






第四次作业:猫狗大战挑战赛
一、代码学习
判断GPU
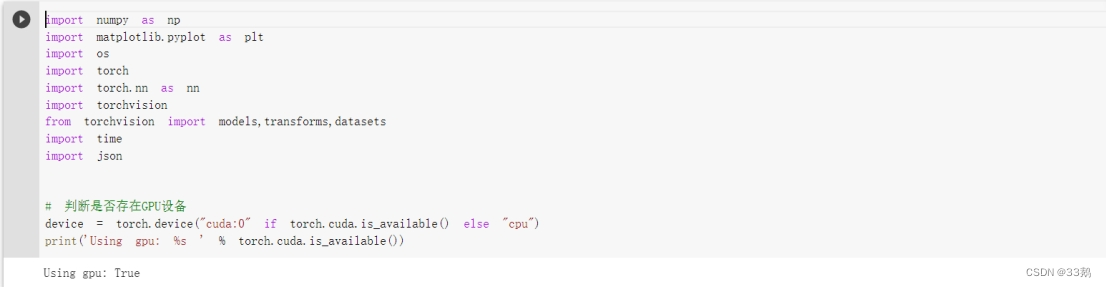
该段代码等同于:
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
torch.device代表将torch.Tensor分配到的设备的对象。torch.device包含一个设备类型(‘cpu’或‘cuda’)和可选的设备序号。如果设备序号不存在,则为当前设备。
下载数据
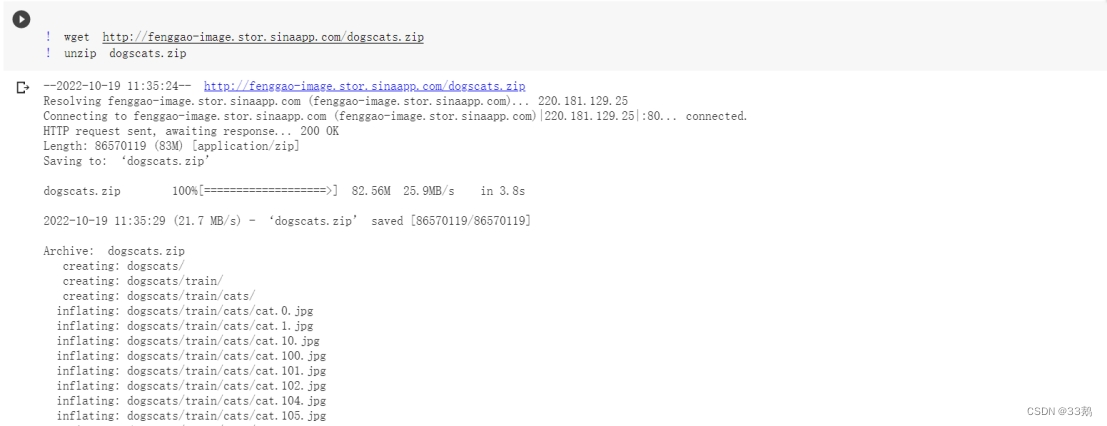
通过给出的下载连接,下载训练集和数据集。
处理数据
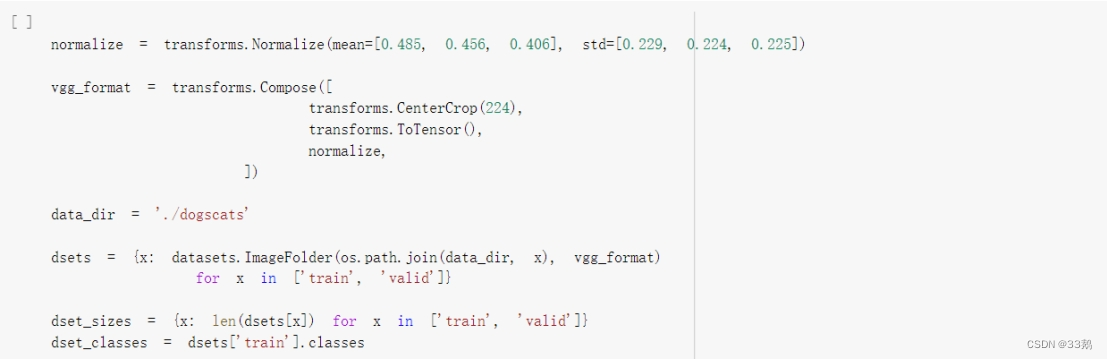
transforms.Normalize():通过计算x = (x - mean)/std实现数据的归一化;
transform.Compose():将transforms有序组合;
transforms.CenterCrop(224):从图片中心开始沿两边裁剪,裁剪后的图片大小为(224*224);
transforms.ToTsensor:将原始的数据格式化为可被pytorch快速处理的张量类型;
datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)for x in [‘train’, ‘valid’]:用多线程的形式从硬盘的data_dir路径中读取每一个’train’,’valid’中的数据。使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行执行vgg_format中的预处理操作。图片将被整理成 2242243的大小,同时还将进行归一化处理。

