






目录
项目背景
搜索引擎是我们经常会用到的工具,例如我们熟知的百度,谷歌等搜索引擎。除了网络搜索引擎,还有很多地方也有搜索引擎的身影,例如视频网站的搜索框,手机的应用搜索功能。搜索引擎是一个很有用的工具,在数据量很大的时候,使用搜索引擎搜索能极大的提高效率,因此我想到了 JAVA 开发者们经常会用到的 JDK 文档。文档的内容很多,数量高达上万篇,因此当我们想查找一个东西的时候想找到对应的文档很难,因此我们可以写一个搜索引擎来快速的查找到我们想要的文档。
项目描述
打开浏览器,在搜索框中输入我们想要查找的关键词,点击搜索就能查找到 JDK 文档中所有与关键词有关的文档。但是我们无法搜索到 JDK 文档以外的信息,因为我们只针对 JDK 文档建立的搜索功能。
项目整体架构

项目流程
构建索引
1.首先创建一个 springboot 项目
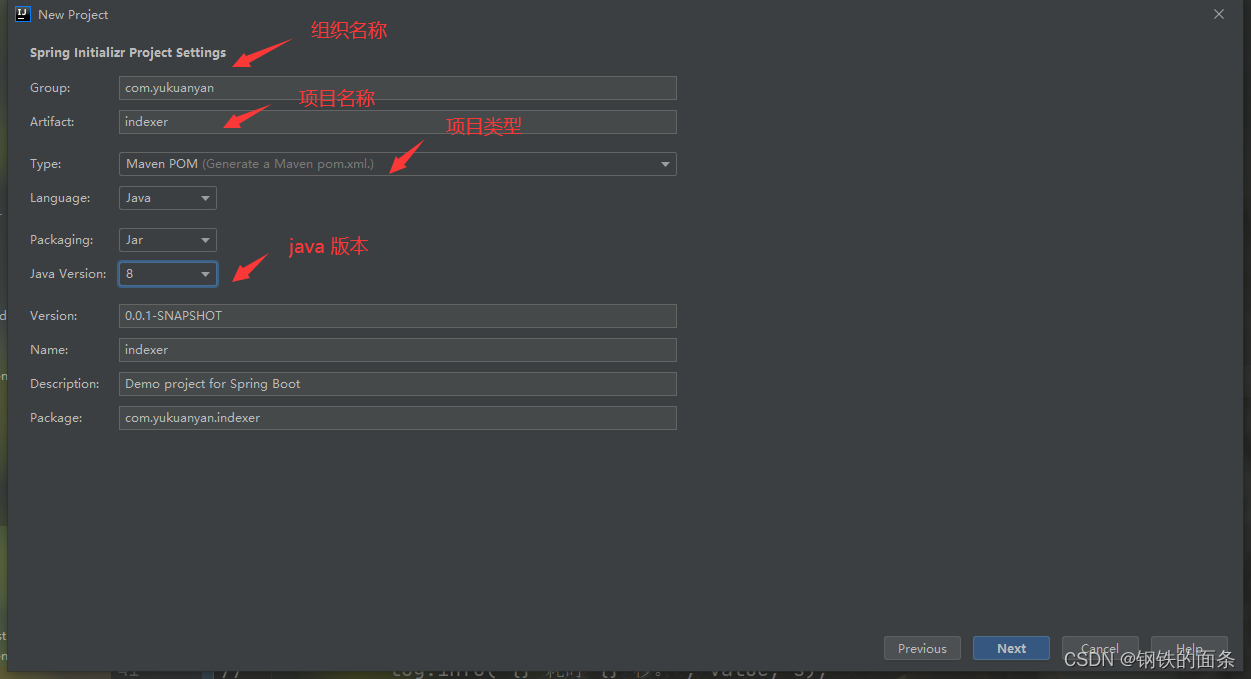
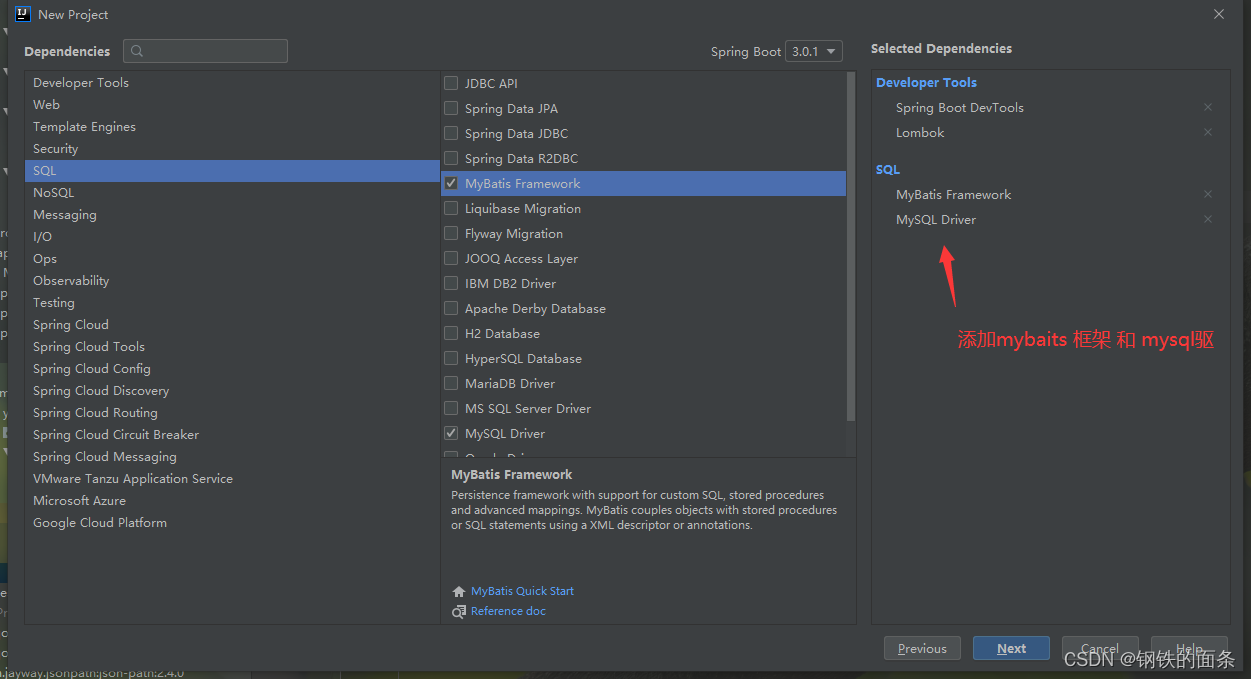
2.配置数据库
找到 resource 下的 application.application (也可以改成 application.yml) 配置文件配置数据库
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/searcher_refactor?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 1234563.扫描所有的jdk文档
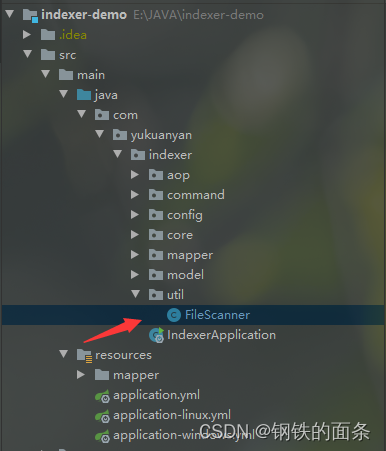
在 indexer 下新建 util 包用来存放工具类,再在 util 包下新建 FileScanner 类,实现扫描 JDK 文档的功能。我们需要在配置文件中定义文档的根目录,FileScanner 就能扫描出根目录中的所有 html 文档。
package com.yukuanyan.indexer.util;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
@Service
@Slf4j
public class FileScanner {
public List<File> scanFile(String rootPath){
List<File> finalFileList = new ArrayList<>();
File rootFile = new File(rootPath);
//说明对应路径的的文件不存在
if (rootFile == null) {
return finalFileList;
}
//进行遍历
traversal(rootFile,finalFileList);
return finalFileList;
}
private void traversal(File rootFile,List<File> fileList) {
