







🌟欢迎来到 我的博客 —— 探索技术的无限可能!
目录
文章描述
- 数据分析:查看变量间相关性以及找出关键变量。
机器学习实战 —— 工业蒸汽量预测(一) - 数据特征工程对数据精进:异常值处理、归一化处理以及特征降维。
机器学习实战 —— 工业蒸汽量预测(二) - 模型训练(涉及主流ML模型):决策树、随机森林,lightgbm等。
机器学习实战 —— 工业蒸汽量预测(三) - 模型验证:评估指标以及交叉验证等。
机器学习实战 —— 工业蒸汽量预测(四) - 特征优化:用lgb对特征进行优化。
机器学习实战 —— 工业蒸汽量预测(五) - 模型融合:进行基于stacking方式模型融合。
机器学习实战 —— 工业蒸汽量预测(六)
背景描述
- 背景介绍
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
- 相关描述
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
- 结果评估
预测结果以mean square error作为评判标准。
数据说明
数据分成训练数据(train.txt)和测试数据(test.txt),其中字段”V0”-“V37”,这38个字段是作为特征变量,”target”作为目标变量。选手利用训练数据训练出模型,预测测试数据的目标变量,排名结果依据预测结果的MSE(mean square error)。
数据来源
http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_test.txt
http://tianchi-media.oss-cn-beijing.aliyuncs.com/DSW/Industrial_Steam_Forecast/zhengqi_train.txt
实战内容
3.模型训练
3.1 回归及相关模型
导入包
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.neighbors import KNeighborsRegressor #K近邻回归
from sklearn.tree import DecisionTreeRegressor #决策树回归
from sklearn.ensemble import RandomForestRegressor #随机森林回归
from sklearn.svm import SVR #支持向量回归
import lightgbm as lgb #lightGbm模型
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split # 切分数据
from sklearn.metrics import mean_squared_error #评价指标
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
## 切分训练数据和线下验证数据
#采用 pca 保留16维特征的数据
new_train_pca_16 = new_train_pca_16.fillna(0)
train = new_train_pca_16[new_test_pca_16.columns]
target = new_train_pca_16['target']
# 切分数据 训练数据80% 验证数据20%
train_data,test_data,train_target,test_target=train_test_split(train,target,test_size=0.2,random_state=0)
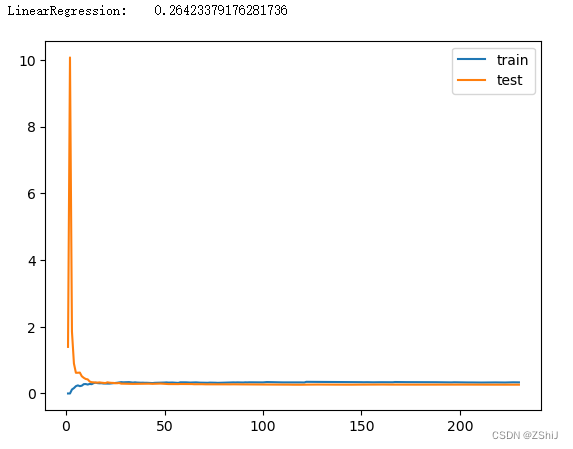
3.1.1 多元线性回归模型
定义绘制模型学习曲线函数
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
print(train_scores_mean)
print(test_scores_mean)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
绘制学习曲线:只需要传入算法(或实例对象)、X_train、X_test、y_train、y_test
当使用该函数时传入算法,该算法的变量要进行实例化,如:PolynomialRegression(degree=2),变量 degree 要进行实例化
def plot_learning_curve_old(algo, X_train, X_test, y_train, y_test):
