






1. 基础作业
1. 1 使用transformer库运行模型
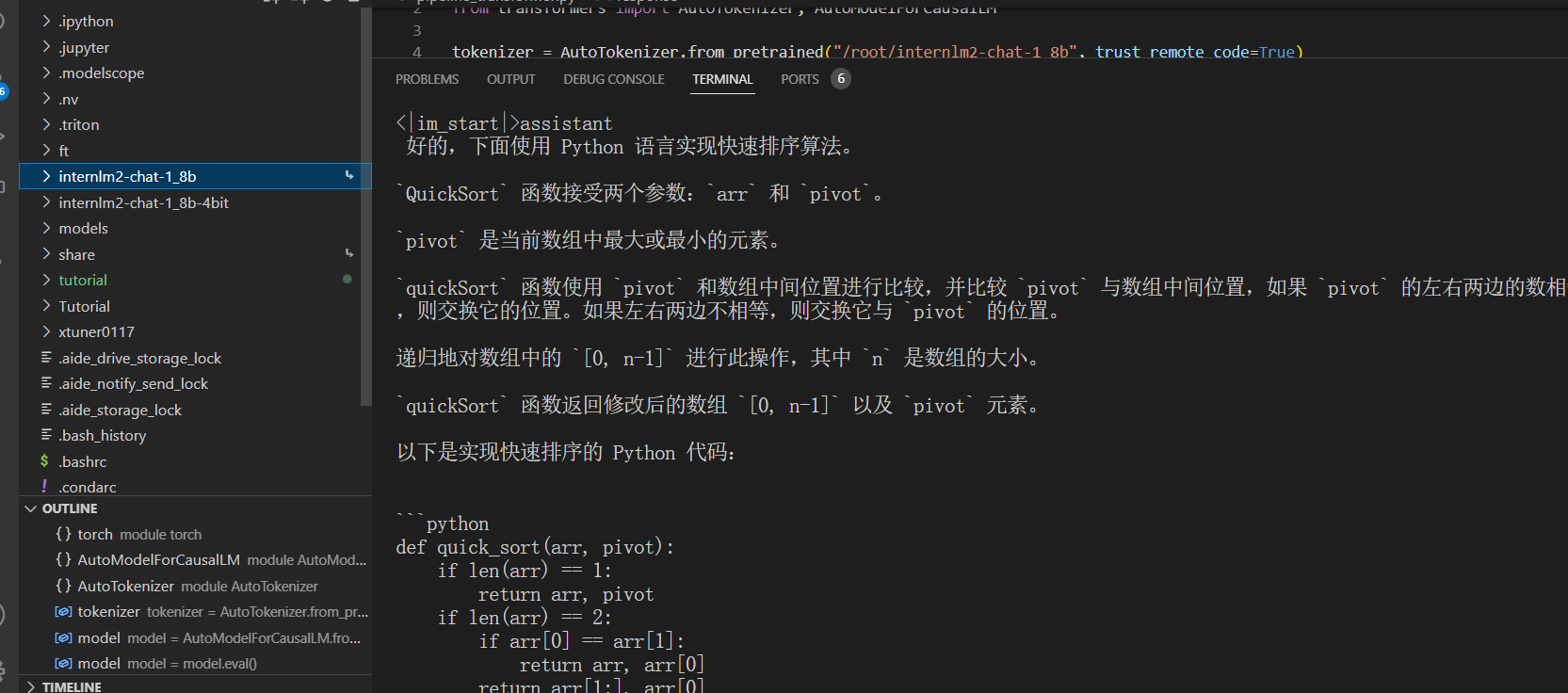
话说这是谱语对中文支持好吗?
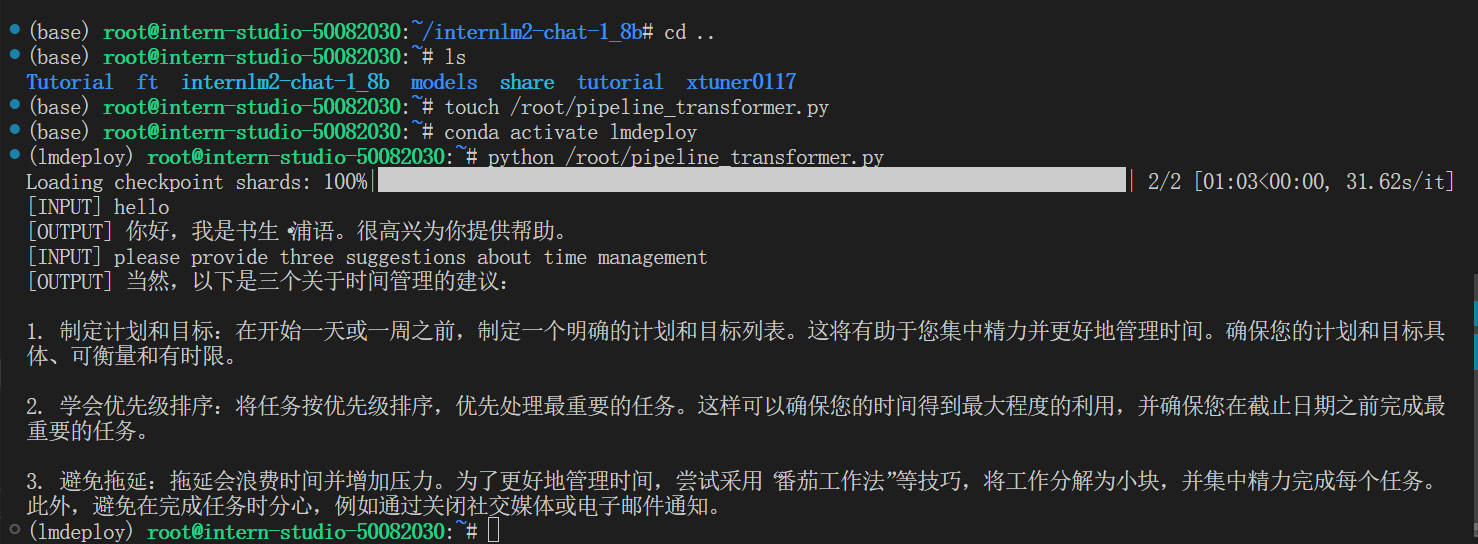
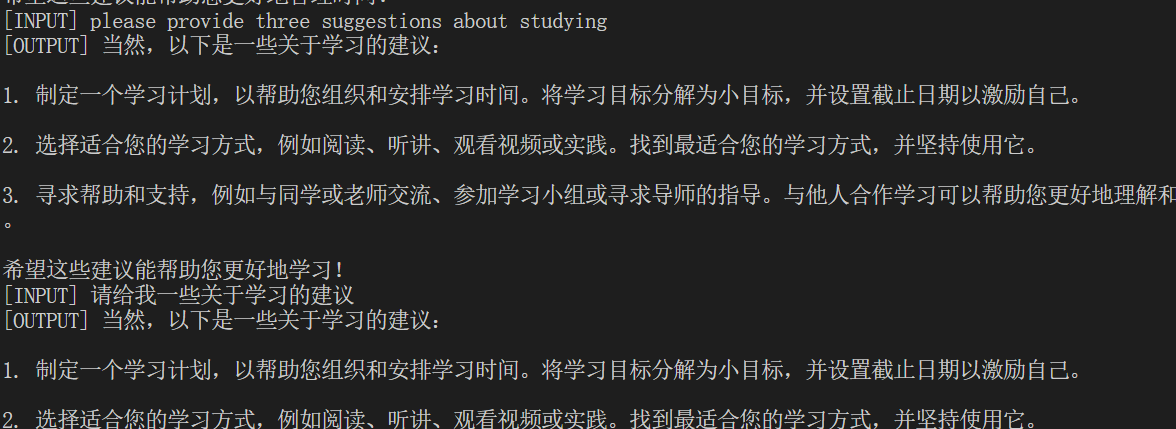
试了试
补一下量化的资料:
KV8和W4A16量化是神经网络模型在进行推理时使用的量化技术,用于优化模型的存储需求和计算速度。这些技术通过减少模型中权重和激活的数值精度来达到目的。下面是这两种量化策略的详细解释:
KV8量化
