






 本文介绍了一款利用Python网络爬虫抓取中国天气网数据,通过ECharts进行可视化分析的系统。系统包括数据采集、全国天气及历史数据可视化、多元线性回归预测模型和用户/数据管理功能,为气象研究提供实用且有价值的数据资源。
本文介绍了一款利用Python网络爬虫抓取中国天气网数据,通过ECharts进行可视化分析的系统。系统包括数据采集、全国天气及历史数据可视化、多元线性回归预测模型和用户/数据管理功能,为气象研究提供实用且有价值的数据资源。
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
1、摘 要
随着气候变化的不断加剧,气象数据的准确性和时效性变得愈发重要。本论文介绍了一个基于Python网络爬虫技术的天气数据自动获取与可视化分析系统,该系统可以自动地从中国天气网获取实时天气数据,并将数据清洗、存储在MYSQL数据库中。同时,通过ECharts技术实现数据可视化,在大屏幕上实现了全国综合天气数据可视化,以及全国各城市和上海历史天气数据的可视化。其次,系统还实现了机器学习预测天气模型构建与训练,使用scikit-learn、pandas、numpy等工具实现多元线性回归模型。预测模型可以对天气趋势进行分析,提供预测结果。此外,该系统还实现了用户登录和注册功能,以及数据管理模块,用于管理用户数据、公告数据、全国天气数据和上海历史气象数据。
总的来说,本系统实现了数据的自动获取和处理,提供了可视化的天气数据分析和预测模型,并具有用户管理和数据管理功能。这个系统不仅具有很高的实用价值,同时也为未来的气象数据研究提供了一个有价值的数据源。
关键字:可视化;Python;网络爬虫;天气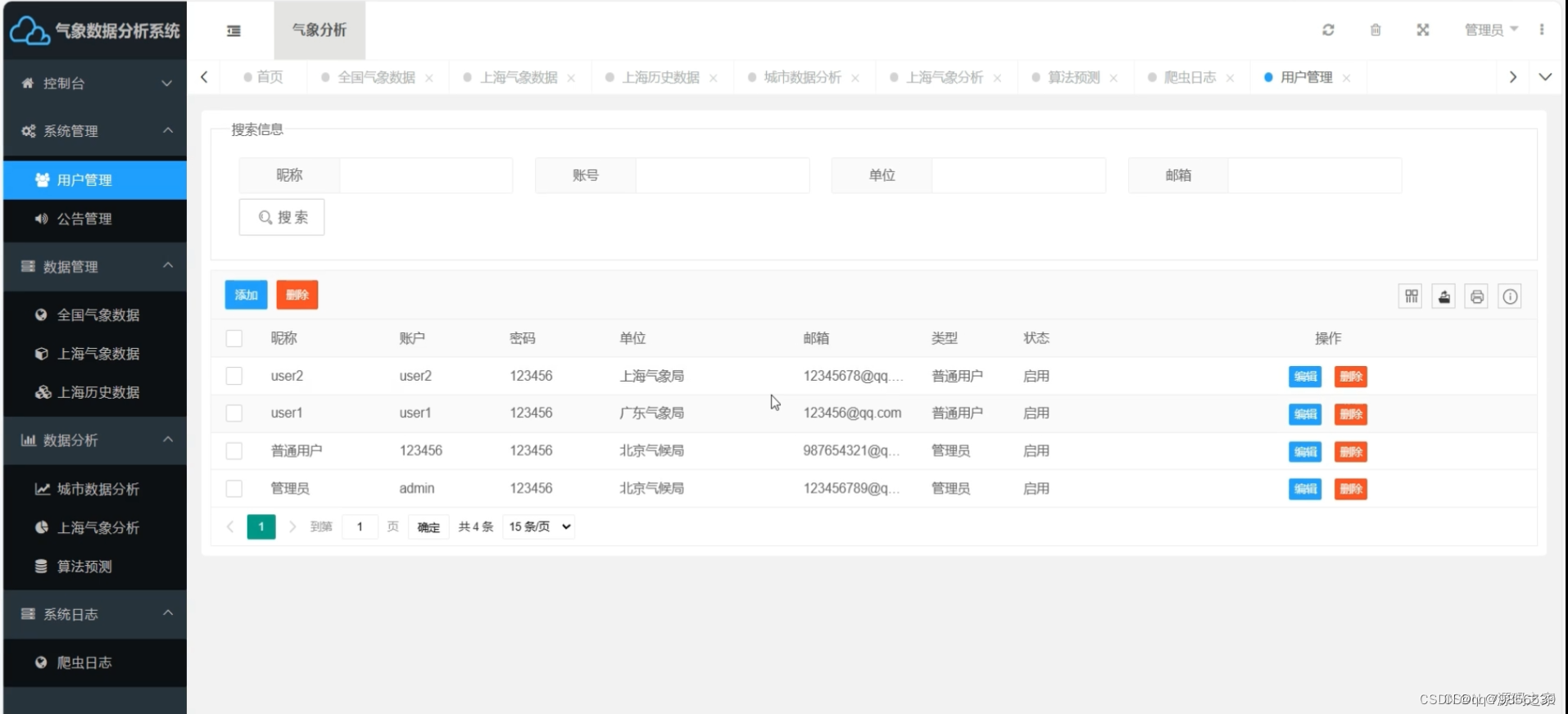