train_score = []
test_score = []
for i in range(10, len(X_train)+1, 10):
algo.fit(X_train[:i], y_train[:i])
y_train_predict = algo.predict(X_train[:i])
train_score.append(mean_squared_error(y_train[:i], y_train_predict))
y_test_predict = algo.predict(X_test)
test_score.append(mean_squared_error(y_test, y_test_predict))
plt.plot([i for i in range(1, len(train_score)+1)],
train_score, label="train")
plt.plot([i for i in range(1, len(test_score)+1)],
test_score, label="test")
plt.legend()
plt.show()
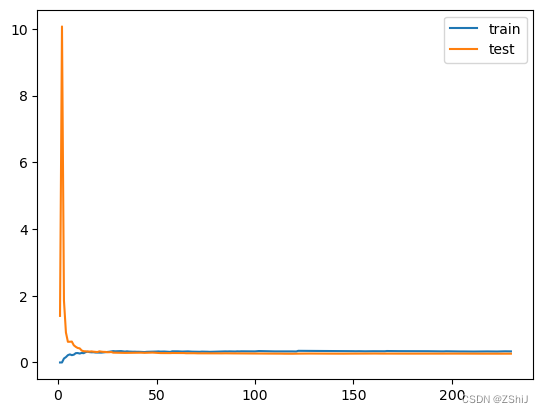
线性回归模型学习曲线
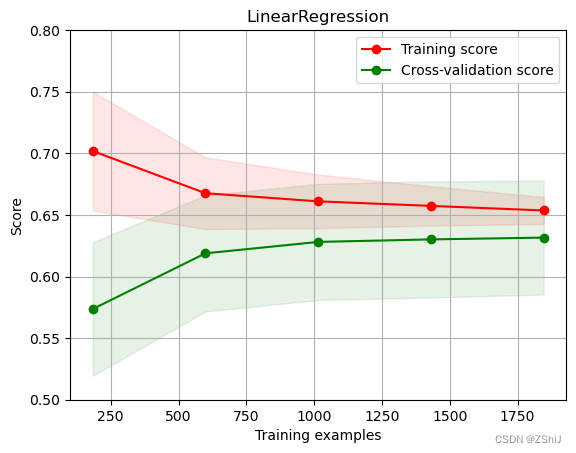
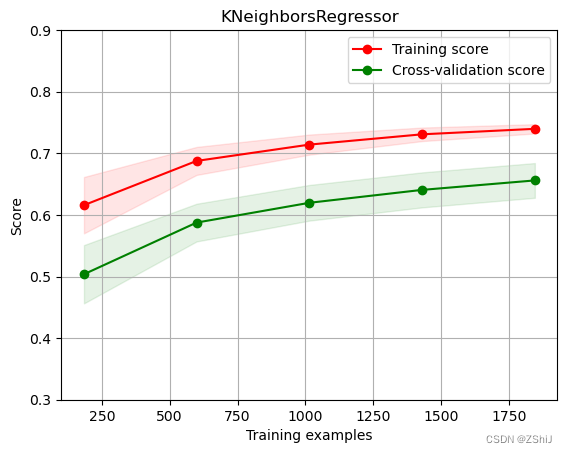
3.1.2 KNN近邻回归
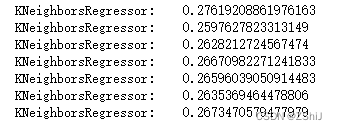
for i in range(3,10):
clf = KNeighborsRegressor(n_neighbors=i) # 最近三个
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("KNeighborsRegressor: ", score)
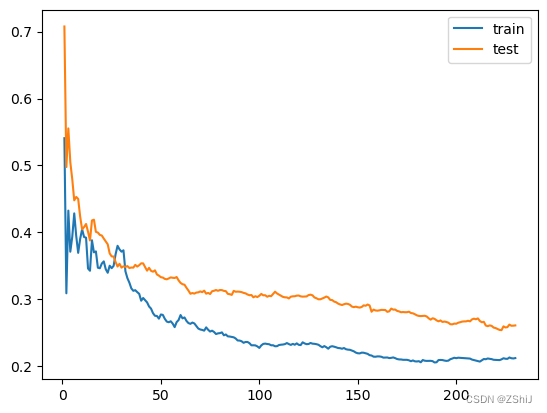
绘制K近邻回归学习曲线——K近邻回归
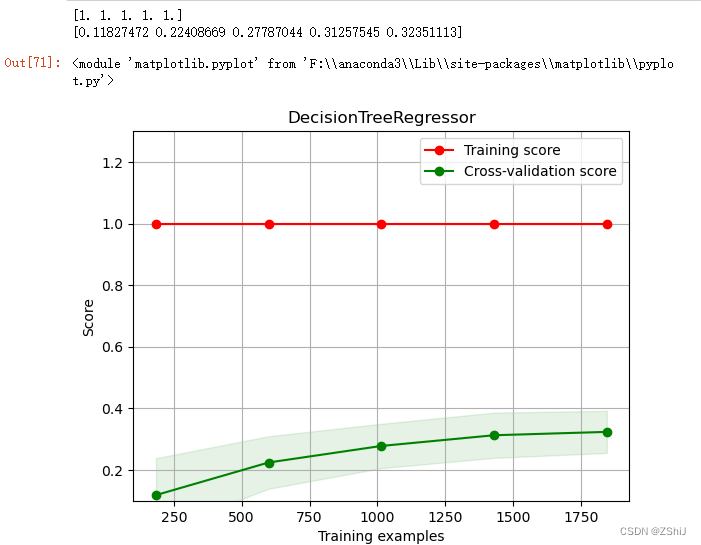
3.1.3决策树回归
clf = DecisionTreeRegressor()
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("DecisionTreeRegressor: ", score)

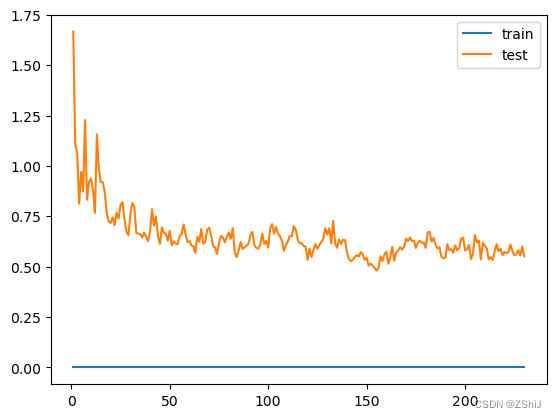
决策树回归
3.1.4 随机森林回归
clf = RandomForestRegressor(n_estimators=200) # 200棵树模型
clf.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("RandomForestRegressor: ", score)
# plot_learning_curve_old(RandomForestRegressor(n_estimators=200), train_data, test_data, train_target, test_target)
X = train_data.values
y = train_target.values
# 随机森林
title = r"RandomForestRegressor"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = RandomForestRegressor(n_estimators=200) #建模
# plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1)
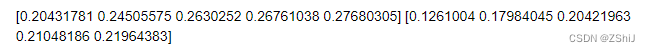
3.1.5 Gradient Boosting
from sklearn.ensemble import GradientBoostingRegressor
myGBR = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.03, loss='huber', max_depth=14,
max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=10, min_samples_split=40,