KV8量化可能是一种定制的量化策略,其中“KV”可能指的是特定的权重(Kernels)或者数据(如Key-Value对)的量化策略,而“8”指的是使用8位(通常是8位整数)来表示这些权重或数据。这种策略通常用于神经网络中的卷积核或其他参数,以减少模型大小和提高计算效率。然而,需要注意的是,“KV8”并不是一个广泛认知的术语,可能是特定库或框架中的一个特定实现。
W4A16量化
W4A16量化是指使用4位精度来量化权重(Weights,W4),和16位精度来量化激活(Activations,A16)。这种量化策略在某些场景中可以有效平衡性能和精度,特别是在资源受限的设备上运行大型神经网络模型时。
- 权重量化(W4):通过将权重的精度从原来的32位浮点数减少到4位整数,显著减小了模型权重的内存占用。这通常会导致一些精度损失,但如果通过适当的训练和校准技术进行优化,这种损失可以被控制在可接受的范围内。
- 激活量化(A16):激活通常是神经网络中非线性函数的输出,如ReLU。使用16位整数来表示这些值可以在维持较高计算精度的同时减少计算资源的消耗。
1.2 使用lmdeploy运行模型,命令行对话

2. 进阶作业
2.1 设置最大KV Cache缓存大小 + W4A16量化
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.4
占用显存更小
输出的飕飕的:
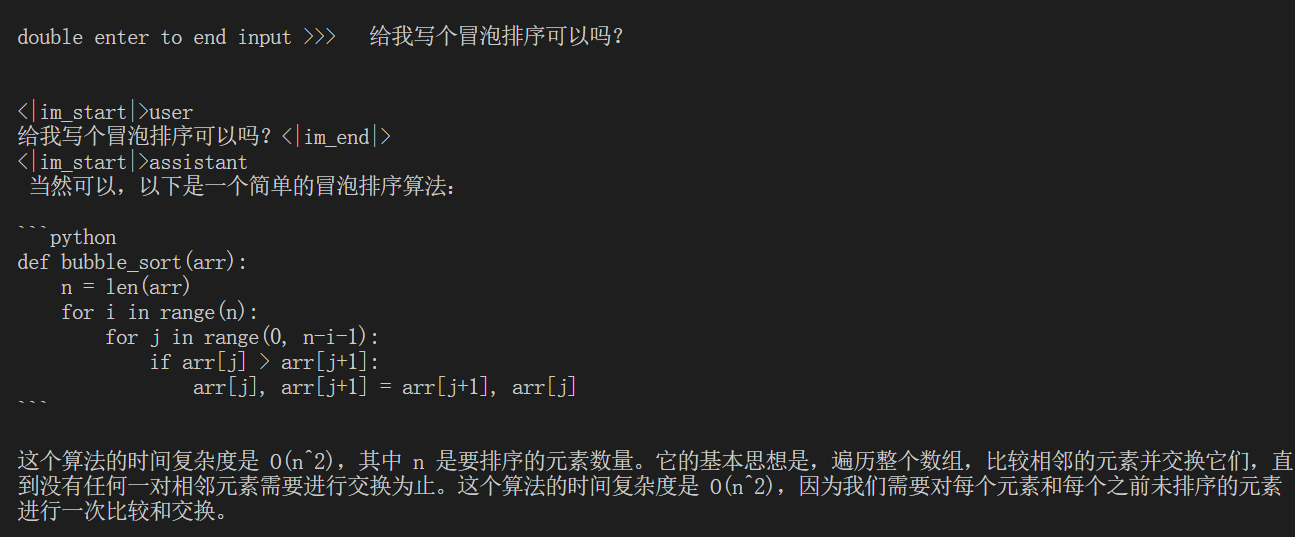
