







 本文详细介绍了Elasticsearch的Mapping概念,包括字段定义、数据类型(如text、keyword、数值型、日期、布尔和范围类型)以及复杂数据类型。此外,还讨论了Mapping的参数,如analyzer、boost、dynamic、copy_to等,并举例说明如何设置和使用。文章强调了Mapping在优化索引和查询性能方面的重要性。
本文详细介绍了Elasticsearch的Mapping概念,包括字段定义、数据类型(如text、keyword、数值型、日期、布尔和范围类型)以及复杂数据类型。此外,还讨论了Mapping的参数,如analyzer、boost、dynamic、copy_to等,并举例说明如何设置和使用。文章强调了Mapping在优化索引和查询性能方面的重要性。
一、什么是Mapping
类似于数据库中的表结构定义,主要作用如下:
- 定义Index下字段名(Field Name)
- 定义字段的类型,比如数值型,字符串型、布尔型等
- 定义倒排索引的相关配置,比如是否索引、记录postion等
需要注意的是,在索引中定义太多字段可能会导致索引膨胀,出现内存不足和难以恢复的情况,下面有几个设置:
- index.mapping.total_fields.limit:一个索引中能定义的字段的最大数量,默认是 1000
- index.mapping.depth.limit:字段的最大深度,以内部对象的数量来计算,默认是20
- index.mapping.nested_fields.limit:索引中嵌套字段的最大数量,默认是50
一个 Mapping 属于一个索引的 Type,在 7.0 之后版本一个索引只有一个 Type(_doc)
- 一个 Type 有一个 Mapping 定义
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
二、数据类型
核心数据类型
(1) 字符串:text
用于全文索引,该类型的字段将通过分词器进行分词,最终用于构建索引。
(2) 字符串:keyword
不分词,只能搜索该字段的完整的值,只用于 filtering。
(3) 数值型
- long:有符号64-bit integer:-2^63 ~ 2^63 - 1
- integer:有符号32-bit integer,-2^31 ~ 2^31 - 1
- short:有符号16-bit integer,-32768 ~ 32767
- byte: 有符号8-bit integer,-128 ~ 127
- double:64-bit IEEE 754 浮点数
- float:32-bit IEEE 754 浮点数
- half_float:16-bit IEEE 754 浮点数
- scaled_float
(4) 布尔:boolean
值:false, "false", true, "true"
(5) 日期:date
由于Json没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型。
在 Elasticsearch 中可以表达成:
- 日期格式化的字符串,比如: “2015-01-01” 或者 “2015/01/01 12:10:30”;
- 毫秒级别的 long 类型;
- 秒级别的 integer 类型
比如: 1515150699465, 1515150699;
实际上不管日期以何种格式写入,在 ES 内部都会先换成 UTC 时间并存储为 long 类型。
日期格式可以自定义,如果没有指定的话会使用以下的默认格式:“strict_date_optional_time||epoch_millis”
date 类型的查询在内部转为 long 处理,聚合返回的结果再根据字段定义的格式转为字符串输出。注意,日期将始终呈现为字符串,即使它们最初是在 JSON 文档中作为 long 串提供的。
多日期格式设置:
{
"mappings": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}date字段还可以设置的参数有:
- ignore_malformed 是否忽略非正常格式的值,默认 false,抛出异常。
- index 是否可被查询 默认 true。
- null_value 默认值 null。
- store 默认 false
常用的format:
- epoch_millis
- epoch_second
(6) 二进制:binary
该类型的字段把值当做经过 base64 编码的字符串,默认不存储,且不可搜索。
(7) 范围类型
范围类型表示值是一个范围,而不是一个具体的值。
譬如 age 的类型是 integer_range,那么值可以是 {"gte" : 10, "lte" : 20};搜索 "term" : {"age": 15} 可以搜索该值;搜索 "range": {"age": {"gte":11, "lte": 15}} 也可以搜索到。
range参数 relation 设置匹配模式:
- INTERSECTS :默认的匹配模式,只要搜索值与字段值有交集即可匹配到
- WITHIN:字段值需要完全包含在搜索值之内,也就是字段值是搜索值的子集才能匹配
- CONTAINS:与WITHIN相反,只搜索字段值包含搜索值的文档
范围类型有以下这些:
- integer_range
- float_range
- long_range
- double_range
- date_range:64-bit 无符号整数,时间戳(单位:毫秒)
- ip_range:IPV4 或 IPV6 格式的字符串
# 创建range索引
PUT range_index
{
"mappings": {
"_doc": {
"properties": {
"expected_attendees": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
# 插入一个文档
PUT range_index/_doc/1
{
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-05"
}
}
# 12在 10~20的范围内,可以搜索到文档1
GET range_index/_search
{
"query" : {
"term" : {
"expected_attendees" : {
"value": 12
}
}
}
}
# within可以搜索到文档
# 可以修改日期,然后分别对比CONTAINS,WITHIN,INTERSECTS的区别
GET range_index/_search
{
"query" : {
"range" : {
