







文章目录
一、官方文件:
org.apache.hadoop.mapred (Apache Hadoop MapReduce Shuffle 3.3.1 API)
二、Shuffle在Map、Reduce两个阶段的主要作用
1.Mapper
每个MapperTask有一个环形内存缓冲区(环形缓冲区实质上是一个环形队列,环形队列是在实际编程极为有用的数据结构,它是一个首尾相连的FIFO的数据结构,采用数组的线性空间,数据组织简单,能很快知道队列是否满为空,能以很快速度的来存取数据。在MapOutputBuffer.init中创建。 ),用于存储map任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil.percent) ,一个后台线程把内容写到(spill)磁盘的指定自录(mapred.local.dir)下的新建的一个溢出写文件。
写磁盘前,要partition,sort,combiner。如果有后续的数据,将会继续写入环形缓冲区中,最终写入下一个溢出文件中。
等最后记录写完,合并全部溢出写文件为一个分区且排序的文件.
如果在最终合并时,被合并的文件大于等于3个,则合并完会再执行一次Combiner,否则不会。
2.Reducer
Reduce阶段启动 Fetcher 线程到已经完成 Map阶段 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。在 Reduce 阶段远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。在对数据进行合并的同时,会进行排序操作,由于 Map 阶段已经对数据进行了局部的排序,Reduce阶段只需保证 Copy 的数据的最终整体有效性即可。
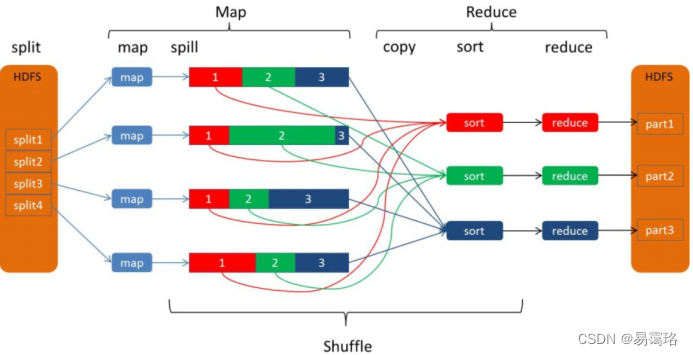