// 获取所有的文件和文件夹,得到一个 FileList
File[] files = rootFile.listFiles();
// 一般是权限问题,一般不会碰到
if (files == null) {
return ;
}
// 遍历 FileList,如果是 html 文件就保存到list中,如果是文件夹就继续递归遍历
for (File file : files) {
if (file.isFile() && file.getName().endsWith(".html")) {
fileList.add(file);
} else {
traversal(file,fileList);
}
}
}
}
4.生成正排索引和倒排索引
正排索引的结构:key-value key是文档id,value是标题,url和内容。
倒排索引的结构:key-value key 是一个单词,value是一个list,list里面是一个 倒排记录对象,对象中有 单词,文档id和权重,表示在id为……的文档中,某某单词的权重是多少。
因此,我只要们拿到所有的 files 就能获得正排索引,docId就是数据库自增id。
而倒排索引是一个自定义对象(及在id为……的文档中,某某单词的权重是多少)的集合,在这里一条倒排索引称之为InvertedRecord(倒排记录)
创建Document类:在indexer 包下新建 model 包,在model 包下新建 Document 类。当前类是我们对 html 文档的抽象,用于将磁盘中的文件加载到内存中并且提取出构建索引需要的内容。
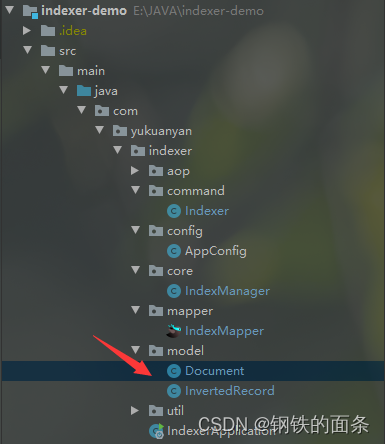

因为每个文档对象都需要被分词和计算权重,所以每一个 Document 对象都需要有分词和计算权重的方法(segWordsAndCalcWeight)。我们先分别分词和统计标题单词的出现次数和正文单词的出现次数。
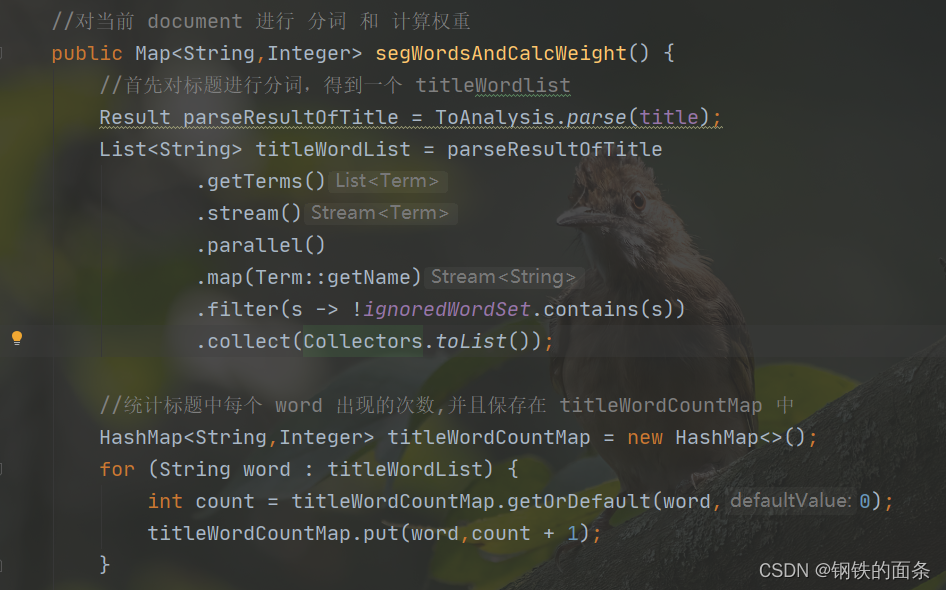
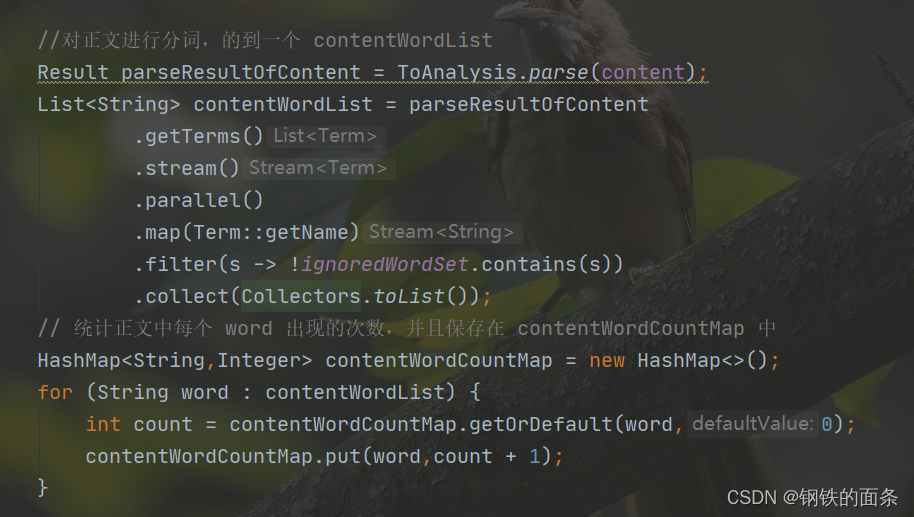
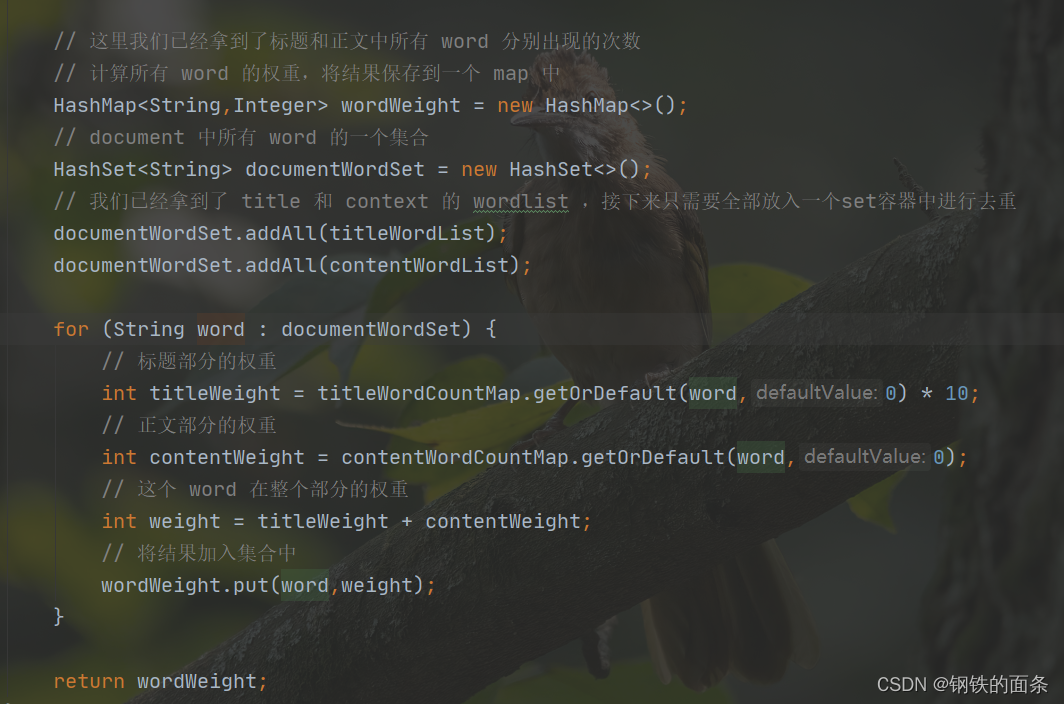
再根据权重计算公式计算出当前 document 每个单词对应的权重(权重 = 标题权重 + 正文权重),至此当前 document 的所有单词的权重已经生成好了,将他们保存在 map 中。
完整代码:
Document类:
package com.yukuanyan.indexer.model;
import lombok.Data;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.io.*;
import java.util.*;
import java.util.stream.Collectors;
@Slf4j
@Data
public class Document {