"time_frame" : {
"gte" : "2015-11-02",
"lte" : "2015-11-03",
"relation" : "within"
}
}
}
}复杂数据类型
(1) 数组类型 Array
- 字符串数组 [ "one", "two" ]
- 整数数组 [ 1, 2 ]
- 数组的数组 [ 1, [ 2, 3 ]],相当于 [ 1, 2, 3 ]
- Object对象数组 [ { "name": "Mary", "age": 12 }, { "name": "John", "age": 10 }]
- 同一个数组只能存同类型的数据,不能混存,譬如 [ 10, "some string" ] 是错误的
- 数组中的 null 值将被 null_value 属性设置的值代替或者被忽略
- 空数组 [] 被当做 missing field 处理
(2) 对象类型Object
- 对象类型可能有内部对象
- 被索引的形式为:manager.name.first
# tags字符串数组,lists 对象数组
PUT my_index/_doc/1
{
"message": "some arrays in this document...",
"tags": [ "elasticsearch", "wow" ],
"lists": [
{
"name": "prog_list",
"description": "programming list"
},
{
"name": "cool_list",
"description": "cool stuff list"
}
]
}
地理位置数据
(1) geo_point
地理位置,其值可以有如下四中表现形式:
- object对象:"location": {"lat": 41.12, "lon": -71.34}
- 字符串:"location": "41.12,-71.34"
- geohash:"location": "drm3btev3e86"
- 数组:"location": [ -71.34, 41.12 ]
多字段特性
- 允许对同一个字段采用不同的配置,比如分词,常见例子如对人名实现拼音搜索,只需要在人名中新增一个子字段为 pinyin 即可
- 通过参数 fields 设置
设置Mapping

GET my_index/_mapping
# 结果
{
"my_index": {
"mappings": {
"doc": {
"properties": {
"age": {
"type": "integer"
},
"created": {
"type": "date"
},
"name": {
"type": "text"
},
"title": {
"type": "text"
}
}
}
}
}
}三、Mapping参数
analyzer
分词器,默认为standard analyzer,当该字段被索引和搜索时对字段进行分词处理。
boost
字段权重,默认为1.0
dynamic
- Mapping中的字段类型一旦设定后,禁止直接修改,原因是:Lucene实现的倒排索引生成后不允许修改。
- 只能新建一个索引,然后reindex数据。
- 默认允许新增字段。
- 通过dynamic参数来控制字段的新增:① true(默认)允许自动新增字段。 ② false 不允许自动新增字段,但是文档可以正常写入,但无法对新增字段进行查询等操作。③ strict 文档不能写入,报错。
PUT my_index
{
"mappings": {
"_doc": {
"dynamic": false,
"properties": {
"user": {
"properties": {
"name": {
"type": "text"
},
"social_networks": {
"dynamic": true,
"properties": {}
}
}
}
}
}
}
}定义后my_index这个索引下不能自动新增字段,但是在user.social_networks下可以自动新增子字段。
copy_to
- 将该字段复制到目标字段,实现类似_all的作用。
- 不会出现在_source中,只用来搜索
DELETE my_index
PUT my_index
{
"mappings": {
"doc": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"last_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}
}
PUT my_index/doc/1
{
"first_name": "John",
"last_name": "Smith"
}
GET my_index/_search
{
"query": {
"match": {
"full_name": {
"query": "John Smith",
"operator": "and"
}
}
}
}index
控制当前字段是否索引,默认为true,即记录索引,false不记录,即不可搜索。
index_options
- index_options参数控制将哪些信息添加到倒排索引,以用于搜索和突出显示,可选的值有:docs,freqs,positions,offsets。
- docs:只索引 doc id
- freqs:索引 doc id 和词频,平分时可能要用到词频
- positions:索引 doc id、词频、位置,做 proximity or phrase queries 时可能要用到位置信息
- offsets:索引doc id、词频、位置、开始偏移和结束偏移,高亮功能需要用到offsets
fielddata
- 是否预加载 fielddata,默认为false
- Elasticsearch第一次查询时完整加载这个字段所有 Segment 中的倒排索引到内存中
- 如果我们有一些 5 GB 的索引段,并希望加载 10 GB 的 fielddata 到内存中,这个过程可能会要数十秒
- 将 fielddate 设置为 true ,将载入 fielddata 的代价转移到索引刷新的时候,而不是查询时,从而大大提高了搜索体验
eager_global_ordinals
是否预构建全局序号,默认false
fields
- 该参数的目的是为了实现 multi-fields
- 一个字段,多种数据类型
- 譬如:一个字段 city 的数据类型为 text ,用于全文索引,可以通过 fields 为该字段定义 keyword 类型,用于排序和聚合
# 设置 mapping
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}