map输出–>缓存区(buffer,默认100M)–>partition(在buffer标记) -->sort(将kv对的元数据进行排序,依然是在buffer内进行)–>spill(条件为buffer中的数据达到80%,即0.8时,开始溢写)到本地磁盘,产生溢写文件,将同一分区的数据聚集(此时数据是排序状态) -->n个溢写文件merge成一个文件–>fetch(reduce端的线程通过Http协议复制当前reduceTask要处理的分区数据,先复制到缓存,再根据缓存大小来决定是否产生文件)–>merge(reduce端会合并多个文件,最后一次合并不产生文件,直接在内存中输入reduce)
三、解析各个类以及其方法的具体作用
一、FadvisedChunkedFile
作用:发出在给定文件描述符上读取头条的请求。
二、FadvisedFileRegion
作用:传输数据。它将数据从磁盘传输到内存中的本地缓冲区,然后将数据从缓冲区传输到给定的字节通道。
三、ShuffleHandler
1.ShuffleMetrics
作用:统计失败的和成功的shuffle输出的数量
2.ReduceMapFileCount
方法:operationComplete(ChannelFuture future)
作用:统计正在等待的map数量并对其进行不同的操作,调用了sendMap(ReduceContext reduceContext)方法
3.ReduceContext
作用:维护每个 messageReceived() Netty 上下文的参数。允许来自 operationComplete() 的 sendMapOutput 调用
4.TimeoutHandler
作用:超时处理程序,如果超时则关闭连接
5.HttpPipelineFactory
-
方法1:HttpPipelineFactory(Configuration conf, Timer timer)
作用:创建一个sslFactory并添加相关配置和初始化,设置闲置状态处理程序 -
方法2:getPipeline()
作用:添加SSL引擎,Http请求解码器,Http块聚合器,Http响应编码器,块写入处理程序,shuffle,空闲状态处理程序,超时处理程序到pipeline
6.Shuffle
- 方法1:Shuffle(Configuration conf)
作用:shuffle的配置信息 - 方法2:setPort(int port)
作用:创建接口 - 方法3:splitMaps(List mapq)
作用:对map进行切割 - 方法4:channelOpen(ChannelHandlerContext ctx, ChannelStateEvent evt)
作用:将此时通道状态事件的通道添加到channel集群中 - 方法5:messageReceived(ChannelHandlerContext ctx, MessageEvent evt)
作用:验证http请求,填充标题,将http响应写入事件通道中,并调用sendMap(reduceContext)方法 - 方法6:sendMap(ReduceContext reduceContext)
作用:获取map输出的分区或者分块 - 方法7:getErrorMessage(Throwable t)
作用:获取错误信息 - 方法8:getBaseLocation(String jobId, String user)
作用:获取用户程序的基本位置,其中包含用户缓存,应用程序缓存以及应用程序的id - 方法9:getMapOutputInfo(String mapId, int reduce, String jobId, String user)
作用:获取map输出的信息 - 方法10:populateHeaders(List mapIds, String jobId,String user, int reduce, HttpRequest request, HttpResponse response,boolean keepAliveParam, Map<String, MapOutputInfo> mapOutputInfoMap)
作用:将map输出信息放入mapOutputInfoMap,将数据缓冲区该对象写入header
7.AttemptPathInfo
作用:将存储路径更改为仅存储本地目录索引,而不是整个路径,效率更高。
8.AttemptPathIdentifier
- 方法1:hashCode()
作用:哈希码的转换 - 方法2:toString()
作用:字符串的转换 - 方法3:equals(Object o)
9.MapOutputInfo
作用:获取map端输出的文件名以及索引记录
-
方法1:serializeMetaData(int port)
作用:将 shuffle 端口序列化为 ByteBuffer 以备后用。返回端口的序列化形式。 -
方法2:deserializeMetaData(ByteBuffer meta)
作用:用于反序列化 ShuffleHandler 返回的元数据的辅助函数。返回Shuffle Handler 监听的端口以提供 shuffle 数据。 -
方法3:serializeServiceData(Token jobToken)
作用:一个辅助函数,用于序列化 JobTokenIdentifier 作为 ServiceData 发送到 ShuffleHandler。返回jobToken 的序列化版本。 -
方法4:deserializeServiceData(ByteBuffer secret)
作用:用于反序列化 -
方法5:initializeApplication(ApplicationInitializationContext context)
作用:初始化应用程序,获取新的jobid并将其记录 -
方法6:stopApplication(ApplicationTerminationContext context)
作用:终止应用程序 -
方法7:serviceInit(Configuration conf)
作用:服务初始化 -
方法8:serviceStart()
方法:将shuffle端口添加至channel集群,并在HttpPipelineFactory建立shuffle端口 -
方法9:serviceStop()
作用:服务终止,取消注册源 -
方法10:getMetaData()
作用:获取元数据 -
方法11:recoverState(Configuration conf)
作用:恢复状态,并调用startStore(Path recoveryRoot)方法 -
方法12:startStore(Path recoveryRoot)
作用:打开数据库文件检查其版本,若本地数据库不存在则创建新的数据库 -
方法13:loadVersion()
作用:获取当前版本,如果先前未存储版本,则将其视为当前版本信息。 -
方法14:storeSchemaVersion(Version version)
作用:将状态架构数据库的版本KEY值以及版本信息存入状态数据库中 -
方法15:checkVersion()
作用:检查加载版本与当前版本是否兼容,若兼容则调用storeVersion()方法存储该版本信息 -
方法16:addJobToken(JobID jobId, String user,Token jobToken)
作用:添加一个用户和jobId至用户资源,并为该jobId添加一个jobToken(jobToken 用于身份验证 Shuffle 数据请求的工作令牌。) -
方法17:recoverJobShuffleInfo(String jobIdStr, byte[] data)
作用:对获取的jobId进行判断,若可用则添加至用户资源中 -
方法18:recordJobShuffleInfo(JobID jobId, String user,Token jobToken)
作用:记录jobId的信息,并将其添加至状态数据库,并调用addJobToken(jobId, user, jobToken) -
方法19:removeJobShuffleInfo(JobID jobId)
作用:在用户资源中删除该jobId,并在状态数据库中删除jobId -
方法20:setResponseHeaders(HttpResponse response,boolean keepAliveParam, long contentLength)
作用:设置响应头 -
方法21:sendMapOutput(ChannelHandlerContext ctx, Channel ch, String user, String mapId, int reduce, MapOutputInfo mapOutputInfo)
作用:对map输出文件进行读操作,若当前channel为空则调用FadvisedFileRegion类,否则调用FadvisedChunkedFile类 -
方法22:exceptionCaught(ChannelHandlerContext ctx, ExceptionEvent e)
作用:异常捕获
四、大致思路
-
initializeApplication()初始化应用程序通过appid获取新的jobid后调用recordJobShuffleInfo()记录jobid的信息,在recordJobShuffleInfo()中调用addJobToken()添加一个user和jobId至用户资源,并为该jobId添加一个jobToken
-
serviceStart()先调用recoverState(conf)先获取恢复路径,若不为空则调用startStore(recoveryRoot)若本地数据库不存在则先创建数据库再打开并调用storeVersion()储存其版本信息,若存在则打开数据库文件再调用checkVersion()检查加载版本与当前版本是否兼容,若兼容则调用storeVersion()方法存储该版本信息。再对jobid的key值在数据库中进行迭代,若有与之匹配的key则调用recoverJobShuffleInfo()对新获取的jobid进行判断,若可用则添加至用户资源中。将shuffle端口添加至channel集群,并在HttpPipelineFactory建立shuffle端口
-
Reduce端发来http请求之后,在messageReceived()中先调用verifyRequest()对http进行验证,再调用populateHeaders()填充标题,在populateHeaders()中调用setResponseHeaders()设置响应头。再调用sendMap(),在sendMap()中调用sendMapOutput()获取map输出的分区或者分块,即对map的输出文件进行读操作,并判断channel是否为空,若为空则对map输出文件进行传输,若不为空则对通道中的文件发起读取头条的请求。
五、优化策略
- 如果能估算map输出大小,就可以合理设置该值来尽可能减少溢出写的次数
- 如果map输出的数据量非常大,写入磁盘时压缩数据,因为这样会让写磁盘的速度更快,节约磁盘空间,并且减少传给reducer的数据量。
- 减少不必要的排序:并不是所有类型的Reduce需要的数据都是需要排序的,排序这个nb的过程如果不需要最好还是不要的好
- 调用reduce之前,map必须完成的最少比例
- reducer在copy阶段同时从mapper上拉取的文件数
















 1298
1298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