private Integer docId;
//文档的标题
private String title;
//文档对应的url
private String url;
//文档的正文部分
private String content;
//由于分词结果中会出现这些没有意义的字符,忽略分词结果中的这些字符
private final static HashSet<String> ignoredWordSet = new HashSet<>();
static {
ignoredWordSet.add(" ");
ignoredWordSet.add("\t");
ignoredWordSet.add("。");
ignoredWordSet.add(".");
ignoredWordSet.add(",");
ignoredWordSet.add("(");
ignoredWordSet.add(")");
ignoredWordSet.add("/");
ignoredWordSet.add("-");
ignoredWordSet.add(";");
}
public Document(File file,String urlPrefix,File rootFile){
this.title = parseTitle(file);
this.url = parseUrl(file,urlPrefix,rootFile);
this.content = parseContent(file);
}
// 解析正文
@SneakyThrows
private String parseContent(File file) {
StringBuilder contentBuilder = new StringBuilder();
try (InputStream is = new FileInputStream(file)) {
try (Scanner scanner = new Scanner(is, "ISO-8859-1")) {
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
contentBuilder.append(line).append(" ");
}
// 利用正则表达式去除正文中的 html 标签
return contentBuilder.toString()
.replaceAll("<script.*?>.*?</script>", " ")
.replaceAll("<.*?>", " ")
.replaceAll("\\s+", " ")
.trim();
}
}
}
@SneakyThrows
private String parseUrl(File file, String urlPrefix, File rootFile) {
// 需要得到一个相对路径,file 相对于 rootFile 的相对路径
// 比如:rootFile 是 C:\Users\秋叶雨\Downloads\docs\api\
