







 本文详细介绍了如何在PaddleDetection框架下下载数据集,整理文件,划分数据集,安装依赖,配置参数,以及使用CPU和GPU运行模型、模型推理、评估和可视化的过程。重点讲解了config文件的设置和常见问题的解决方案。
本文详细介绍了如何在PaddleDetection框架下下载数据集,整理文件,划分数据集,安装依赖,配置参数,以及使用CPU和GPU运行模型、模型推理、评估和可视化的过程。重点讲解了config文件的设置和常见问题的解决方案。
本文章为个人学习记录,仅供参考
对应说明视频:三步完成训练一个吸烟检测模型_哔哩哔哩_bilibili
目录
第一步:下载数据集
对于说明视频:三步完成训练一个吸烟检测模型_哔哩哔哩_bilibili
数据集下载地址:吸烟检测_数据集-飞桨AI Studio星河社区
PaddleDetection_2.7: PaddleDetection_2.7_数据集-飞桨AI Studio星河社区
官方PaddleDetection套件说明:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
官方不同版本PaddleDetection下载:https://github.com/PaddlePaddle/PaddleDetection
 在左上角选择PaddleDetection版本,点击code中的download下载压缩包
在左上角选择PaddleDetection版本,点击code中的download下载压缩包
第二步:整理下载的文件
!unzip -o /home/aistudio/data/data267000/pp_smoke.zip -d /home/aistudio/work划分数据集与测试集
import random
import os
random.seed(2024)
#生成train.txt和val.txt
xml_dir = '/home/aistudio/work/Annotations'#标签文件地址,数据解压地址
img_dir = '/home/aistudio/work/images'#图像文件地址,数据解压地址
path_list = list()
for img in os.listdir(img_dir):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
random.shuffle(path_list)
ratio = 0.9
train_f = open('/home/aistudio/work/train.txt','w') #生成训练文件
val_f = open('/home/aistudio/work/val.txt' ,'w')#生成验证文件
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
if i < len(path_list) * ratio:
train_f.write(text)
else:
val_f.write(text)
train_f.close()
val_f.close()
#生成标签文档
label = ['smoke']#设置你想检测的类别
with open('/home/aistudio/work/label_list.txt', 'w') as f:
for text in label:
f.write(text+'\n')解压PaddleDetection
这里为了方便将PaddleDetection-release-2.7文件名改为PaddleDetection
# 解压源码 解压完将PaddleDetection-release-2.7改名为PaddleDetection
!unzip -oq /home/aistudio/data/data267001/PaddleDetection-release-2.7.zip -d /home/aistudio/work/安装PaddleDetection依赖库,并设置环境变量
%cd /home/aistudio/work/PaddleDetection
!pip install -r requirements.txt # requirements.txt列出了PaddleDetection的所有依赖库
!pip install Cython pycocotools
%env PYTHONPATH=.:$PYTHONPATH
%env CUDA_VISIBLE_DEVICES=0
!pip install numba==0.56.4第三步:运行模型
说明视频:三步完成训练一个吸烟检测模型_哔哩哔哩_bilibili
修改voc.yml和ppyolov2_r50vd_dcn_voc.yml中的一些参数,可直接复制文章中的代码即可,这两个文件在下面都有展示。
使用cpu运行:
#cpu
%cd /home/aistudio/work/PaddleDetection
!python /home/aistudio/work/PaddleDetection/tools/train.py \
-c /home/aistudio/work/PaddleDetection/configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml \
-o use_gpu=False --eval --use_vdl=True --vdl_log_dir="./output"使用gpu运行:
#gpu
%cd /home/aistudio/work/PaddleDetection
!python /home/aistudio/work/PaddleDetection/tools/train.py \
-c /home/aistudio/work/PaddleDetection/configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml \
--eval --use_vdl=True --vdl_log_dir="./output"第四步:模型推理
以下代码说明:
ppyolov2_r50vd_dcn_voc.yml:需要推理的模型文件
infer_img:需要测试的图片路径,可以自己随意选一张
weights:推理时用的模型权重,建议选择最佳权重best_model.pdparams
# 可视化预测结果
# ! python tools/infer.py -c ../../work/yolov3_darknet53_100e_cocoval.yml --infer_img=../work/dog.jpg
! python /home/aistudio/work/PaddleDetection/tools/infer.py \
-c /home/aistudio/work/PaddleDetection/configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml \
--infer_img=/home/aistudio/work/images/smoke_a189.jpg \
-o weights=/home/aistudio/work/PaddleDetection/output/best_model.pdparams效果说明:

第五步:模型评估
#模型评估
!python -u tools/eval.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml -o weights=/home/aistudio/work/PaddleDetection/output/best_model.pdparams第六步:数据模型可视化
官方VisaulDL说明:AI Studio-帮助文档 (baidu.com)


