






1. InternLM2模型基本要点
1.1 数据处理过程
总结来说:整个数据处理流程首先将来自不同来源的数据标准化以获得格式化数据。然后,使用启发式统计规则对数据进行过滤以获得干净数据。接下来,使用局部敏感哈希(LSH)方法对数据去重以获得去重数据。然后,我们应用一个复合安全策略对数据进行过滤,得到安全数据。我们对不同来源的数据采用了不同的质量过滤策略,最终获得高质量预训练数据。
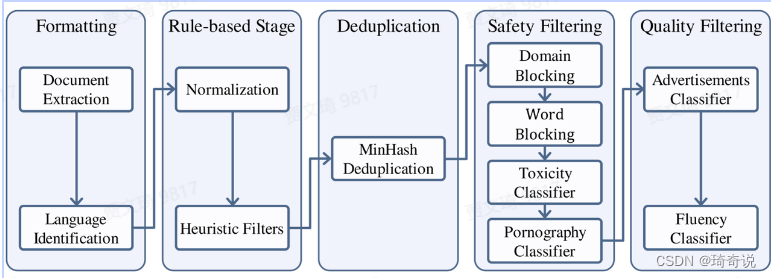
有意思的是,对于有害信息的处理,团队采用了kaggle里面的一个比赛的数据集,微调了BERT模型得到了一个分类器。
质量过滤方面采用了人工标注(带劲)
代码方面:
- 低质量数据被排除在外,团队发现,尽管它们的比例相对较小,但去除它们对于优化模型性能和确保训练稳定性至关重要。
- 所有数据都转换为统一的Markdown格式。
1.2 长上下文
长上下文数据会再训练一次:它包括三个阶段:a)长度选择,这是一个基于规则的过滤器,选取超过32K字节的样本;b)统计过滤器,利用统计特征来识别和移除异常数据;c)困惑度过滤器,利用困惑度的差异来评估文本片段之间的连贯性,过滤掉上下文不连贯的样本。需要注意的是,选定用于长上下文训练的所有数据都是标准预训练语料库的一个子集,这意味着长上下文数据至少在预训练期间会被学习两次。
1.3 预训练
- 使用GPT-4的tokenization方法
在训练过程中,我们使用AdamW (Loshchilov & Hutter, 2019)优化模型,其参数设置为 β 1 = 0.9 , β 2 = 0.95 , ϵ = 1 e − 8 \beta_1=0.9, \beta_2=0.95, \epsilon=1e-8 β1=0.9,β2=0.95,ϵ=1e−8和 w e i g h t _ d e c a y = 0.1 weight\_decay=0.1 weight_decay=0.1。采用余弦学习率衰减,学习率衰减至其最大值的10%
为了适应这些更长的序列,确保为长上下文提供更有效的位置编码(Liu et al., 2023b),我们将旋转位置嵌入(RoPE)的基础从50,000调整到1,000,000。得益于 InternEvo (Chen et al., 2024a) 和 flash attention (Dao, 2023) 的良好可扩展性,当上下文窗口从4K更改为32K时,训练速度仅降低了40%。
尽管RLHF取得了成就,但其实际应用中仍存在一些问题。首先是偏好冲突。例如,在开发对话系统时,我们期望它提供有用的信息(有益)的同时不产生有害或不适当的内容(无害)。然而,在实际中,这两者往往无法同时满足,因为提供有用的信息在某些情况下可能涉及敏感或高风险内容。现有的RLHF方法 (Touvron et al., 2023b; Dai et al., 2023; Wu et al., 2023) 通常依赖于多个偏好模型进行评分,这也使得训练管道中引入了更多的模型,从而增加了计算成本并减慢了训练速度。其次,RLHF面临奖励滥用(reward hacking)的问题,特别是当模型规模增大,策略变得更强大时 (Manheim & Garrabrant, 2018; Gao et al., 2022),模型可能会通过捷径“欺骗”奖励系统以获得高分,而不是真正学习期望的行为。这导致模型以非预期的方式最大化奖励,严重影响LLMs的有效性和可靠性。
为了解决这些问题,我们提出了条件在线RLHF(Conditional OnLine RLHF, COOL RLHF)。COOL RLHF首先引入了一个条件奖励机制来调和不同的偏好,允许奖励模型根据特定条件动态地分配其注意力到各种偏好上,从而最优地整合多个偏好。此外,COOL RLHF采用多轮在线RLHF策略,以使LLM能够快速适应新的人类反馈,减少奖励滥用的发生。
对齐方面内容过多,之后再进行补充。
2. 全链路开源体系

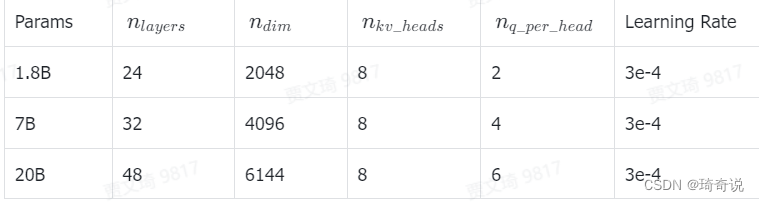
InternLM2:有不同的规格(7B/20B)和模型版本(InternLM2-Base/InternLM2/InternLM2-Chat)
- 7B:为轻量级的研究和应用提供了一个轻便且性能不俗的模型 20B:模型的综合性能更为强劲,可以有效支持更加复杂的实用场景
- InternLM2-Base:高质量和具有很强可塑性的模型基座
- InternLM2:在Base的基础上,从多方面进行强化,在大部分任务中推荐首选此版本
- InternLM2-Chat:在Base的基础上,针对对话交互任务进行优化,主要用于聊天















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