cache占到0.01后模型更聪明了(狗头)
lmdeploy lite auto_awq
/root/internlm2-chat-1_8b
–calib-dataset ‘ptb’
–calib-samples 128
–calib-seqlen 1024
–w-bits 4
–w-group-size 128
–work-dir /root/internlm2-chat-1_8b-4bit
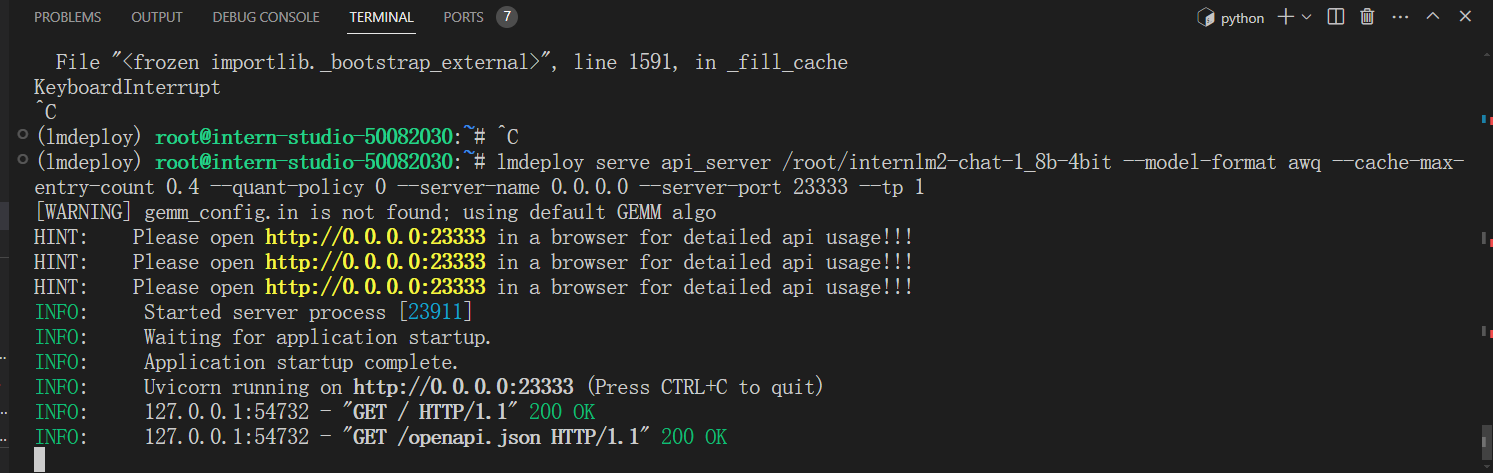
2.2 API Server + 量化 + 调整KV占比
lmdeploy serve api_server /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.4 --quant-policy 0 --server-name 0.0.0.0 --server-port 23333 --tp 1
命令行使用api
gradio使用api
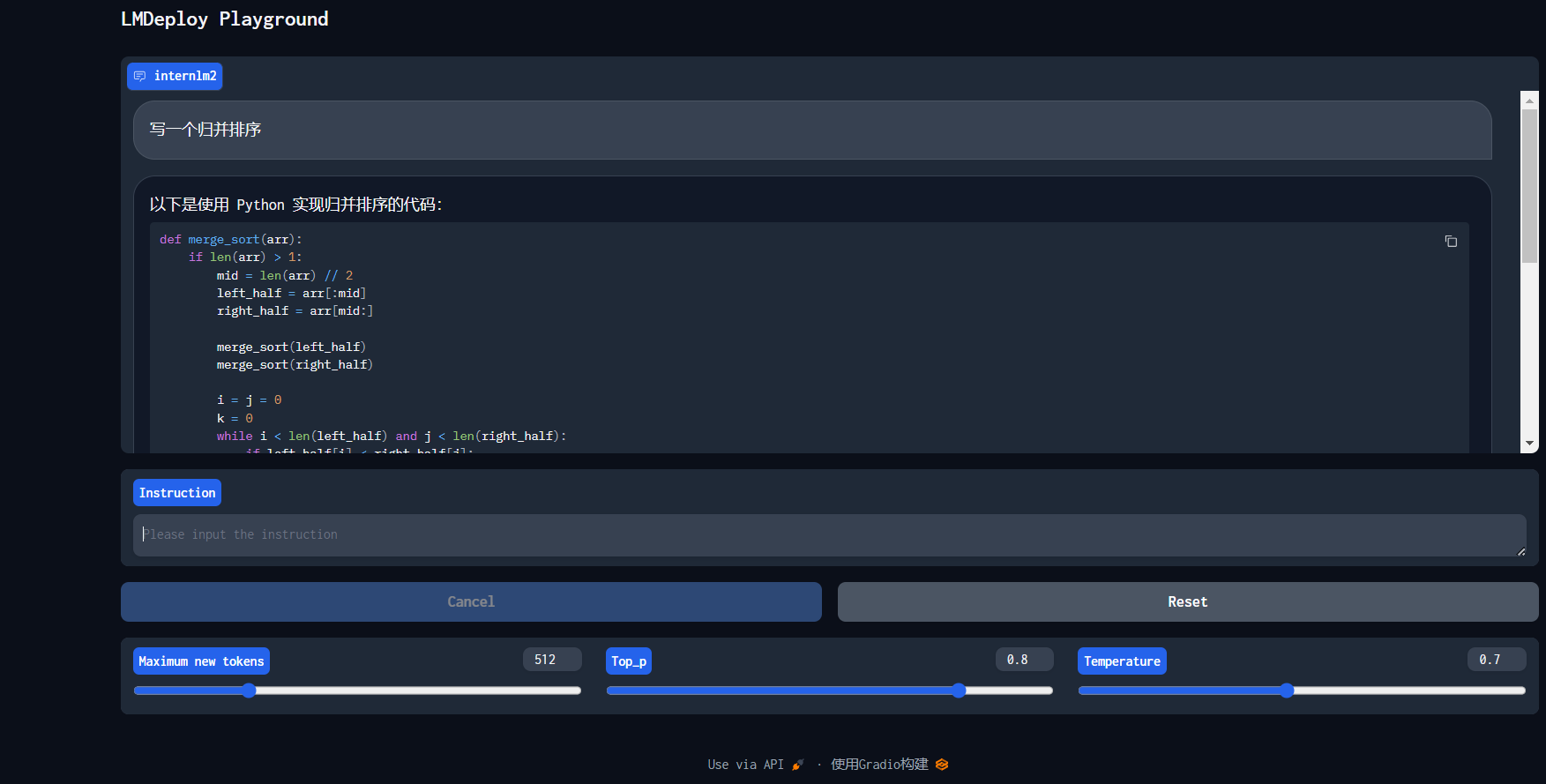
2.3 bug解决
启动api服务的时候,一直报错,在保证按步骤执行的前提下,以为这个报错涉及底层不知道怎么改,先做了后面不用api服务的。
但是lmdepoly,这一行命令我也不知道该怎么改,有点尬住。
然后群里的大佬让我用ssh,我心想也用了呀,为啥每个大佬都觉得是ssh的问题呢