查看 dsets[‘train’] 的一些属性:
classes:数据集分为了cats,dogs两类;
class_to_idx:数据类别对应的索引(cats为0,dogs为1);
imgs[:5]:打印0-5的图像数组;
查看数据集大小:
dset_sizes:训练集包含1800张图,测试集包含2000张图。
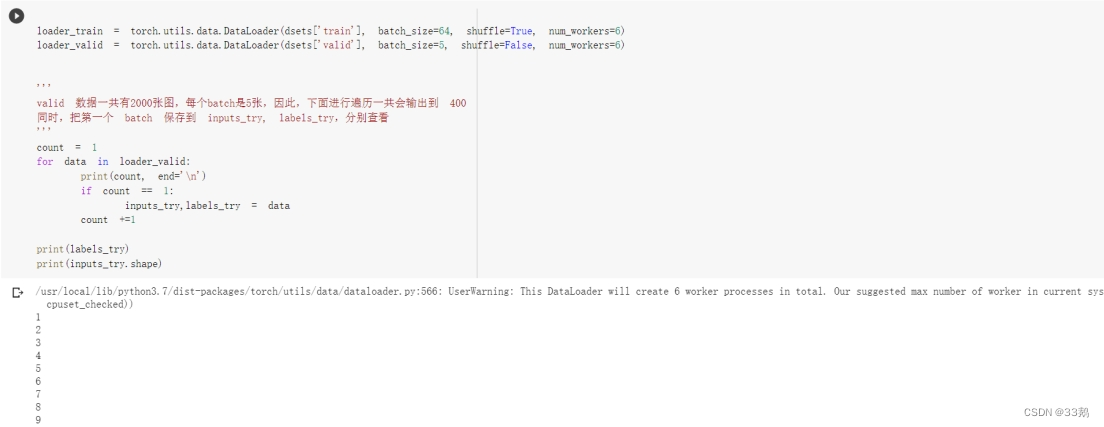

loader_train:对于训练数据集,按每个batch为64输入,随机打乱输入顺序,增加多样性,设置6个工作进程;
loader_valid:对于测试数据集,按每个batch为5输入,不随机打乱输入顺序,设置6个工作进程;
对于测试数据进行遍历,数据共2000张,每个batch为5张,共输出至400。
同时将第一个batch数据赋予inputs_try,labels_try,输出第一个batch及其形状(共5张图,每张图都是2242243)

inp.numpy().transpose((1, 2, 0)):对原始数组进行维数变换;
inp = np.clip(std * inp + mean, 0,1):限制std*inp+mean在0-1内;
plt.pause:设置暂停秒数为0.001秒。
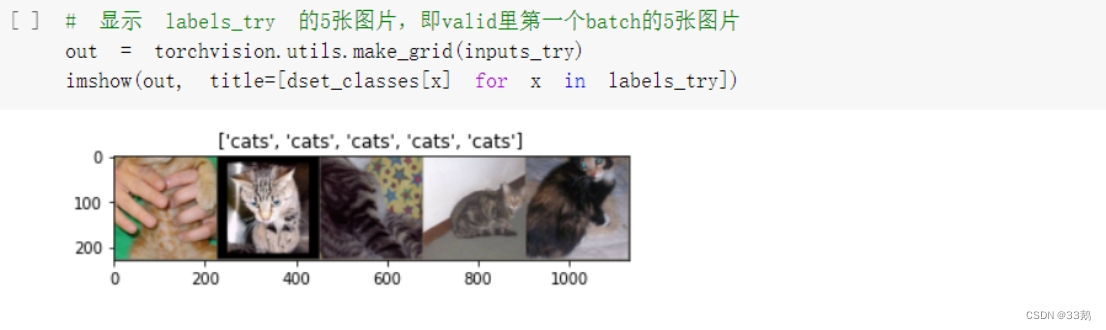
显示第一个batch中的5张图片。
创建VGG
直接使用预训练好的 VGG 模型。下载 ImageNet 1000 个类的 JSON 文件。