模型文件可下载到本地中再上传查看,文件格式为pdmodel,默认存放在output当中
展示部分效果:
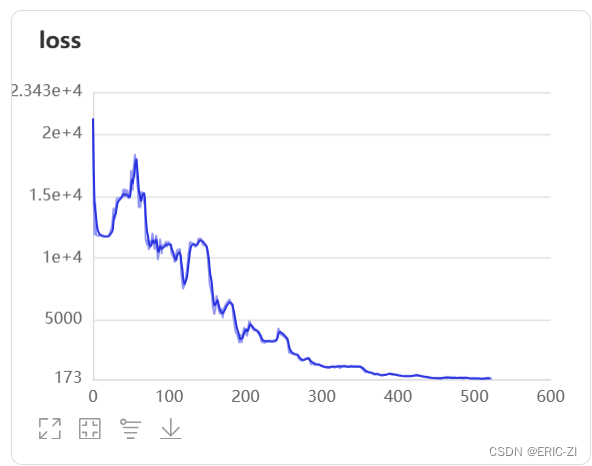
以上就完成了模型的训练,以下是一些文件说明
A.运行文件的参数设置
train.py 脚本,训练模型的设置文件
ppyolov2_r50vd_dcn_voc.yml:模型的配置文件
--eval:这个标志表示每个 epoch 后都要评估模型
--use_vdl=True:这个参数启用了 VisualDL,这是一个可视化训练过程的工具
--vdl_log_dir="./output":这个参数指定了 VisualDL 日志应该存储的目录
B.具体文件配置说明
官方PaddleDetection文件说明:项目文件预览 - PaddleDetection - GitCode
B1、runtime.yml
文件说明:公共的运行参数,比如说是否使用GPU、每多少个epoch存储checkpoint等
文件路径:/home/aistudio/work/PaddleDetection/configs/runtime.yml
log_iter: 20:这个参数表示每训练20个iteration就打印一次日志
save_dir: output:这个参数表示模型训练的输出目录。
snapshot_epoch: 1:这个参数表示每训练1个epoch就保存一次模型。
B2、ppyolov2_r50vd_dcn.yml
文件说明:模型、和主干网络的情况
文件路径:/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/ppyolo_r50vd_dcn.yml
architecture: YOLOv3:这个参数表示使用YOLOv3作为检测模型的架构
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet50_vd_ssld_pretrained.pdparams:这个参数表示预训练模型的权重文件的下载链接
在YOLOv3部分: backbone: ResNet:这个参数表示使用ResNet作为模型的骨干网络
在ResNet部分: depth: 50:这个参数表示ResNet的深度为50
B3、optimizer_365e.yml
文件说明:学习率和优化器的配置
文件路径:/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/optimizer_365e.yml
epoch: 365:这个参数表示训练的总轮数(epoch)为365
在**LearningRate**部分:
base_lr: 0.005:这个参数表示基础学习率为0.005。
schedulers:这个参数表示学习率调度器,包括PiecewiseDecay和LinearWarmup。 !PiecewiseDecay:这是一种分段衰减的学习率调度策略。
参数**gamma: 0.1**表示每个分段后学习率的衰减率为0.1,
**milestones: [243]表示在第243轮时进行学习率衰减。
!LinearWarmup:这是一种线性热身的学习率调度策略。
参数start_factor: 0.表示热身开始时的学习率因子为0
steps: 4000**表示热身阶段的步数为4000。
momentum: 0.9:这个参数表示动量为0.9
type: L2:这个参数表示正则化器的类型为L2
B4、ppyolov2_reader.yml
文件说明:主要说明数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等
文件路径:/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/ppyolov2_reader.yml
B5、voc.yml
文件说明:数据配置
文件路径:/home/aistudio/work/PaddleDetection/configs/datasets/voc.yml
metric: VOC
map_type: 11point
num_classes: 1 #检测的目标类别,本案例为1
TrainDataset:
name: VOCDataSet
dataset_dir: /home/aistudio/work/images # dataset/voc #训练数据所在文件夹
anno_path: /home/aistudio/work/train.txt # trainval.txt # 训练数据标注所在文件
label_list: /home/aistudio/work/label_list.txt # label_list.txt # 标签列表
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
name: VOCDataSet
dataset_dir: /home/aistudio/work/images # dataset/voc # 验证数据所在文件夹
anno_path: /home/aistudio/work/val.txt # test.txt # 验证数据标注所在文件
label_list: /home/aistudio/work/label_list.txt # label_list.txt # 标签列表
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
name: ImageFolder
anno_path: /home/aistudio/work/val.txt # dataset/voc/label_list.txt # 测试数据标注所在文件,此处设置同验证集
注意这里要设置一下各个文件的路径,自己要修改一下
B6、ppyolov2_r50vd_dcn_voc.yml
文件说明:各个文件配置地址,epoch和batch_size设置
文件路径:/home/aistudio/work/PaddleDetection/configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml
_BASE_: [
'/home/aistudio/work/PaddleDetection/configs/datasets/voc.yml',
'/home/aistudio/work/PaddleDetection/configs/runtime.yml',
# 主要说明了公共的运行参数,比如说是否使用GPU、每多少个epoch存储checkpoint等
'/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/ppyolov2_r50vd_dcn.yml',
#主要说明模型、和主干网络的情况
'/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/optimizer_365e.yml',
#主要说明了学习率和优化器的配置
'/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/ppyolov2_reader.yml',
#主要说明数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等
]
#../datasets/voc.yml #/home/aistudio/work/PaddleDetection/configs/datasets/voc.yml
#../runtime.yml #/home/aistudio/work/PaddleDetection/configs/runtime.yml
#./_base_/ppyolov2_r50vd_dcn.yml #/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/ppyolov2_r50vd_dcn.yml
#./_base_/optimizer_365e.yml #/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/optimizer_365e.yml
#./_base_/ppyolov2_reader.yml #/home/aistudio/work/PaddleDetection/configs/ppyolo/_base_/ppyolov2_reader.yml
snapshot_epoch: 43 # 这是模型保存快照的周期,即每83个epoch保存一次模型。 83
weights: output/ppyolov2_r50vd_dcn_voc/model_final # 这是模型权重的保存路径。
TrainReader:
mixup_epoch: 350
batch_size: 5 # 12 注意这里可以调小一点,否则可能带不动
# set collate_batch to false because ground-truth info is needed
# on voc dataset and should not collate data in batch when batch size
# is larger than 1.
EvalReader:
collate_batch: false
epoch: 583 # 583 总的epoch轮数设置
LearningRate:
base_lr: 0.00333
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones:
- 466
- 516
- !LinearWarmup
start_factor: 0.
steps: 4000
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2
C.置信度相关文件设置
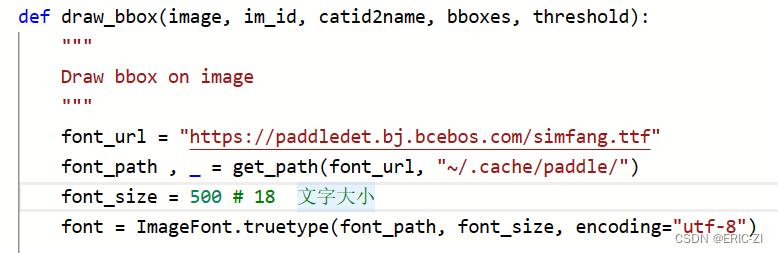
C1、visualizer.py
文件说明:调整识别边框
文件路径:/home/aistudio/work/PaddleDetection/ppdet/utils/visualizer.py
文字大小设置:
边框大小设置:

