformers //有点慢,应该挂镜像报错消失
产生新的报错:
ImportError: cannot import name 'DNATokenizer'大概率路径问题
Ubuntu崩了,开机卡在 started gnome display manager,无法开机
参考:https://blog.csdn.net/qq_42680785/article/details/116195840
原因:磁盘空间已满或更新异常
解决:
(1)alt+ctrl+F6(18.04版本Ubuntu)
(2)检查磁盘空间
df -h文件系统 /dev/loopx 已用100%
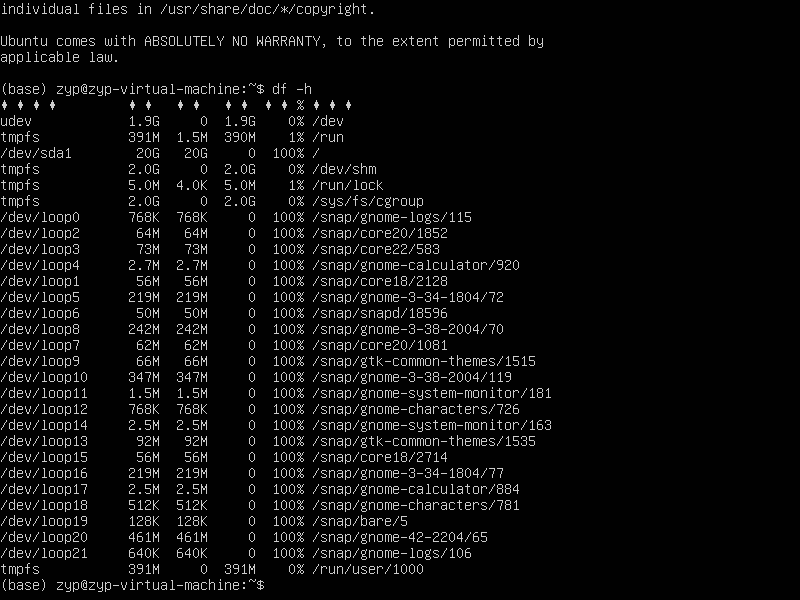
(3)清理磁盘空间
sudo apt autoremove --purge snapd(4)重启
(5)清理APT缓存
du -sh /var/cache/apt/archives
sudo apt-get clean














 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









