







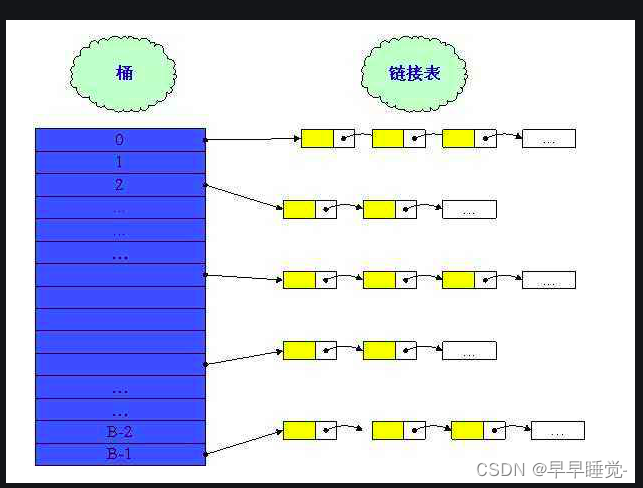
哈希桶
实际上哈希桶是解决哈希表冲突的一种方法。常见的解决冲突的两种方法:1、开链法 2、开放定址法。
不同的数据通过一套相同的哈希算法可能得到相同的Key值,就是所谓的哈希冲突,哈希桶则通过以链表的方式去处理冲突的问题
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable
{
public:
//主体实现
private:
std::vector<Node*> _Tables;
size_t _n = 0;
};
//链表结点类型
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
默认哈希函数
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
// 特化
template<>
struct Hash < string >
{
size_t operator()(const string& s)
{
// BKDR
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
HashTable_Linkhash
1.插入操作
bool Insert(const T& data )
{
KeyOfT kot;//后文会有介绍
HashFunc hf;//哈希函数 通过仿函数传入
//if语句中为扩容操作
// 负载因子到0.7,就扩容
// 负载因子越小,冲突概率越低,效率越高,空间浪费越多
// 负载因子越大,冲突概率越高,效率越低,空间浪费越少
if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7)
{
int newSize = 2 * _n;
std::vector<Node*> newTables;
newTables.resize(newSize);
for (size_t i = 0; i < _Tables.size(); ++i)//将哈希桶中的数据转移到新的哈希桶
{
Node* cur = _Tables[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hf(kot(cur->_data)) % newTables.size();
cur->_next = newTables[index];
newTables[index] = cur;
cur = next;
}
_Tables[i] = nullptr;
}
_Tables.swap(newTables);//交换数据 newTables离开Insert函数作用域被析构
}
size_t index = hf(kot(data)) % _Tables.size(); //寻找要插入哈希桶的下标
Node* newnode = new Node(data); //单链表头插法
newnode->_next = _Tables[index];
_Tables[index] = newnode;
++_n;
return true;
}
2.删除操作
bool Erase(const K& key)
{
if (_Tables.empty())
{
return false;
}
HashFunc hf;
KeyOfT kot;
size_t index = hf(key) % _Tables.size();
Node* prev = nullptr;//记录待删除结点的上一个结点
Node* cur = _Tables[index];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr) // 头删
{
_Tables[index] = cur->_next;
}
else // 中间删除
{
prev->_next = cur->_next;
}
--_n;
delete cur;
return true;
}
else//进行下一次查找
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
3.查找操作
查找查找和删除的逻辑基本一致这里不做赘述
实际应用
C++中的unordered_map和unordered_set的底层容器即是 HashTable 下面用上面简单实现的HashTable来封装一下两个数据结构
unordered_map
template<class K, class V, class hash = Hash<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
bool Find(const K& data)
{
return _ht.Find(data);
}
private:
Link_hash::HashTable<K, pair<K, V>, MapKeyOfT, hash> _ht;
};
unordered_set
template<class K, class hash = Hash<K>>
class unordered_map
{
struct SetKeyOfT
{
const K& operator()(K data)
{
return date;
}
};
public:
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
bool Find(const K& data)
{
return _ht.Find(data);
}
private:
Link_hash::HashTable<K, K, SetKeyOfT, hash> _ht;
};
unordered_map和unordered_set实现差别
插入时一个插入的是键值对,一个插入的是key值,如何用一个类模板搞定了呢?
这里就要提一下上文没有解释的一个模板参数
template<class K, class T, class KeyOfT, class HashFunc>中的class HashFunc
unordered_map中传入的是
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
unordered_set中传入的是
struct SetKeyOfT
{
const K& operator()(K data)
{
return date;
}
};
在哈希桶中通过HashFunc仿函数就可以获取到map和set中key值,从而统一实现接口。















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









