






相关性分析模型可行性报告
基于数值的模型-xgboost
简介
XGBoost是一个优化的分布式梯度提升库,旨在高效,灵活和便携。它在梯度提升框架下实现机器学习算法。XGBoost提供了一个并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。
GBDT梯度提升树
GBDT算法是一种非常常用的Boosting算法(一种集成学习模型,将弱学习器不断调整权重,提升为强学习器),GBDT算法将损失函数的负梯度作为残差的近似值,不断使用残差迭代和拟合回归树,最终生成强学习器。
核心思想
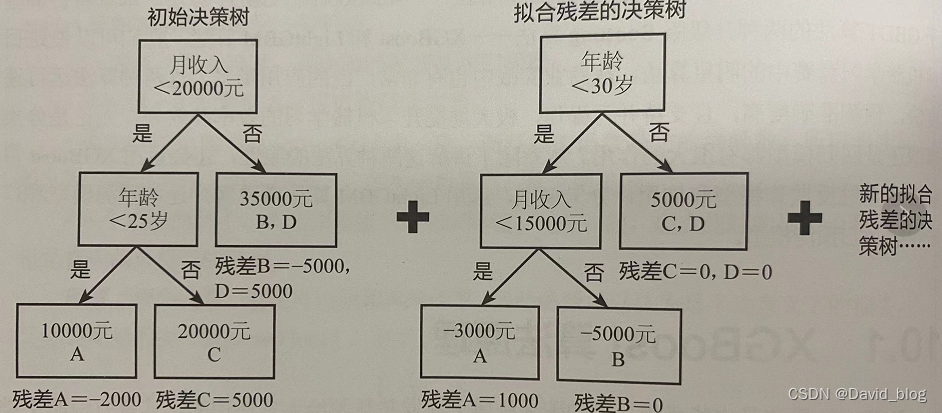
XGBoost算法在某种程度上可以说是GBDT算法的改良版,两者在本质上都是利用了Boosting算法中拟合残差的思想。如下图所示,首先建立一棵初始决策树,其中初始决策树的预测结果不完全准确,会产生一些残差,因此会用新的决策树来拟合该残差,新的决策树又会产生新的残差,这是再构建新的决策树来拟合新的残差······如此迭代下去,直至符合预先设定的条件为止。
主要优缺点
优点:简单易用、在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高,鲁棒性强、可以自动填充缺失值
缺点:只能处理连续性数数值
处理为数值型
将离散型特征编码为1,2,3···
编码方式解释如下:
例如:特征CPU的取值为i3,i5,i7,i9···
| 编码前 | 编码后 |
|---|---|
| i3 | 1 |
| i5 | 2 |
| i7 | 3 |
| i9 | 4 |
| i9 | 4 |
| i7 | 3 |
| i3 | 1 |
基于标签的模型-lightgbm
简介
lightgbm算法由微软公司开发,它和xgboost算法一样是对GBDT算法的高效实现,原理上与xgboost算法类似,但树的生长过程不一样,xgboost的生长是level-wise的,即一层一层生长的,而lightgbm是leaf-wise即梯度优先的,同时lightgbm使用直方图算法,先对特征值进行装箱处理,形成一个一个的bins。对于连续特征来说,装箱处理就是特征工程中的离散化:如[0,0.3)—>0,[0.3,0.7)—->1等。在Lightgbm中默认的#bins为256(1个字节的能表示的长度,可以设置)。对于分类特征来说,则是每一种取值放入一个bin,且当取值的个数大于max bin数时,会忽略那些很少出现的category值。
主要优缺点
优点:训练效率更高,低内存使用,准确率更高,支持并行化学习,可以处理大规模数据,适合离散类数据
缺点:会对连续值特征进行装箱处理,造成精度丢失。















 2568
2568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









