







 该博客介绍了一种利用Hadoop MapReduce框架对多个文件进行合并并去除重复内容的方法。通过自定义Mapper和Reducer类,Mapper将每行数据作为key输出,Reducer则负责去重。具体操作包括编写Java代码,打包成jar,将文件上传到HDFS,然后运行Hadoop命令执行任务,最终在指定目录下得到去重后的结果文件。
该博客介绍了一种利用Hadoop MapReduce框架对多个文件进行合并并去除重复内容的方法。通过自定义Mapper和Reducer类,Mapper将每行数据作为key输出,Reducer则负责去重。具体操作包括编写Java代码,打包成jar,将文件上传到HDFS,然后运行Hadoop命令执行任务,最终在指定目录下得到去重后的结果文件。
目录
一.问题描述
对输入的多个文件进行合并,并剔除其中重复的内容,去重后的内容输出到一个文件中。
主要思路:根据reduce的过程特性,会自动根据key来计算输入的value集合,把数据作为key输出给reduce,无论这个数据出现多少次,reduce最终结果中key只能输出一次。
1.实例中每个数据代表输入文件中的一行内容,map阶段采用Hadoop默认的作业输入方式。将value设置为key,并直接输出。 map输出数据的key为数据,将value设置成空值
2.在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会交给reduce
3.reduce阶段不管每个key有多少个value,它直接将输入的key复制为输出的key,并输出(输出中的value被设置成空)。用一行作为key,value是空,那么在reduce时进行“汇总”,还是只有一个key,即一行,value还是空。所以即去重了。
二.具体代码
package Test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class FileMerge {
//自定义Mapper类
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
// 新建Text类型对象,用来存放科目
private Text text = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
text = value;
context.write(text, new Text(""));
}
}
// 自定义Reducer类
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 新建配置类对象
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf,args)).getRemainingArgs();
if(otherArgs.length<2){
System.err.println("Usage:CrossTest <in> [..<in>] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf,"对两个文件中的数据进行合并与去重");
job.setJarByClass(FileMerge.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
for(int i = 0; i <otherArgs.length - 1;i++){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length -1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}三.具体操作
①将写好的java文件打包成jar包并上传到虚拟机中,这里用eclipse举例
右键写好的项目,点击export
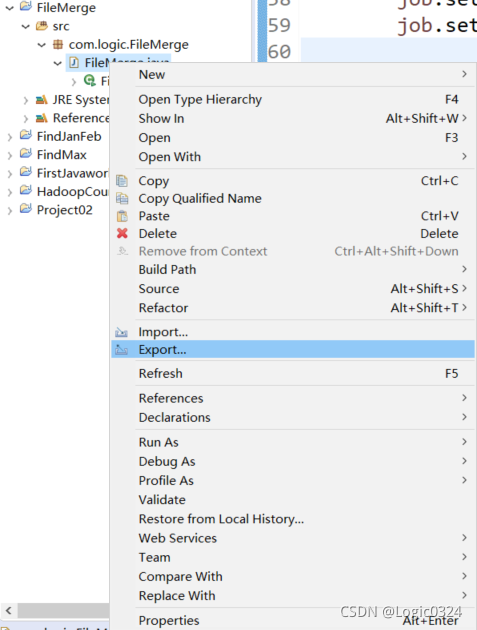
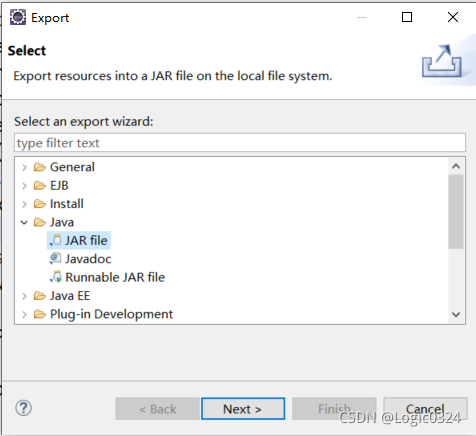
找到Java,双击打开,选择JAR file,点击next
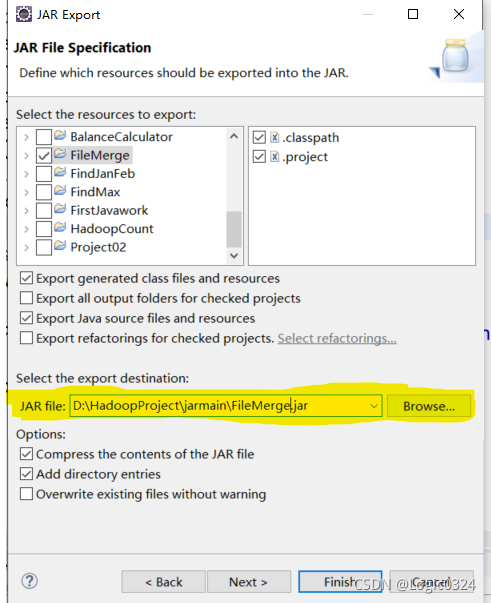
将要打成jar包的文件打钩,将Export generated class files and resources和Export Java source files and resources打钩,Options中的Comepress the contents of the JAR file和Add directitory entries也需要打钩,并选择存放jar包的路径(黄色高亮位置,最后的FileMerge.jar为jar包名称),点击finish即可生成jar包
②将需要去重的两个文件放入同一文件夹,上传至虚拟机并上传至hdfs目录
③执行命令
hadoop jar FileMerge.jar /user/root/xyz /user/root/zz其中FileMerge.jar根据自己打好的jar包名改动,/user/root/xyz为上传的需要去重的文件夹路径,/user/root/zz是hdfs要输出的目录。
④在hdfs目录系统中找到并查看结果

















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