忽然想到之前一直用cmd启动,这次用vscode启动,vscode直接Ctrl+右键点击,发现地址栏有点不对
然后输入了http://127.0.0.1:23333/,嘿你猜怎么着,成了
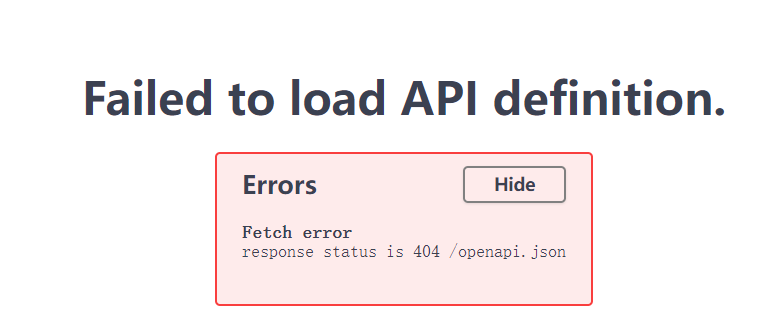
gradio部署
遇到报错:你遇到的错误是由于在使用 lmdeploy 配合 Gradio 时试图使用一个已经弃用的参数 concurrency_count。错误信息指出 concurrency_count 已被废弃,并给出了如何替代这个参数的建议。
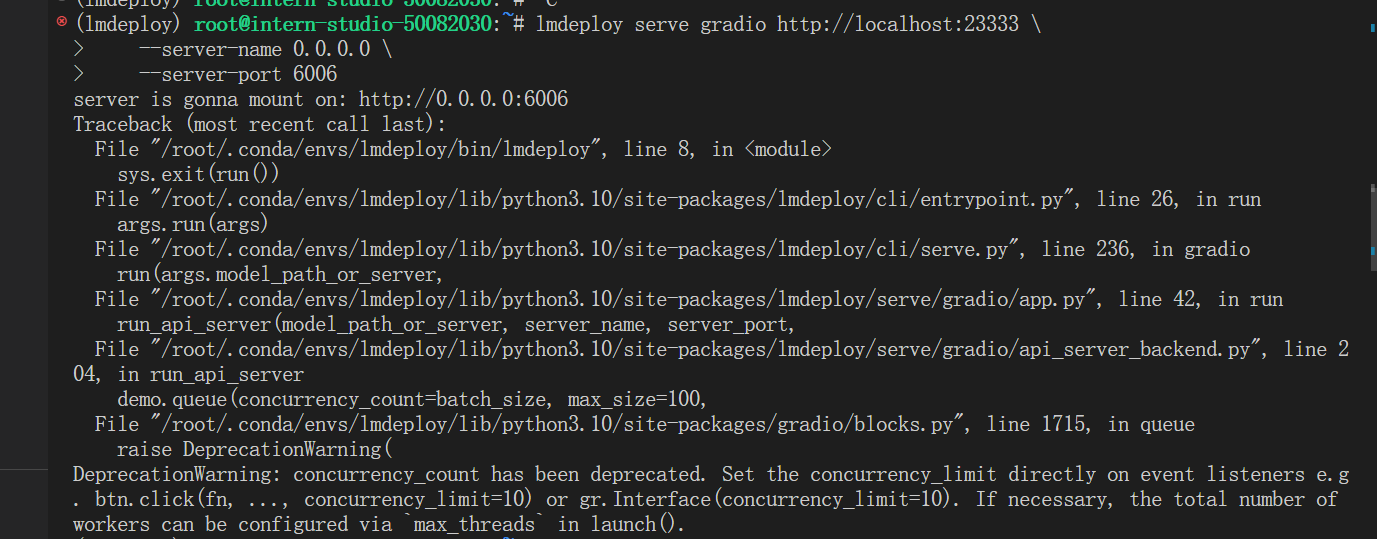
直接给gradio降版本:pip install gradio==3.43.0"
