






例如以下内容:
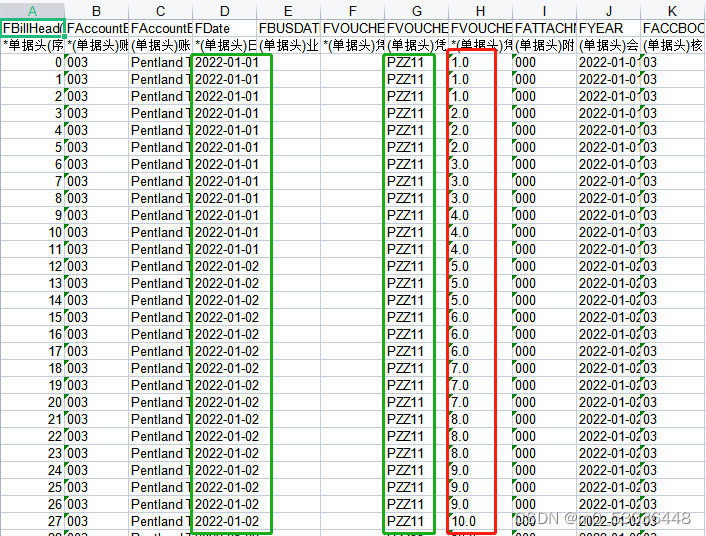
变成如下:
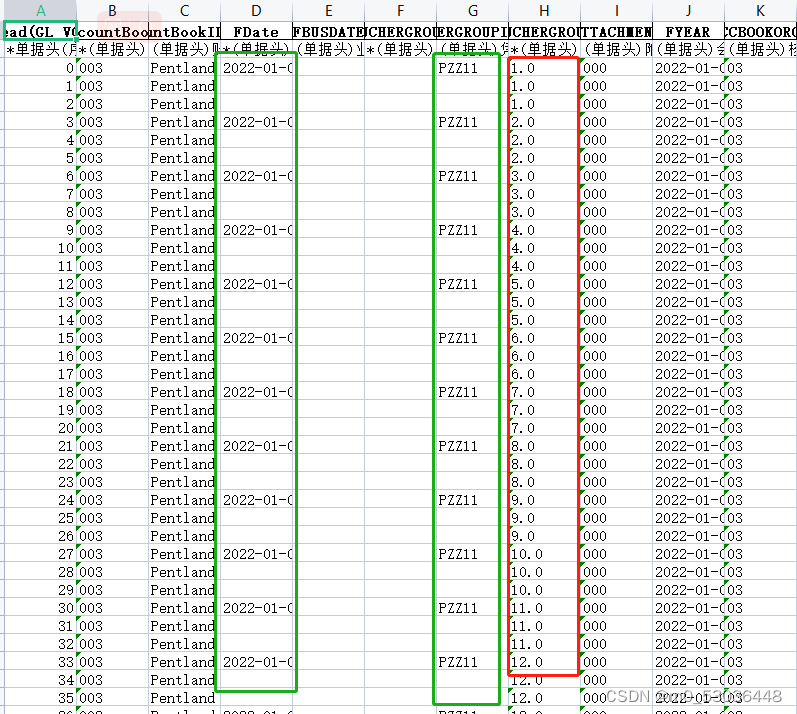
完整代码如下:
import pandas as pd
# 读取Excel文件
df = pd.read_excel('your_file.xlsx')
# 根据某一列的重复值进行处理
duplicate_column = 'column_name' # 指定要处理的列名
# 获取重复行的索引
duplicate_rows = df[df.duplicated(subset=duplicate_column)].index
# 删除重复行的其他列单元格内容
columns_to_keep = ['column_name_1', 'column_name_2'] # 指定要保留的列名(除了重复列之外)
df.loc[duplicate_rows, columns_to_keep] = ''
# 将数据保存到新的Excel文件中
df.to_excel('new_file.xlsx', index=False)如果变成这样:
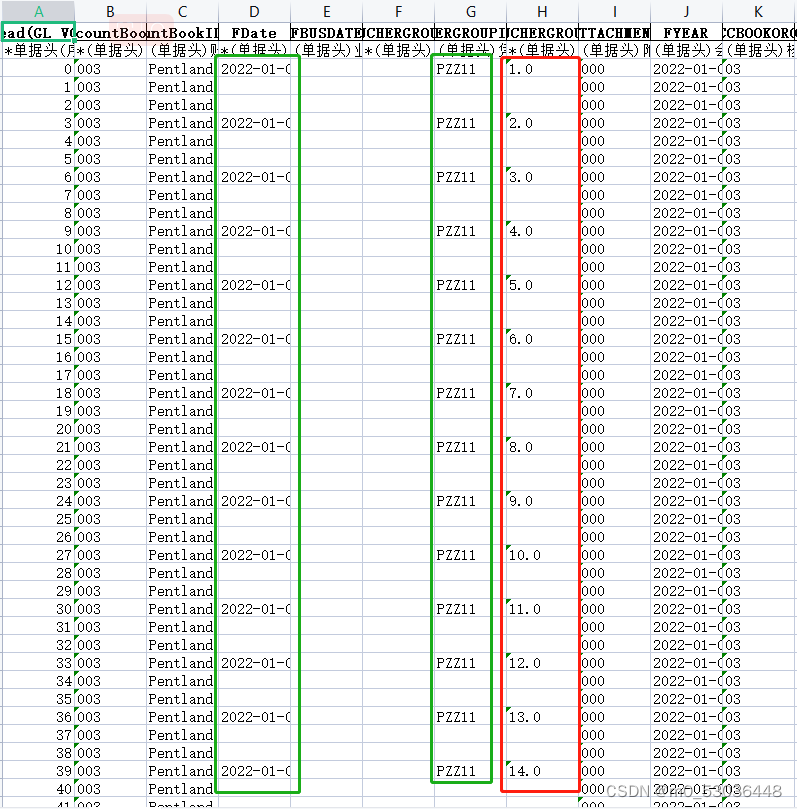
完整代码如下:
import pandas as pd
# 读取Excel文件
df = pd.read_excel('student.xlsx')
# 根据某一列的重复值进行处理
duplicate_column = 'FVOUCHERGROUPNO' # 指定要处理的列名
# 获取重复行的索引
duplicate_rows = df[df.duplicated(subset=duplicate_column)].index
# 删除重复行的其他列单元格内容
columns_to_keep = ['FVOUCHERGROUPID#Name','FDate'] # 指定要保留的列名(除了重复列之外)
df.loc[duplicate_rows, columns_to_keep] = ''
# 根据指定列的重复值进行标记
df['is_duplicate'] = df.duplicated(subset=duplicate_column, keep='first')
# 删除重复的内容,但保留第一个重复值
df.loc[df['is_duplicate'], duplicate_column] = ' '
# 删除标记列
df.drop('is_duplicate', axis=1, inplace=True)
# 将数据保存到新的Excel文件中
df.to_excel('student.xlsx', index=False)















 1927
1927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