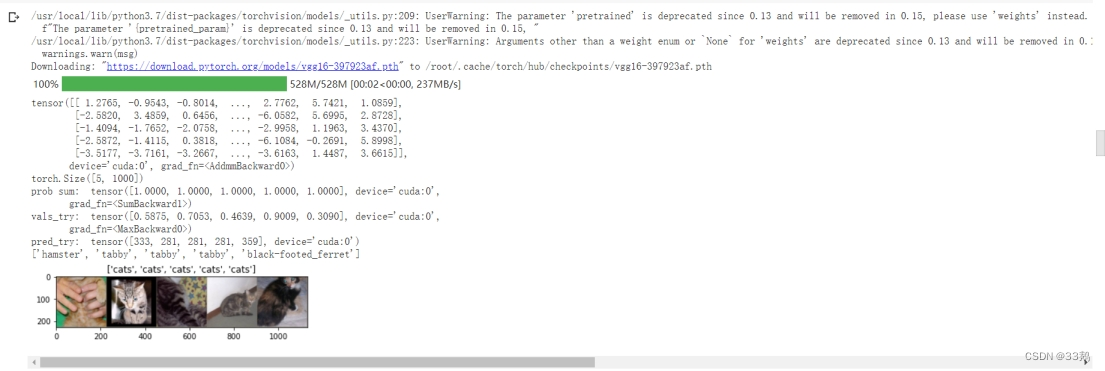
对于数据进行识别,共输出5列1000行的识别结果。
将结果输入到Softmax函数(Softmax函数应用于输入张量,对其进行缩放,使输出张量的元素位于[0,1]范围内,总和为1。)并输出查看结果。
修改最后一层,冻结前面层的参数
使用已经预训练好的模型,前面卷积层,池化层的参数无需改变,只需要改变全连接层输出部分的参数。
把最后的 nn.Linear 层由1000类,替换为2类,因为我们最后得到的结果只有猫狗两类。
为保证反向传播训练梯度时,前面层的权重就不会自动更新,只更新最后一层的参数,我们把前面层的参数冻结,设置 required_grad=False。
代码截图:

运行结果截图:


优化、训练模型:
运行结果截图:

测试模型:
outputs = model(inputs) # 计算网络输出值,就是输入网络一个图像数据,输出猫和狗的概率,调用了网络中的forward()方法
loss = criterion(outputs,classes) # 计算损失
_,preds = torch.max(outputs.data,1)#预测值最大化
运行结果截图:

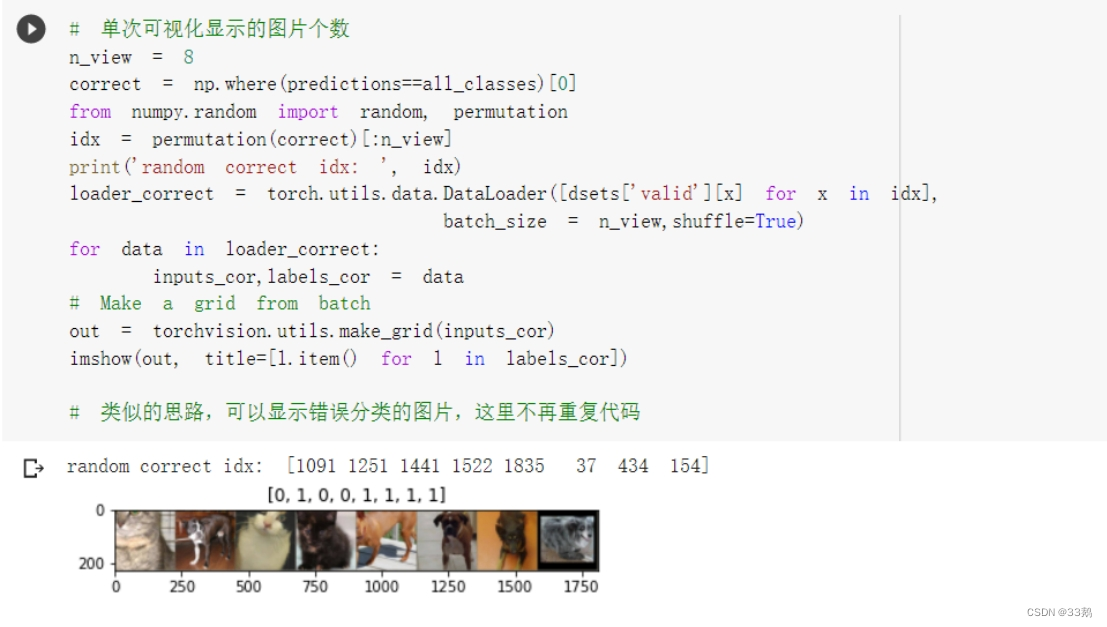
可视化模型预测结果:
把预测的结果和相对应的测试图像输出,输出八张图片并显示预测结果,0为猫,1为狗,由输出结果可知,模型的预测效果较好。
代码及运行结果截图:
二、代码实现,测试上传
评测结果截图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tLLGnqD0-1666438231732)(C:\Users\金知霖\AppData\Roaming\Typora\typora-user-images\image-20221022143353859.png)]](https://img-blog.csdnimg.cn/dfdc10a773ff47a1a5468d959f735508.png)
代码解读:
- 首先进行数据下载:(开启vpn,可加速下载速度)
!wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
!unzip dogscats.zip
!wget https://static.leiphone.com/cat_dog.rar
!unrar x /content/cat_dog.rar
- 引入pytorch包,查看GPU是否启用
import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
-
进行数据预处理,并查看dsets属性(图像类别、类别索引等)
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) vgg_format = transforms.Compose([ transforms.CenterCrop(224), transforms.ToTensor(), normalize, ]) data_dir = '/content/dogscats' dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format) for x in ['train', 'valid']} dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']} dset_classes = dsets['train'].classes print(dsets['train'].classes) print(dsets['train'].class_to_idx) print(dsets['train'].imgs[:5]) print('dset_sizes: ', dset_sizes)可以看到对应索引:

-
shuffle先打乱,再取batch,这里将训练集的shuffle定为true,再把batch保存到相应try中
loader_train = torch.utils.data.DataLoader( dsets['train'], batch_size=64, shuffle=True, num_workers=6) loader_valid = torch.utils.data.DataLoader( dsets['valid'], batch_size=5, shuffle=False, num_workers=6) count = 1 for data in loader_valid: print(count, end='\n') if count == 1: inputs_try,labels_try = data count +=1 print(labels_try) print(inputs_try.shape) -
对数据进行打印预览,这里用到了显示图片的小程序
# 显示图片的小程序 def imshow(inp, title=None): # Imshow for Tensor. inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = np.clip(std * inp + mean, 0,1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # 显示 labels_try 的5张图片,即valid里第一个batch的5张图片 out = torchvision.utils.make_grid(inputs_try) imshow(out, title=[dset_classes[x] for x in labels_try])得到如下结果:

-
获取模型
冻结参数可以在反向传播训练梯度时使得前面层的权重不会自动更新,而是只更新最后一层的参数。
model_vgg = models.vgg16(pretrained=True) print(model_vgg) model_vgg_new = model_vgg; for param in model_vgg_new.parameters(): param.requires_grad = False # 冻结参数 # 更改全连接层的最后一层,使得最后输出的结果只有两个,即分辨猫和狗 model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) model_vgg_new = model_vgg_new.to(device) # 输出新模型 print(model_vgg_new.classifier) -
优化并训练模型
①创建损失函数和优化器
损失函数的输入是一个对数概率向量和一个目标标签,适用于最后一层是log_softmax()的网络。
criterion = nn.NLLLoss() # 损失函数 # 学习率 lr = 0.001
②训练、保存模型
根据预测时最好的情况通过torch.save()保存已经训练好的模型,之后再对测试集进行测试时可通过torch.load()加载模型。
# 使用Adam优化器
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train() # 用于模型训练
for epoch in range(epochs):
epoch_acc_max = 0
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs) #参数前向传播
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad() #优化器梯度初始化
loss.backward() #梯度反向传播
optimizer.step()
_,preds = torch.max(outputs.data,1) #得到预测结果
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
if epoch_acc > epoch_acc_max:
epoch_acc_max = epoch_acc
torch.save(model, 'model_best.pth') #保存最好模型
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new, loader_train,size = dset_sizes['train'],
epochs = 5, optimizer=optimizer_vgg)
③使用最优模型测试test集
dsets = datasets.ImageFolder('/content/cat_dog', vgg_format)
final = {} #结果数组
loader_test = torch.utils.data.DataLoader(dsets, batch_size=1, shuffle=False, num_workers=0)
model_vgg_new = torch.load("/content/model_best.pth")
def test(model,dataloader,size):
model.eval() #参数固定
cnt = 0 # count
for inputs,_ in dataloader:
if cnt < size:
inputs = inputs.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs.data,1) # 预测值最大化
key = dsets.imgs[cnt][0].split("/")[-1].split('.')[0]
final[key] = preds[0]
cnt += 1
else:
break;
test(model_vgg_new,loader_test,size=2000)
# 以表格形式存入
with open("/content/test.csv",'a+') as f:
for key in range(2000):
f.write("{},{}\n".format(key,final[str(key)]))
提高准确率:
1.修改优化器:使用Adam优化器相对于DSG梯度下降优化更优。
2.适当增加epochs:在训练的过程中,迭代的次数越多理论上模型预测越精确。
3.优化模型:训练集的大小能够在一定程度上影响模型预测的准确度,训练量越多理论上模型越精确,但耗时越长。















 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









