










可信度分析
SPSS是常用的统计学数据处理软件,在运用该软件处理数据时会用到数据的可信度分析,通常可信度分析也会在问卷调查等方面运用到,下面是SPSS对于可信度分析的操作
分析-标度-可靠性分析
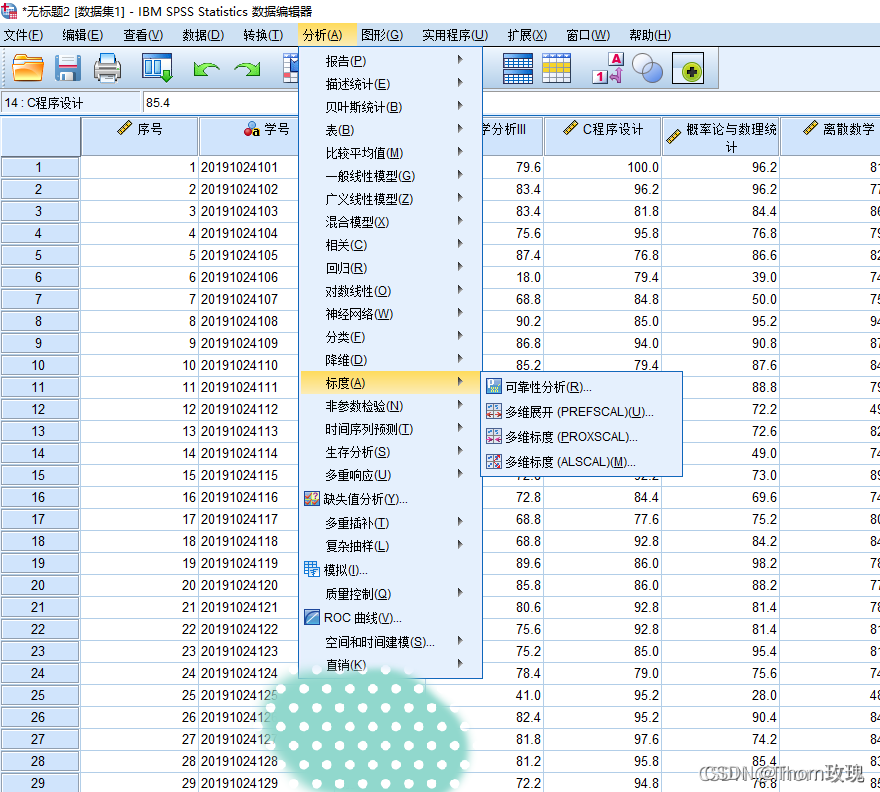
注意标选统计中的“删除项后的标度”,该步骤用于去判断数据的合理性,也可对数据的规划起到很大的参考价值

在输出中主要考虑克隆巴赫系数:越接近1可信度越高

- 注意最后一项的删除项后的克隆巴赫系数为重要的指标,该项表示删除该项后的整体的克隆巴赫系数。
- 如果删除后的克隆巴赫系数比原先的高了,就说明删除该项后可信度会更高,例如本例中的整体克隆巴- 赫系数为0.745,而c程序设计的删除项后的克隆巴赫系数为0.874,则建议删除该项数据。
- 如果各项的删除后的克隆巴赫系数都低于整体的克隆巴赫系数,则认为其数据为较为稳定的



















 8836
8836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