min_weight_fraction_leaf=0.0, n_estimators=10,
warm_start=False)
myGBR.fit(train_data, train_target)
score = mean_squared_error(test_target, clf.predict(test_data))
print("GradientBoostingRegressor: ", score)
myGBR = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.03, loss='huber', max_depth=14,
max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=10, min_samples_split=40,
min_weight_fraction_leaf=0.0, n_estimators=100,
warm_start=False)
plot_learning_curve_old(myGBR, train_data, test_data, train_target, test_target)
这里我为了快速展示,所以n_estimators设置较小,实战中请按需设置哦
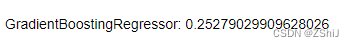
X = train_data.values
y = train_target.values
# GradientBoosting
title = r"GradientBoostingRegressor"
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
estimator = GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.03, loss='huber', max_depth=14,
max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=10, min_samples_split=40,
min_weight_fraction_leaf=0.0, n_estimators=100,
warm_start=False) #建模
# plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1)
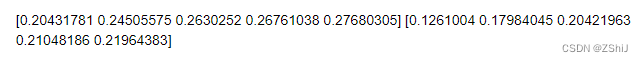
3.1.6 lightgbm回归
这里我为了快速展示,所以n_estimators设置较小,实战中请按需设置哦
# lgb回归模型
clf = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=100,
boosting_type='gbdt',
random_state=2019,
objective='regression',
)
# 训练模型
clf.fit(
X=train_data, y=train_target,
eval_metric='MSE',
verbose=50
)
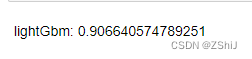
score = mean_squared_error(test_target, clf.predict(test_data))
print("lightGbm: ", score)
这里我为了快速展示,所以n_estimators设置较小,实战中请按需设置哦
X = train_data.values
y = train_target.values
# LGBM
title = r"LGBMRegressor"
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
estimator = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=100,
boosting_type='gbdt',
random_state=2019,
objective='regression'
) #建模
# plot_learning_curve(estimator, title, X, y, ylim=(0.4, 1.0), cv=cv, n_jobs=1)


















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