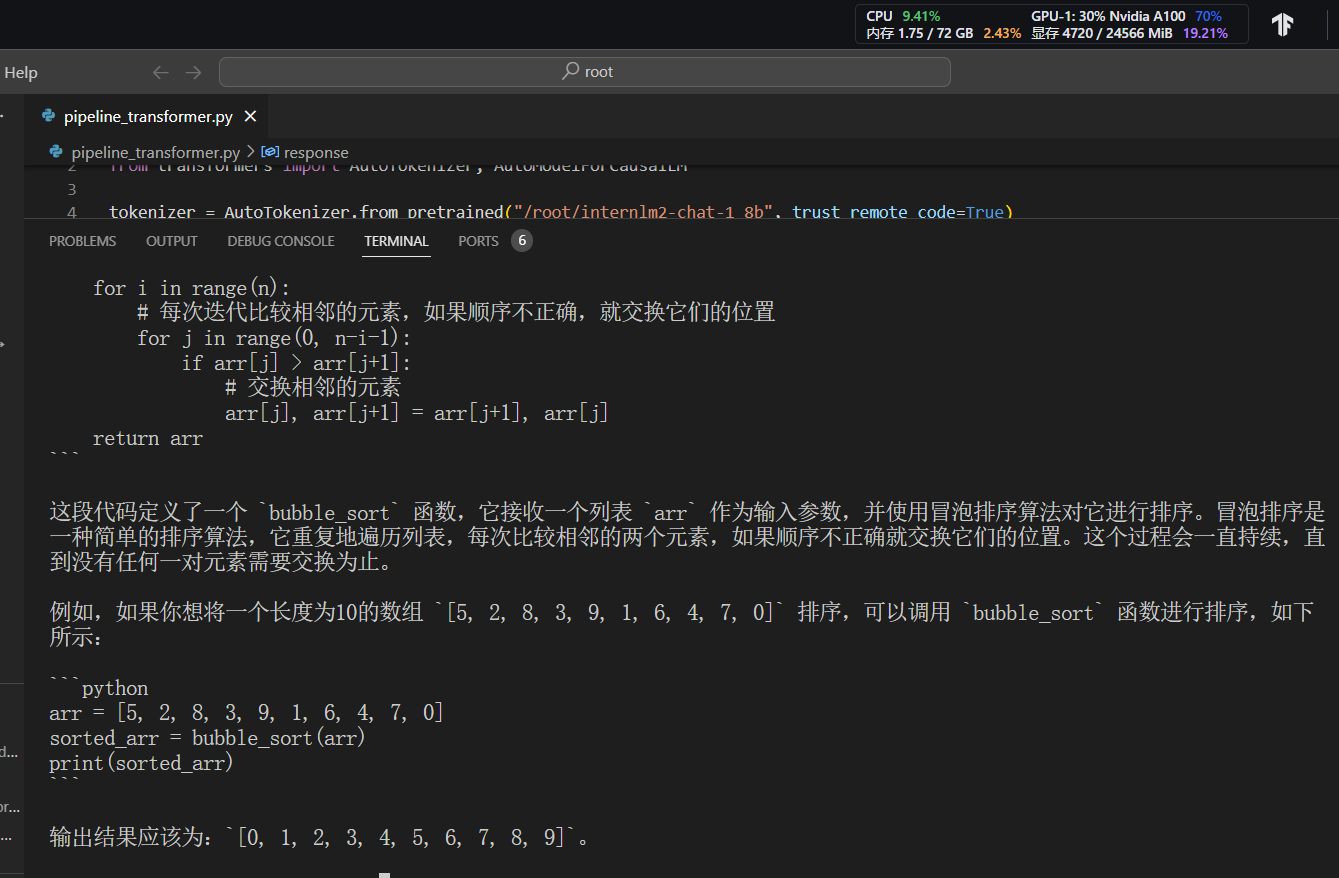
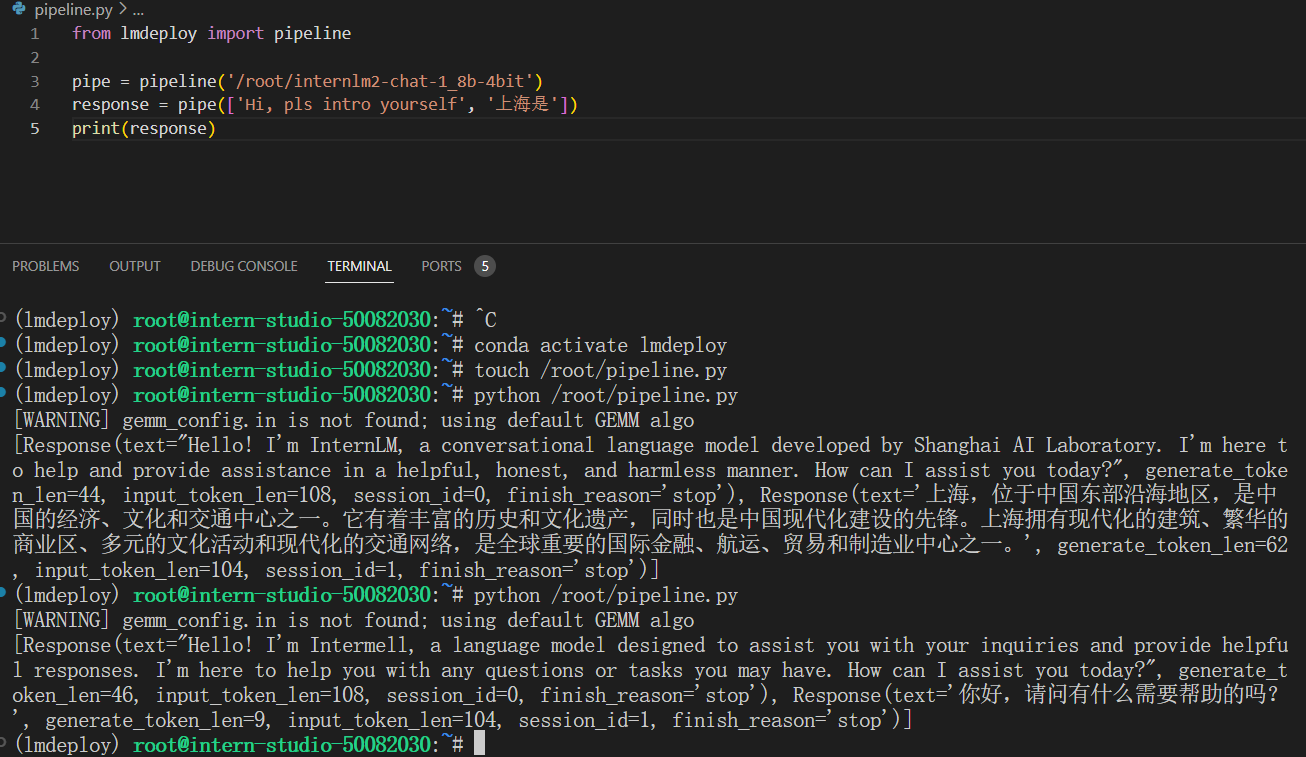
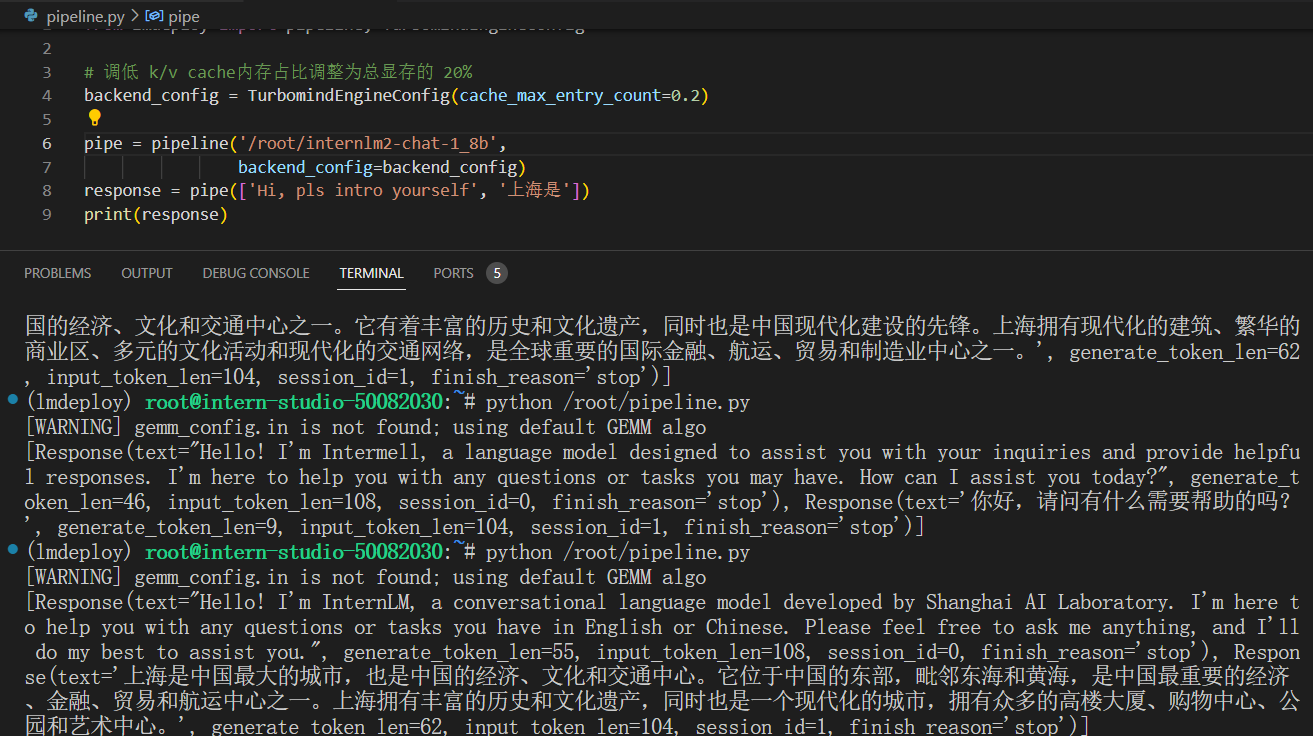
2.4 python代码集成运行模型
调成0.2 了,0.4无非改个数字
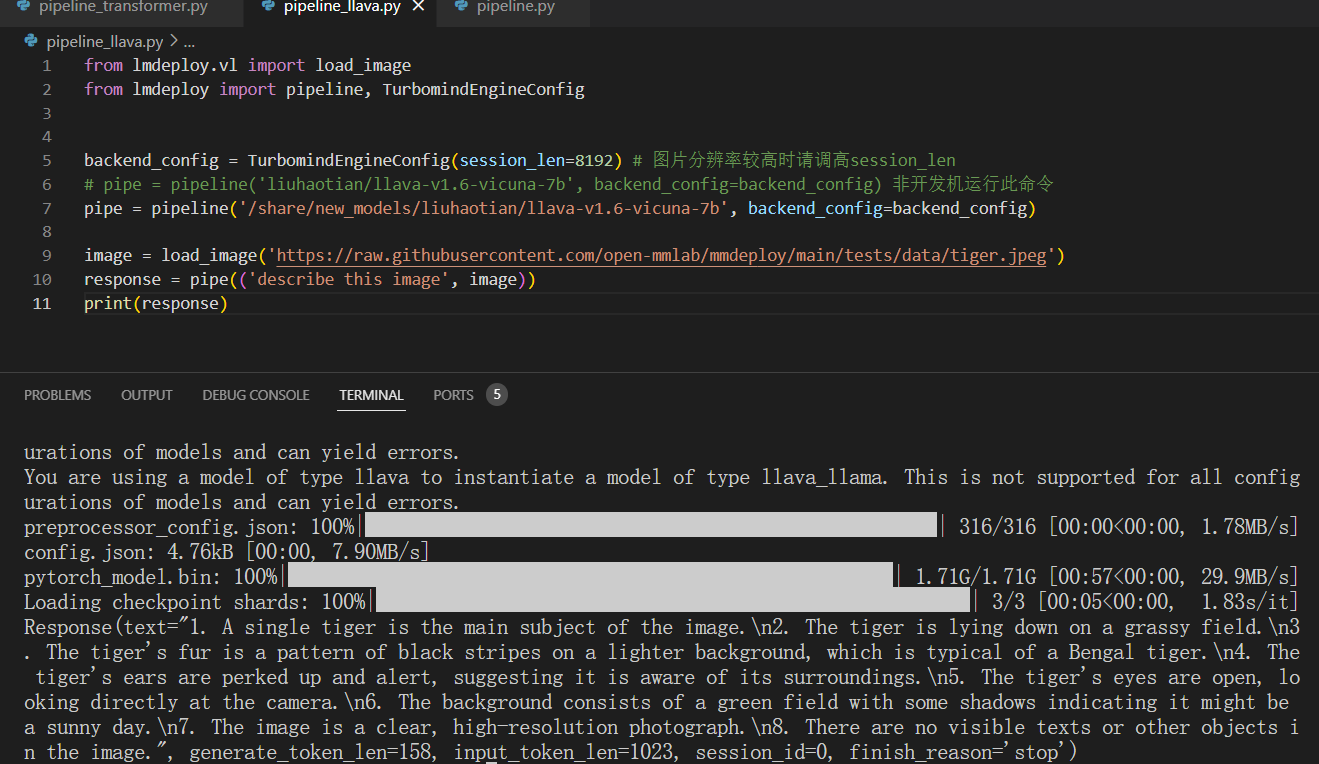
2. 5 运行多模态模型
lmdeploy运行多模态模型
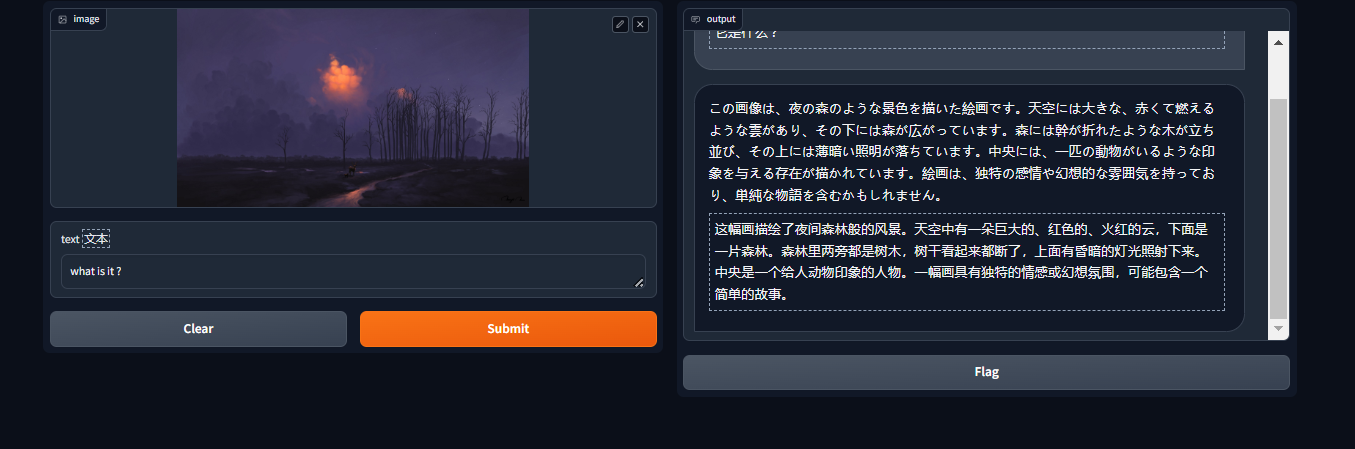
gradio运行(不知道为毛整了个日语翻译)
2.6 部署LmDeploy到OpenXLab
