






并查集的两个操作:
1.将两个集合合并
2.询问两个元素是否在一个集合当中
并查集可以以近乎O(1)的时间复杂度进行以上两个操作
并查集的基本思想:
每个集合用一棵树来表示。树根的编号就是整个集合的编号。每个节点存储它的父节点。p[x]表示x的父节点。
如何判断树根:如果p[x] == x 那么x就是树根。
如何求x属于哪个集合:while(p[x] != x) x = p[x];时间复杂度O(logn)n是集合的节点数量。
如何合并两个集合:假设px 是x的集合编号,py是y的集合编号。p[x] = y。意思是将集合x插到集合y中。
以上查询属于哪个集合的步骤时间复杂度为O(logn),为了达到近似O(1)的时间复杂度。我们可以进行优化。
优化过程在第一次寻找根节点的过程中,将路径中的所有节点的父节点都直接指向根节点。那么以后路径中的节点再查询时间复杂度就都是O(1)了。这一步过程叫做路径压缩。
第一次,节点x查找根节点。
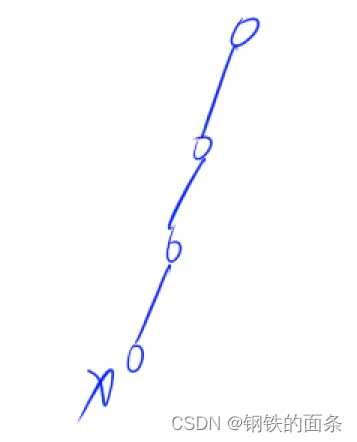
第二部直接将路径中的所有节点的父节点直接改为根节点。

 https://www.acwing.com/problem/content/description/838/
https://www.acwing.com/problem/content/description/838/import java.util.*;
import java.io.*;
public class Main{
static int N = 100010;
static int[] p = new int[N];
//返回x的祖宗节点 + 路径压缩
public static int find(int x) {
if (p[x] != x) {
p[x] = find(p[x]);
}
return p[x];
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
PrintWriter pw = new PrintWriter(new OutputStreamWriter(System.out));
String[] strings = br.readLine().split(" ");
int n = Integer.parseInt(strings[0]);
int m = Integer.parseInt(strings[1]);
for(int i = 1;i<=n;i++) {
p[i] = i;
}
for(int i = 0;i<m;i++) {
strings = br.readLine().split(" ");
String op = strings[0];
int a = Integer.parseInt(strings[1]);
int b = Integer.parseInt(strings[2]);
//如果是合并操作,直接将集合a的根节点的父亲指向b节点的根节点。
if (op.equals("M")) {
p[find(a)] = find(b);
} else {
pw.println(find(a) == find(b)?"Yes":"No");
}
}
pw.flush();
}
}并查集的核心就是find()操作。















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









