






目录
LoRA
全称:Low-Rank Adaptation of Large Language Models,是一个适用于微调大语言模型的低秩适应模型,属于参数高效微调(PEFT)的一类。(简而言之就是可以我们的大语言模型是用数十亿参数训练出来的,如何使用一个少数量的样本就能实现对模型的微调,使得大模型可以对特定场景的需求更好的应对)
LoRA目前热度使用方向
- Stable Diffusion model
- Large Language model
LoRA 模型目前在图像生成方面十分火爆使用——针对Stable Diffusion模型(AI图像生成模型),允许用户在不修改SD模型的情况下,利用少量数据训练出具有特定画风、IP或人物特征。LoRA最初是一个微软开发出来用于对LLM模型优化的技术,其支持不改变质量的同时将模型训练的参数量减少10000倍,并让显存需求降低到1/3。当然原本针对LLM训练,也很多使用。
LoRA机制流程
训练前,冻结经过了 预训练(以及进行了一部分通用指令的微调)的基础模型权重参数后,在每层Transformer架构中注入可训练的低秩分解矩阵,对低秩矩阵进行训练。
假如预训练模型的一个权重矩阵为W,W∈R^(d*k),LORA将其分解为两个低秩矩阵 A 和 B。其中,A 的维度为d * r,B 的维度为r * d,而r< < min(d, k)。
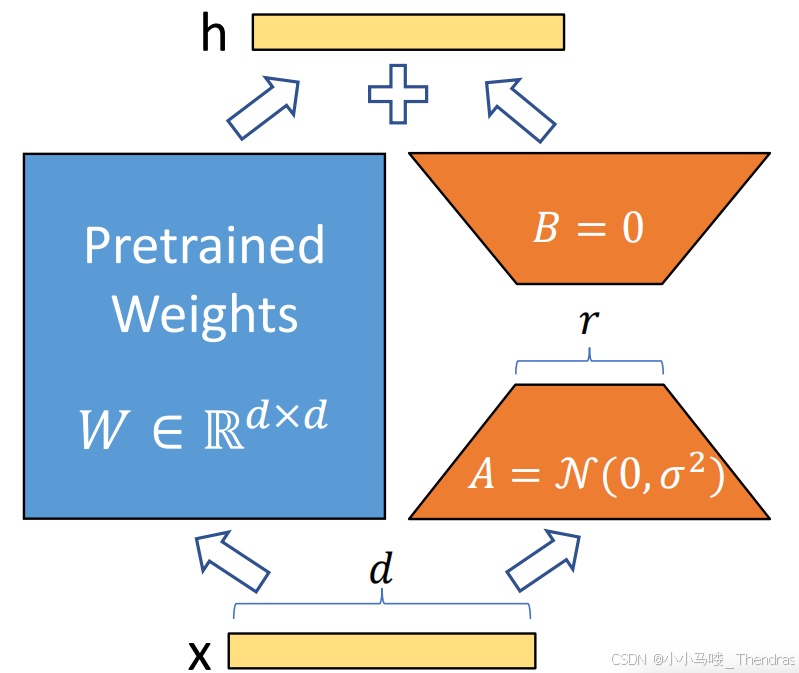
B用零矩阵初始化,A使用随机高斯分布初始化。
所以在训练开始的时候,新增的通路BA=0不影响模型。
前向传播公式如下:
h=W+△W=W+A*B
在推理时,我们可以将更新后的低秩矩阵乘积 BA 与原始的权重矩阵 W 相加,形成新的权重矩阵 Wnew=W+BA。这样在实际推理过程中,只需使用这个新权重矩阵 Wnew 进行计算,不会增加额外的计算资源。换句话说,推理时直接将原始预训练语言模型的W即可。
主要作用和意义
参数数量减少:
通过选择适当的 r,显著减少了需要训练的参数数量。具体来说,原始权重矩阵 W 的维度是 d × k ,而分解后的矩阵 A 和 B 的参数数量分别是 r × k 和 d × r。总的训练参数数量为 r ( d + k ),远小于 d k。
计算和存储效率增强:
由于 r 的值较低,即使在大型预训练模型的情况下,所需的训练参数和计算资源也大大减少。这使得在资源受限的环境中,对大型语言模型的微调成为可能。
模型性能不变:
尽管参数数量减少,但LoRA通过优化低秩矩阵,通常可以保持或提升模型在下游任务中的性能。
适用
LoRA特别适合需要频繁切换任务的应用场景,因为可以快速替换低秩矩阵 BB 和 AA 来适应不同任务,而无需重新训练整个模型。
或者是适用于多任务学习以及跨领域适应。
举个实例
假设一个权重矩阵 W 的维度是 12,288×4,096,使用LoRA对其进行低秩分解:
-
如果选择
r = 4,则 B 的维度为 12,288×4,A 的维度为 4×4,096。 -
这样,训练参数的总数从原来的 12,288×4,096≈50,331,648 减少到 4×(12,288+4,096)≈65,536,减少了近 1,000 倍。
通过调节 r 的值,可以权衡参数数量和模型性能,找到最优的低秩分解策略。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