- 模型上传
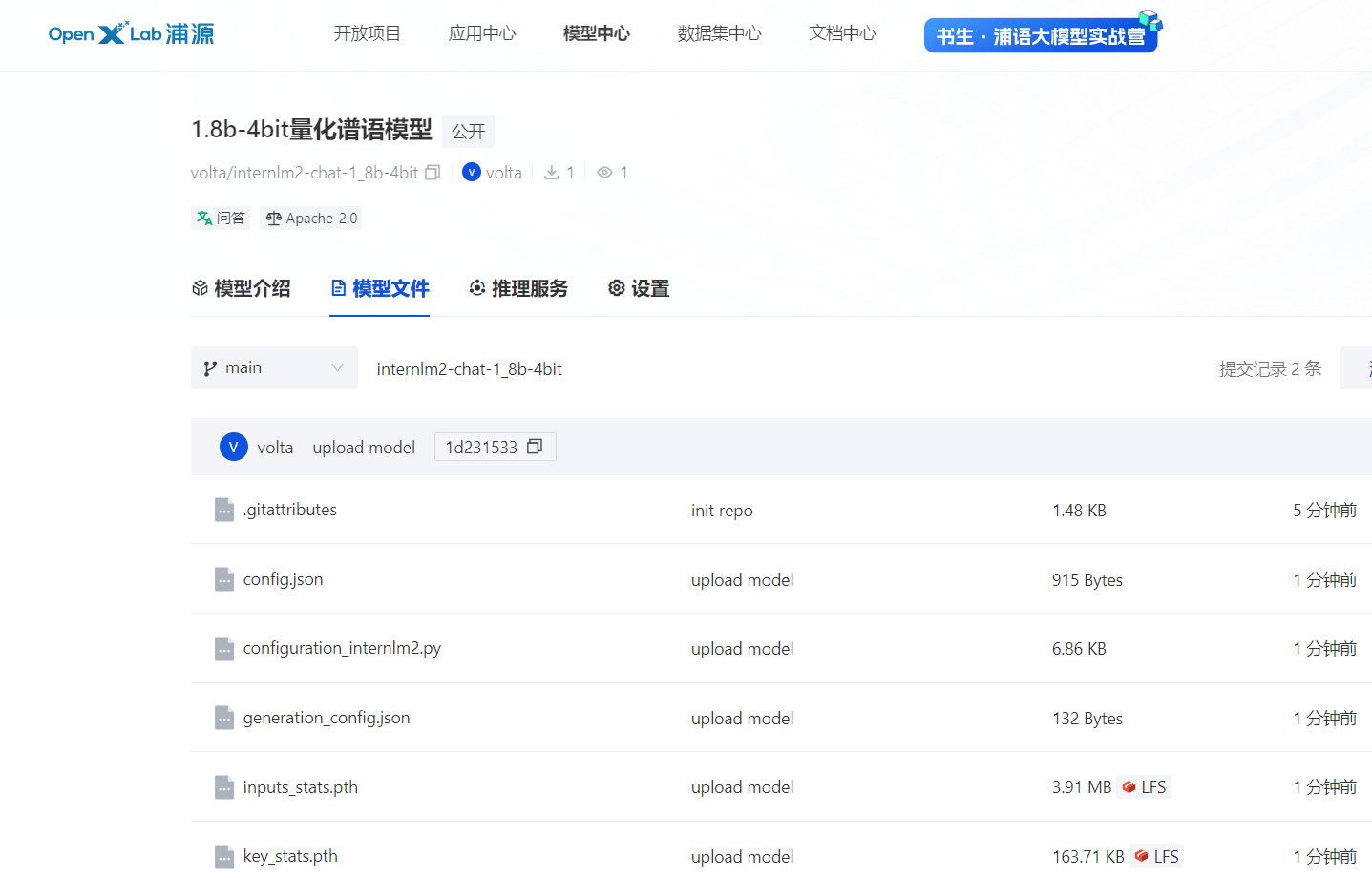
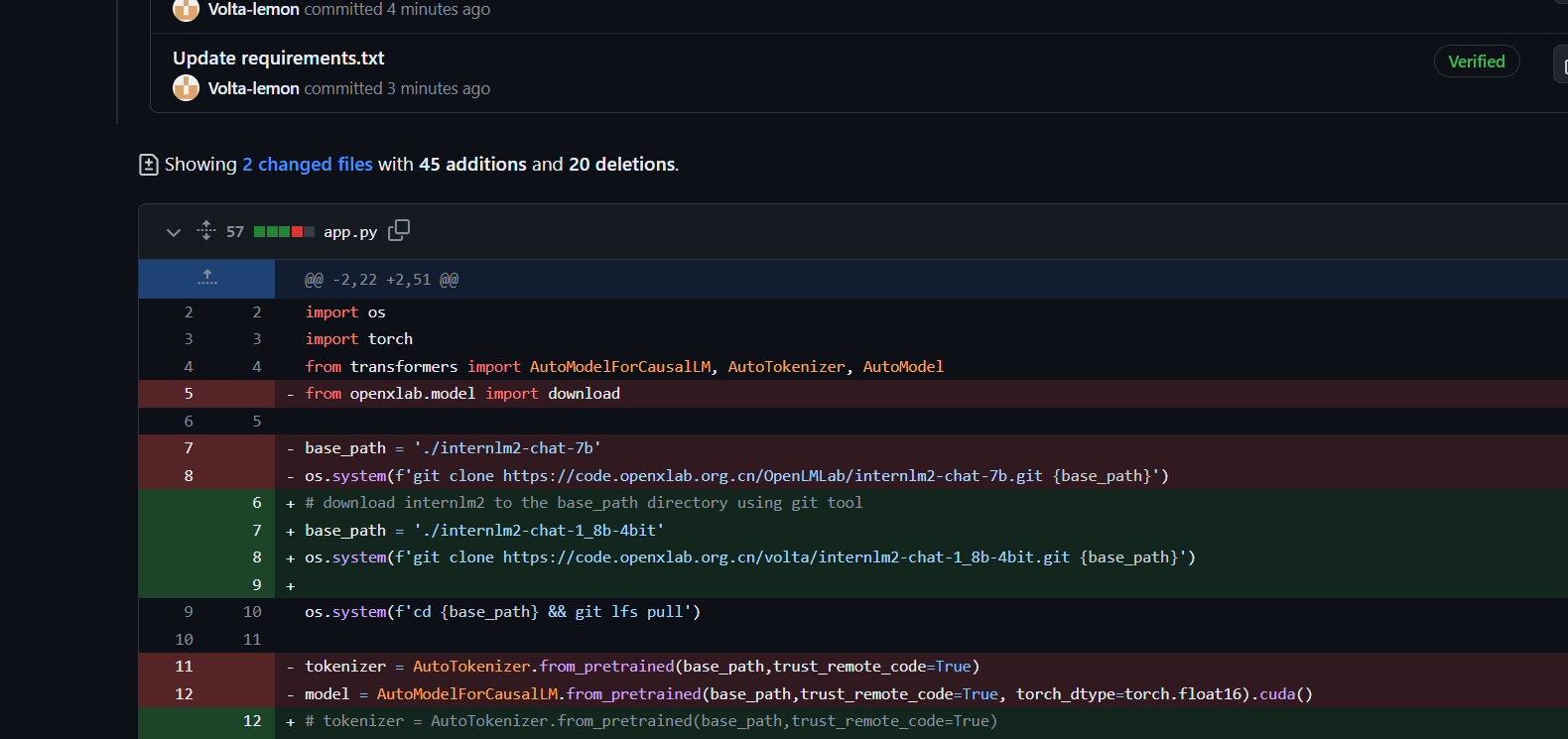
- github代码修改
直接在之前部署xtuner项目的基础上修改即可
- 应用构建
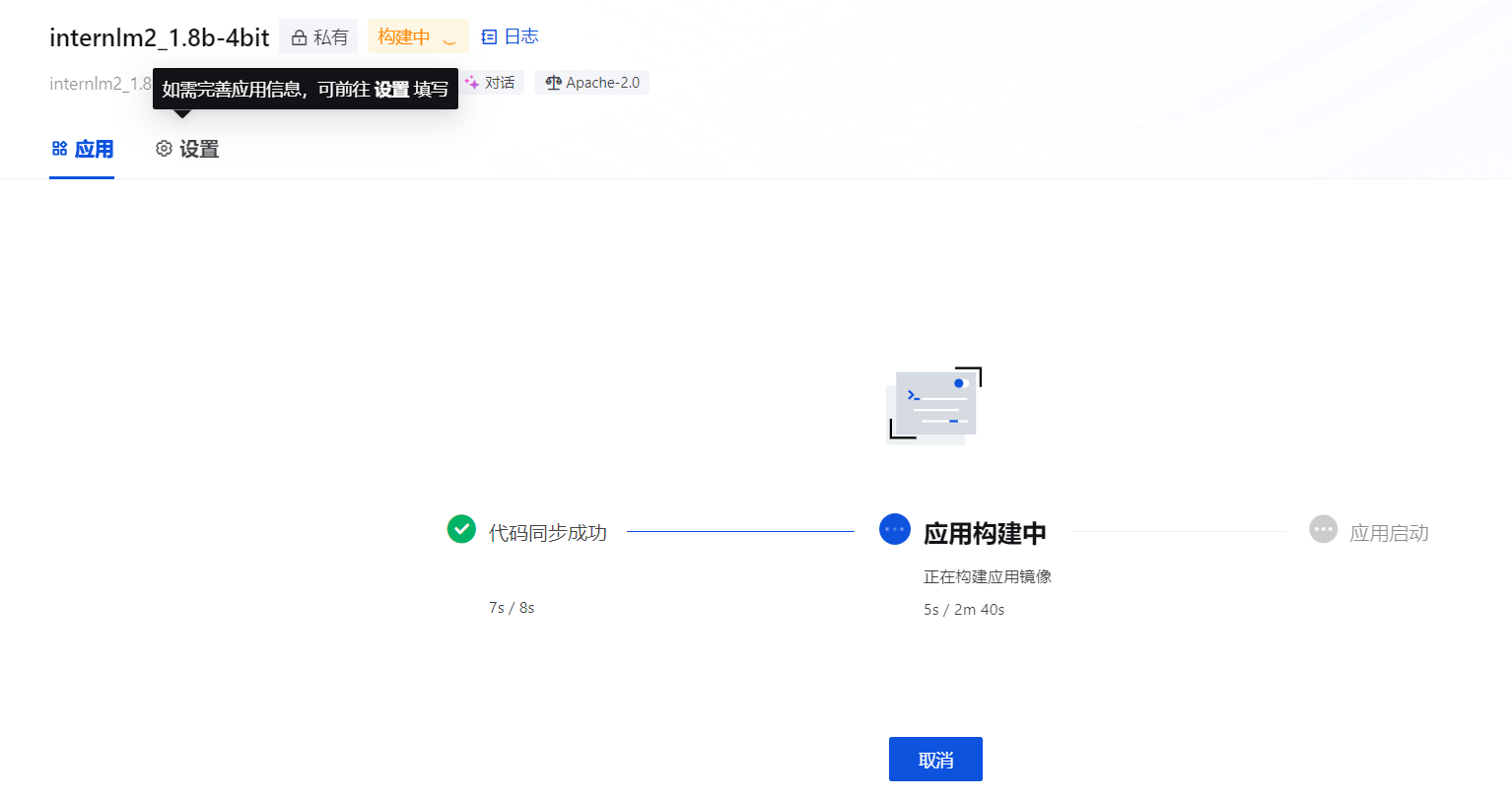
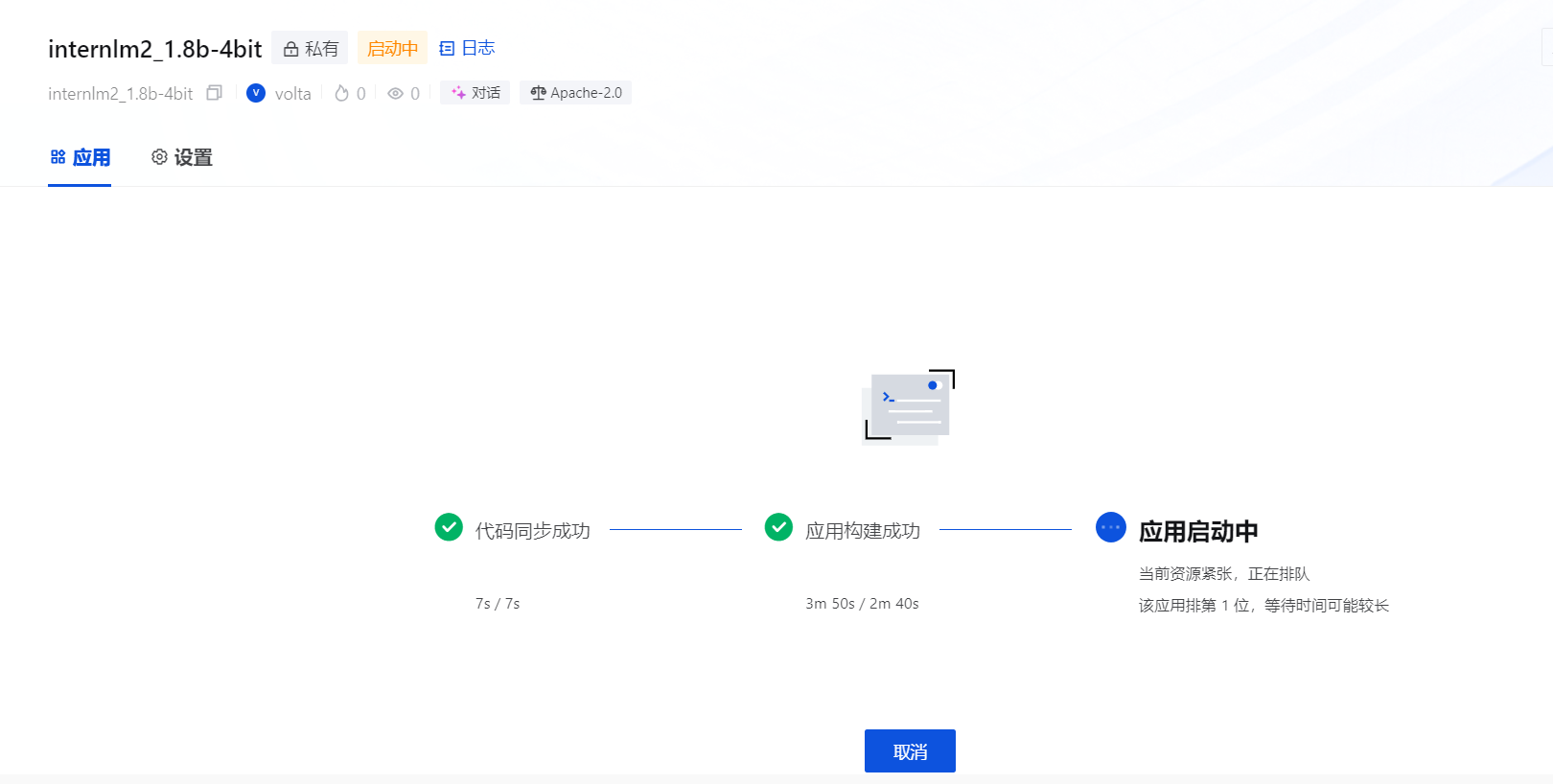
因为没有gpu了,无法启动起来,部署结束















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