// file 是 C:\Users\秋叶雨\Downloads\docs\api\java\ util\TreeSet.html
// 则相对路径就是:java\ util\TreeSet.html
// 把所有反斜杠(\) 变成正斜杠(/)
// 最终得到 java/sql/DataSource.html
String rootPath = rootFile.getCanonicalPath();
rootPath = rootPath.replace("/", "\\");
if (!rootPath.endsWith("\\")) {
rootPath = rootPath + "\\";
}
String filePath = file.getCanonicalPath();
String relativePath = filePath.substring(rootPath.length());
relativePath = relativePath.replace("\\", "/");
return urlPrefix + relativePath;
}
private String parseTitle(File file) {
// 从文件名中,将 .html 后缀去掉,剩余的看作标题
String name = file.getName();
String suffix = ".html";
return name.substring(0, name.length() - suffix.length());
}
//对当前 document 进行 分词 和 计算权重
public Map<String,Integer> segWordsAndCalcWeight() {
//首先对标题进行分词,得到一个 titleWordlist
Result parseResultOfTitle = ToAnalysis.parse(title);
List<String> titleWordList = parseResultOfTitle
.getTerms()
.stream()
.parallel()
.map(Term::getName)
.filter(s -> !ignoredWordSet.contains(s))
.collect(Collectors.toList());
//统计标题中每个 word 出现的次数,并且保存在 titleWordCountMap 中
HashMap<String,Integer> titleWordCountMap = new HashMap<>();
for (String word : titleWordList) {
int count = titleWordCountMap.getOrDefault(word,0);
titleWordCountMap.put(word,count + 1);
}
//对正文进行分词,的到一个 contentWordList