置信度文本框设置:
text = "{:.2f}".format(score)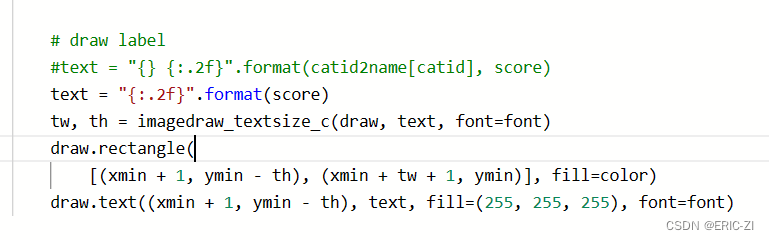
C2、infer.py
文件说明:置信度阈值设置
文件路径:/home/aistudio/work/PaddleDetection/tools/infer.py
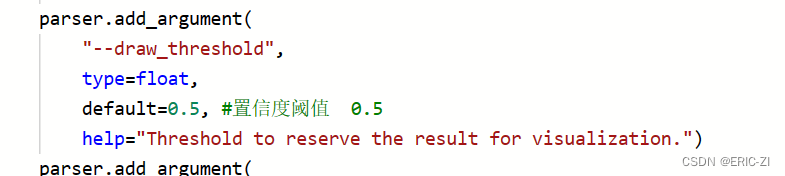
D.配置时可能遇到的一些问题解决办法
在百度AIstudio上运行自己PaddleDetection所遇到的问题及解决方案_can't call main_program when full_graph=false. use-CSDN博客
ModuleNotFoundError: No module named ‘ppdet‘_modulenotfounderror: no module named 'ppdet-CSDN博客















 3672
3672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