# 插入两条数据
PUT my_index/_doc/1
{
"city": "New York"
}
PUT my_index/_doc/2
{
"city": "York"
}
# 查询,city用于全文索引 match,city.raw用于排序和聚合
GET my_index/_search
{
"query": {
"match": {
"city": "york"
}
},
"sort": {
"city.raw": "asc"
},
"aggs": {
"Cities": {
"terms": {
"field": "city.raw"
}
}
}
}format
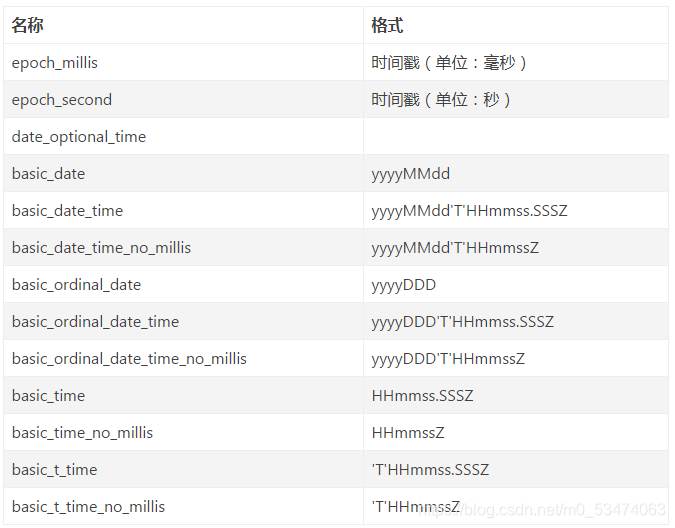
由于JSON没有date类型,Elasticsearch预先通过format参数定义时间格式,将匹配的字符串识别为date类型,转换为时间戳(单位:毫秒)
format默认为:strict_date_optional_time||epoch_millis
Elasticsearch内建的时间格式:
properties
用于_doc,object和nested类型的字段定义子字段
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"manager": {
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
},
"employees": {
"type": "nested",
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
}
}
}
}
}
PUT my_index/_doc/1
{
"region": "US",
"manager": {
"name": "Alice White",
"age": 30
},
"employees": [
{
"name": "John Smith",
"age": 34
},
{
"name": "Peter Brown",
"age": 26
}
]
}
normalizer
-
与 analyzer 类似,只不过 analyzer 用于 text 类型字段,分词产生多个 token,而 normalizer 用于 keyword 类型,只产生一个 token(整个字段的值作为一个token,而不是分词拆分为多个token)
-
定义一个自定义 normalizer,使用大写uppercase过滤器
PUT test_index_4
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"type": "custom",
"char_filter": [],
"filter": ["uppercase", "asciifolding"]
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"foo": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}
}
# 插入数据
POST test_index_4/_doc/1
{
"foo": "hello world"
}
POST test_index_4/_doc/2
{
"foo": "Hello World"
}
POST test_index_4/_doc/3
{
"foo": "hello elasticsearch"
}
# 搜索hello,结果为空,而不是3条!!
GET test_index_4/_search
{
"query": {
"match": {
"foo": "hello"
}
}
}
# 搜索 hello world,结果2条,1 和 2
GET test_index_4/_search
{
"query": {
"match": {
"foo": "hello world"
}
}
}其他字段
(1) coerce
强制类型转换,把json中的值转为ES中字段的数据类型,譬如:把字符串"5"转为integer的5。
coerce默认为 true。
如果coerce设置为 false,当json的值与es字段类型不匹配将会 rejected。
通过 "settings": { "index.mapping.coerce": false } 设置索引的 coerce。
(2) enabled
- 是否索引,默认为 true
- 可以在_doc和字段两个粒度进行设置
(3) ignore_above
- 设置能被索引的字段的长度
- 超过这个长度,该字段将不被索引,所以无法搜索,但聚合的terms可以看到
(4) null_value
- 该字段定义遇到null值时的处理策略,默认为Null,即空值,此时ES会忽略该值
- 通过设定该值可以设定字段为 null 时的默认值
(5) ignore_malformed
- 当数据类型不匹配且 coerce 强制转换时,默认情况会抛出异常,并拒绝整个文档的插入
- 若设置该参数为 true,则忽略该异常,并强制赋值,但是不会被索引,其他字段则照常
(6) norms
- norms 存储各种标准化因子,为后续查询计算文档对该查询的匹配分数提供依据
- norms 参数对评分很有用,但需要占用大量的磁盘空间
- 如果不需要计算字段的评分,可以取消该字段 norms 的功能
(7) position_increment_gap
- 与 proximity queries(近似查询)和 phrase queries(短语查询)有关
- 默认值 100。
(8) search_analyzer
- 搜索分词器,查询时使用。
- 默认与 analyzer 一样。
(9) similarity
- 设置相关度算法,ES5.x 和 ES6.x 默认的算法为 BM25
- 另外也可选择 classic 和 boolean
(10) store
- store 的意思是:是否在 _source 之外在独立存储一份,默认值为 false
- es在存储数据的时候把json对象存储到"_source"字段里,"_source"把所有字段保存为一份文档存储(读取需要1次IO),要取出某个字段则通过 source filtering 过滤
- 当字段比较多或者内容比较多,并且不需要取出所有字段的时候,可以把特定字段的store设置为true单独存储(读取需要1次IO),同时在_source设置exclude
(11) term_vector:与倒排索引相关


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