Result parseResultOfContent = ToAnalysis.parse(content);
List<String> contentWordList = parseResultOfContent
.getTerms()
.stream()
.parallel()
.map(Term::getName)
.filter(s -> !ignoredWordSet.contains(s))
.collect(Collectors.toList());
// 统计正文中每个 word 出现的次数,并且保存在 contentWordCountMap 中
HashMap<String,Integer> contentWordCountMap = new HashMap<>();
for (String word : contentWordList) {
int count = contentWordCountMap.getOrDefault(word,0);
contentWordCountMap.put(word,count + 1);
}
// 这里我们已经拿到了标题和正文中所有 word 分别出现的次数
// 计算所有 word 的权重,将结果保存到一个 map 中
HashMap<String,Integer> wordWeight = new HashMap<>();
// document 中所有 word 的一个集合
HashSet<String> documentWordSet = new HashSet<>();
// 我们已经拿到了 title 和 context 的 wordlist ,接下来只需要全部放入一个set容器中进行去重
documentWordSet.addAll(titleWordList);
documentWordSet.addAll(contentWordList);
for (String word : documentWordSet) {
// 标题部分的权重
int titleWeight = titleWordCountMap.getOrDefault(word,0) * 10;
// 正文部分的权重
int contentWeight = contentWordCountMap.getOrDefault(word,0);
// 这个 word 在整个部分的权重
int weight = titleWeight + contentWeight;
// 将结果加入集合中
wordWeight.put(word,weight);
}
return wordWeight;
}
}
InvertedRecord类:
package com.yukuanyan.indexer.model;
import lombok.Data;
@Data
public class InvertedRecord {
//表示 word 在文章号为 docId 的文章中权重为 weight
