









目录
目标
基于
Hadoop
和
Hive
实现聊天数据统计分析,构建
聊天数据分析报表
需求
统计今日
总消息量
统计今日
每小时
消息量、发送和接收用户数
统计今日
各地区
发送消息数据量
统计今日发送消息和接收消息的
用户数
统计今日
发送消息最多的Top10用户
统计今日
接收消息最多的Top10用户
统计发送人的
手机型号分布情况
统计发送人的
设备操作系统分布情况
数据内容
数据大小:两个文件共14万条数据
列分隔符:
制表符
\t
数据字典及样例数据
|
消息时间
|
发件人
昵称
|
发件人
账号
|
发件人
性别
|
发件人
IP
|
发件人
系统
|
发件
人手
机型
号
|
发件人
网络制
式
|
发件人
GPS
|
收件人
昵称
|
收件人
IP
|
收件人
账号
|
收件人
系统
|
收件
人手
机型
号
|
收件人
网络制
式
|
收件人
GPS
|
收件人
性别
|
消息类型
| 双方距离 | 消息 |
| 2021-11-01 07:44:37 | 郯 乐 游 | 182513 8366359 | 男 | 195.188. 222.255 | IOS 9.0 | OPPO A11X | 5G | 123.257181, 48.807394 | 梁丘雨琴 | 136.66. 109.160 | 152369 9980735 | Android 7.0 | 华为 荣耀9X | 4G | 9.332566, 42.956064 | 女 | T E X T | 5.14 KM | 你如那出水的芙蓉,亭亭玉立[lizhigushicom]。你是那样地美,美得让我无法自拔,笑容如春天般清丽秀雅,秀发如柳丝细腻顺滑,眼眸如涟漪百媚丛生。宝贝,对我来说你是最好的。 |
建库建表
将dataGrip设置为hive适用的sql(选择Apache Hive):
创建数据库:
--------------1、建库-------------------
--如果数据库已存在就删除
drop database if exists db_msg cascade;
--创建数据库
create database db_msg;
--切换数据库
use db_msg;创建表:
--------------2、建表-------------------
--如果表已存在就删除
drop table if exists db_msg.tb_msg_source;
--建表
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容"
)
--指定分隔符为制表符
row format delimited fields terminated by '\t';在root/hivedata目录下存在数据文件:

数据加载:
--------------3、加载数据-------------------
--上传数据文件到node1服务器本地文件系统(HS2服务所在机器)
--shell: mkdir -p /root/hivedata
--加载数据到表中
load data local inpath '/root/hivedata/data1.tsv' into table db_msg.tb_msg_source;
load data local inpath '/root/hivedata/data2.tsv' into table db_msg.tb_msg_source;
--查询表 验证数据文件是否映射成功
select * from tb_msg_source limit 10;
--统计行数
select count(*) as cnt from tb_msg_source;
ETL数据清洗:
问题1:当前数据中,有一些数据的字段为空,不是合法数据
select
msg_time,
sender_name,
sender_gps
from db_msg.tb_msg_source
where length(sender_gps) = 0
limit 10;问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
select
msg_time
from db_msg.tb_msg_source
limit 10;问题3:需求中,需要对经度和维度构建地区的可视化地图,但是数据中GPS经纬度为一个字段,不好处理
select
sender_gps
from db_msg.tb_msg_source
limit 10;ETL的实现:
将Select语句的结果保存到新表中(利用sql的功能函数)
create table ... as select ... (在本次实验中很常用到!!!)
--ETL实现
--如果表已存在就删除
drop table if exists db_msg.tb_msg_etl;
--将Select语句的结果保存到新表中
create table db_msg.tb_msg_etl as
select
*,
substr(msg_time,0,10) as dayinfo, --获取天
substr(msg_time,12,2) as hourinfo, --获取小时
split(sender_gps,",")[0] as sender_lng, --提取经度
split(sender_gps,",")[1] as sender_lat --提取纬度
from db_msg.tb_msg_source
--过滤字段为空的数据
where length(sender_gps) > 0 ;
--验证ETL结果
select
msg_time,dayinfo,hourinfo,sender_gps,sender_lng,sender_lat
from db_msg.tb_msg_etl
limit 10;
新表在原有表的基础上新增了四列:

--验证ETL结果
select * from db_msg.tb_msg_etl;
select
msg_time,dayinfo,hourinfo,sender_gps,sender_lng,sender_lat
from db_msg.tb_msg_etl
limit 10; 
问题一:
--需求:统计今日总消息量
create table if not exists tb_rs_total_msg_cnt
comment "今日消息总量"
as
select
dayinfo,
count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo;
select * from tb_rs_total_msg_cnt;--结果验证
问题二:统计今日每小时消息量、发送和接收用户数
--需求:统计今日每小时消息量、发送和接收用户数
create table if not exists tb_rs_hour_msg_cnt
comment "每小时消息量趋势"
as
select
dayinfo,
hourinfo,
count(*) as total_msg_cnt,
count(distinct sender_account) as sender_usr_cnt,
count(distinct receiver_account) as receiver_usr_cnt
from db_msg.tb_msg_etl
group by dayinfo,hourinfo;
select * from tb_rs_hour_msg_cnt;--结果验证
问题三:统计今日各地区发送消息数据量
--需求:统计今日各地区发送消息数据量
create table if not exists tb_rs_loc_cnt
comment "今日各地区发送消息总量"
as
select
dayinfo,
sender_gps,
cast(sender_lng as double) as longitude,
cast(sender_lat as double) as latitude,
count(*) as total_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,sender_gps,sender_lng,sender_lat;
select * from tb_rs_loc_cnt; --结果验证

问题四:统计今日发送消息和接收消息的用户数
--需求:统计今日发送消息和接收消息的用户数
create table if not exists tb_rs_usr_cnt
comment "今日发送消息人数、接受消息人数"
as
select
dayinfo,
count(distinct sender_account) as sender_usr_cnt,
count(distinct receiver_account) as receiver_usr_cnt
from db_msg.tb_msg_etl
group by dayinfo;
select * from tb_rs_usr_cnt; --结果验证

问题五:统计今日发送消息最多的Top10用户
--需求:统计今日发送消息最多的Top10用户
create table if not exists tb_rs_susr_top10
comment "发送消息条数最多的Top10用户"
as
select
dayinfo,
sender_name as username,
count(*) as sender_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,sender_name
order by sender_msg_cnt desc
limit 10;
select * from tb_rs_susr_top10; --结果验证 
问题六:统计今日接收消息最多的Top10用户
--需求:统计今日接收消息最多的Top10用户
create table if not exists tb_rs_rusr_top10
comment "接受消息条数最多的Top10用户"
as
select
dayinfo,
receiver_name as username,
count(*) as receiver_msg_cnt
from db_msg.tb_msg_etl
group by dayinfo,receiver_name
order by receiver_msg_cnt desc
limit 10;
select * from tb_rs_rusr_top10; --结果验证
问题七:统计发送人的手机型号分布情况
--需求:统计发送人的手机型号分布情况
create table if not exists tb_rs_sender_phone
comment "发送人的手机型号分布"
as
select
dayinfo,
sender_phonetype,
count(distinct sender_account) as cnt
from tb_msg_etl
group by dayinfo,sender_phonetype;
select * from tb_rs_sender_phone; --结果验证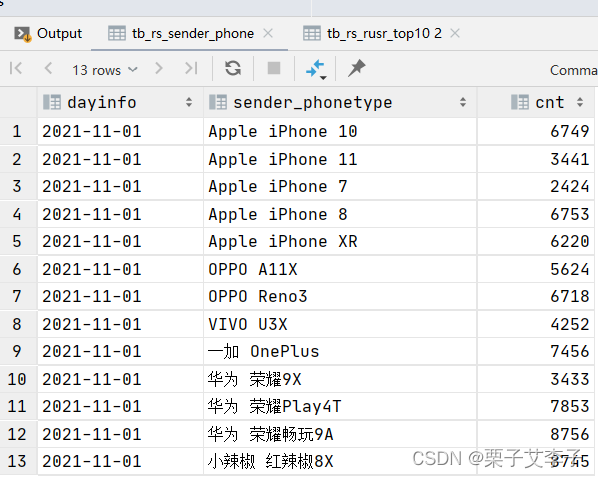
问题八:统计发送人的设备操作系统分布情况
--需求:统计发送人的设备操作系统分布情况
create table if not exists tb_rs_sender_os
comment "发送人的OS分布"
as
select
dayinfo,
sender_os,
count(distinct sender_account) as cnt
from tb_msg_etl
group by dayinfo,sender_os;
select * from tb_rs_sender_os; --结果验证

可视化
FineBI连接Hive,所需要的hive插件在资源包:

 FineBI连接Hive
FineBI连接Hive
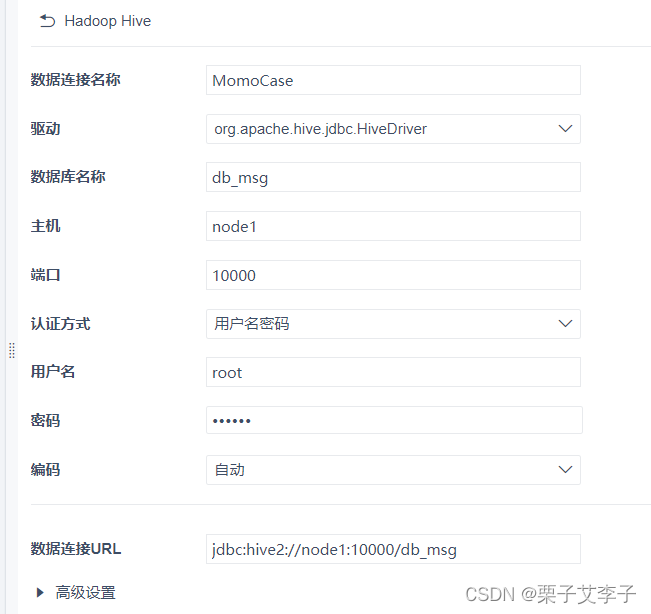
将表导入FineBI:

第一个图:
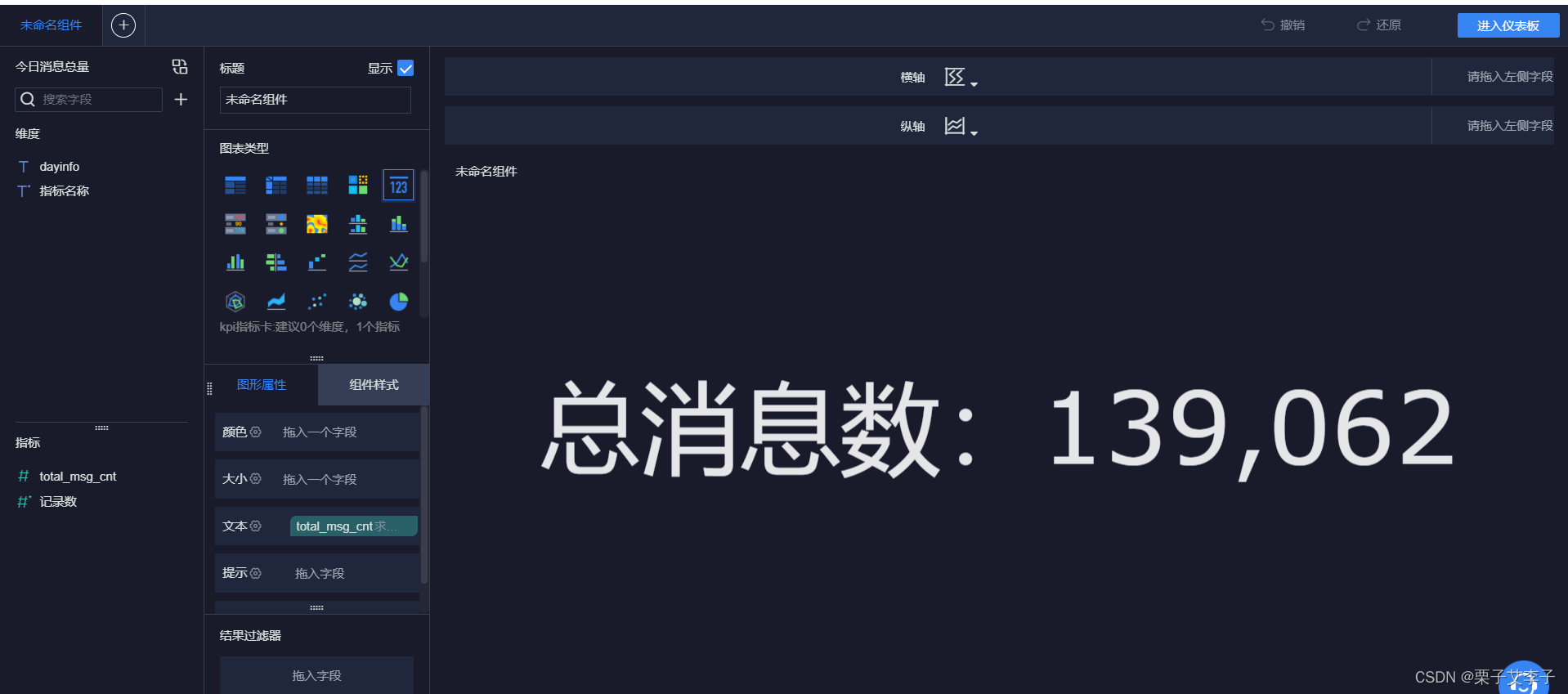 FineBI文本设置
FineBI文本设置
同理添加总发送消息人数以及总接收消息人数,实现效果:

设置经纬度:

组件样式:

添加雷达图:
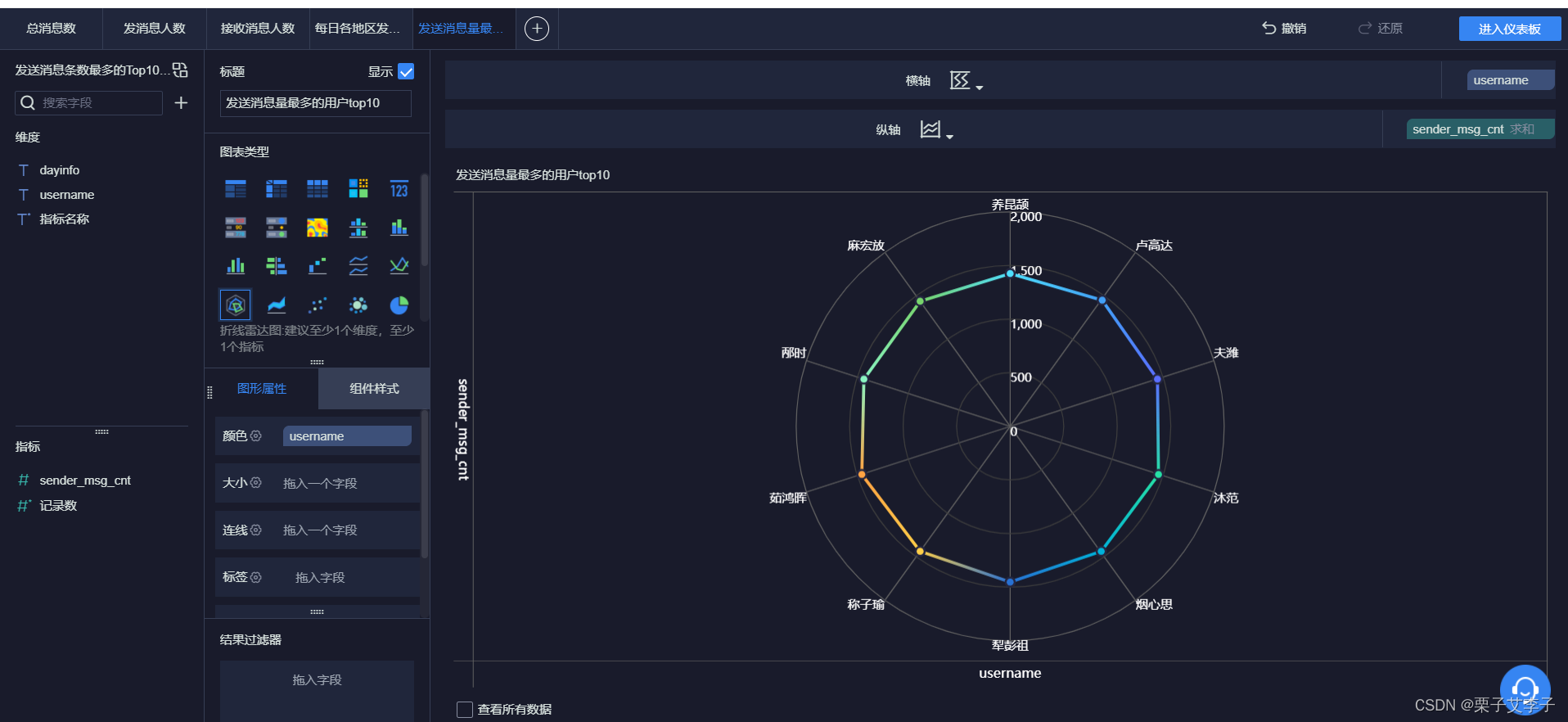
玫瑰图:

组件设置:

词云图(组件设置):

折线图(组件设置):

最终实现效果:
















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