2、项目框架
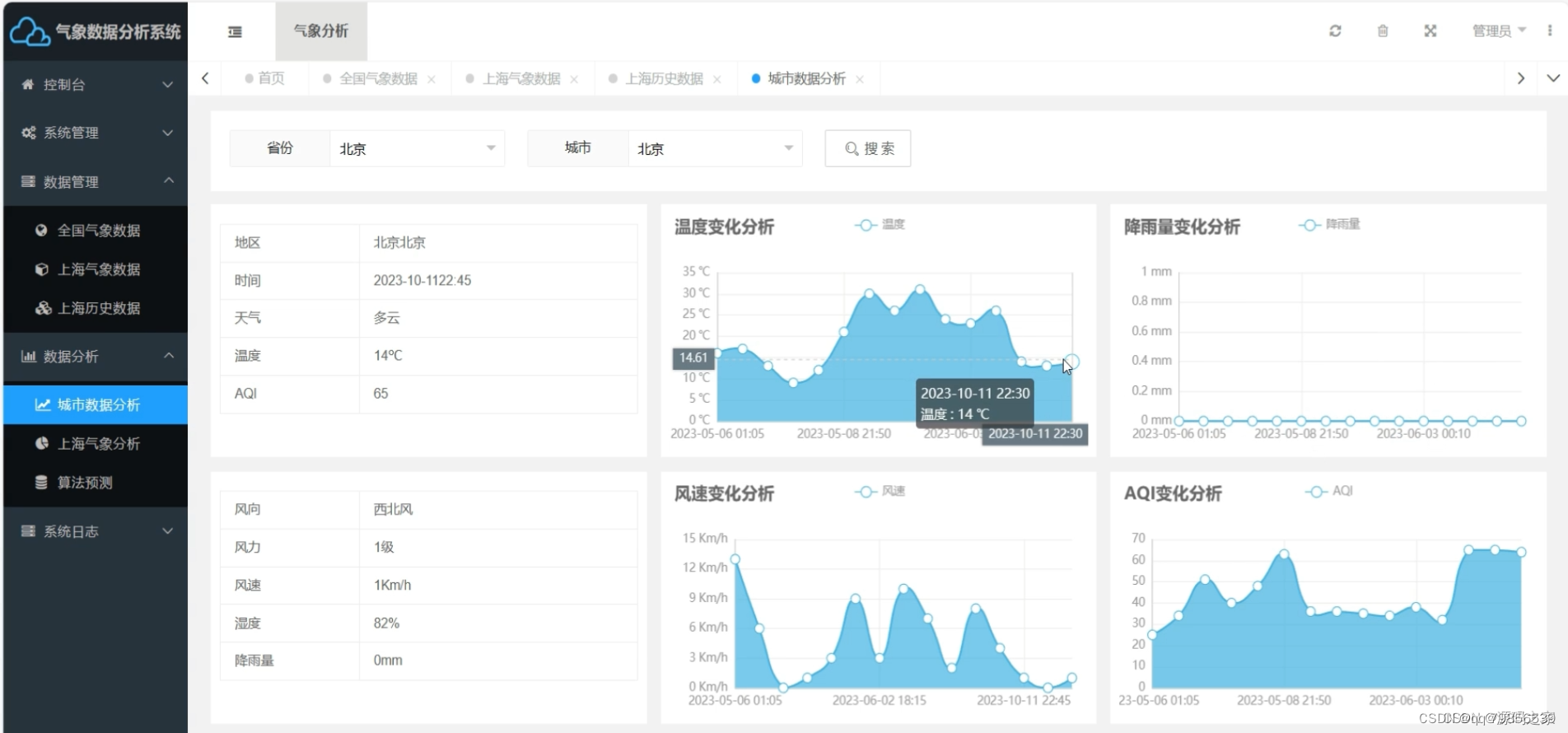
系统功能主要包括数据采集功能、数据可视化功能、数据预测功能、用户登录与注册功能、数据管理功能。其中数据采集功能包含全国实时天气数据采集和上海历史天气数据采集。数据可视化功能包含全国综合天气数据可视化、全国各城市天气数据可视化以及上海历史天气数据可视化。数据预测功能指的是气象分析预测;数据管理指的是多维度的数据管理,包含用户数据、公告数据、全国气象数据管理等。
数据预测模块功能实现
气象数据分析预测模块包括气象数据预测模型的训练以及利用现有气象数据,加载气象模型进行预测。
首先气象数据预测是根据各地区近12个月的上海的历史气象数据做为数据级,首先从数据库中导出CSV格式的数据,然后利用pandas和numpy技术对数据进行预处理、格式化数据以及数据集分割。分割完成后,试用sklearn库进行构建多元线性回归模型,再将分割后的数据进行投喂,训练模型。最终将模型保存并计算模型的EMS损失值用于参考模型的训练效果。















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