private String word;
private Integer docId;
private Integer weight;
public InvertedRecord(String word,Integer docId,Integer weight) {
this.word = word;
this.docId = docId;
this.weight = weight;
}
}
5.保存正排索引和倒排索引
由于文档的数量较多,正排索引的数量 在1w左右,倒排索引的数量在百万级比,因此在插入数据库的时候不加任何优化会很慢,因此采用了多线程+批量插入数据库的优化。
我们首先需要创建一个线程池,在indexer 包下新建config 包,在config 包下创建 AppConfig 类。AppConfig 类是 spring 容器中的 生产者,因此我们给类加上 @Configuration ,给方法加上@Bean,我们需要线程池,因此返回类型是 ExecutorService
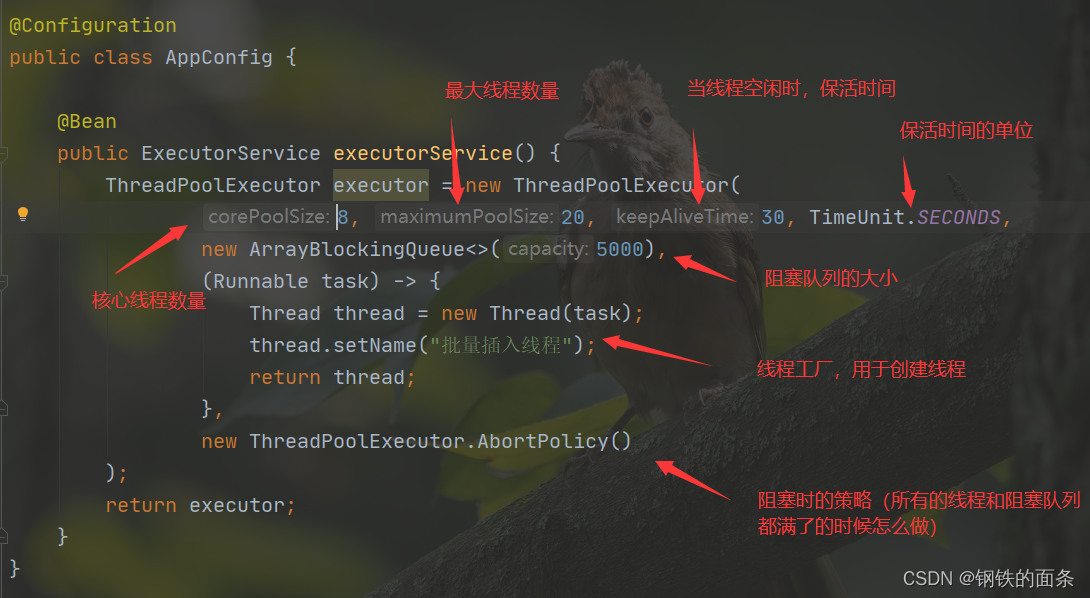
我们还需要将索引保存到数据库中。使用mybatis框架进行数据库操作需要 Mapper 接口和 对应的 Mapper.xml,因此在 indexer 包下新建 mapper 包,在mapper 包下新建 IndexerMapper 接口,在接口内定义插入正排索引和倒排索引的方法

package com.yukuanyan.indexer.mapper;
import com.yukuanyan.indexer.model.Document;
import com.yukuanyan.indexer.model.InvertedRecord;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
@Mapper
@Repository
public interface IndexMapper {
//批量插入正排索引
public void batchInsertForwardIndexes(@Param("list") List<Document> documentList);
//批量插入倒排索引
public void batchInsertInvertedIndexes(@Param("list") List<InvertedRecord> recordsList);
}
在 resource 下新建 mapper ,在mapper 下新建Mapper.xml。同时在application.yml 中配置 Mapper.xml 的 路径

之后我们就可以在Mapper.xml 内写 sql 语句了
一个 mapper.xml 对应一个 接口,因此需要在 mapper.xml 中配置对应接口

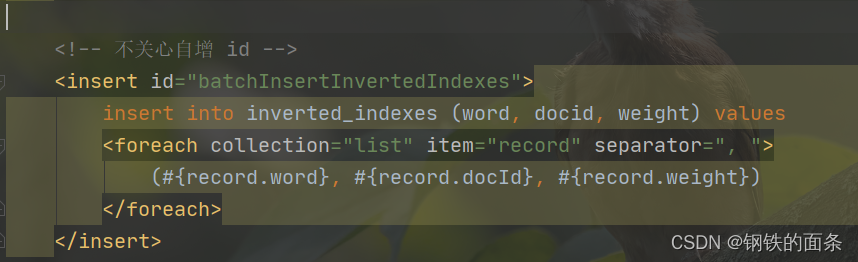
批量插入正排索引的标签。由于需要获取docid因此我们需要自增id。
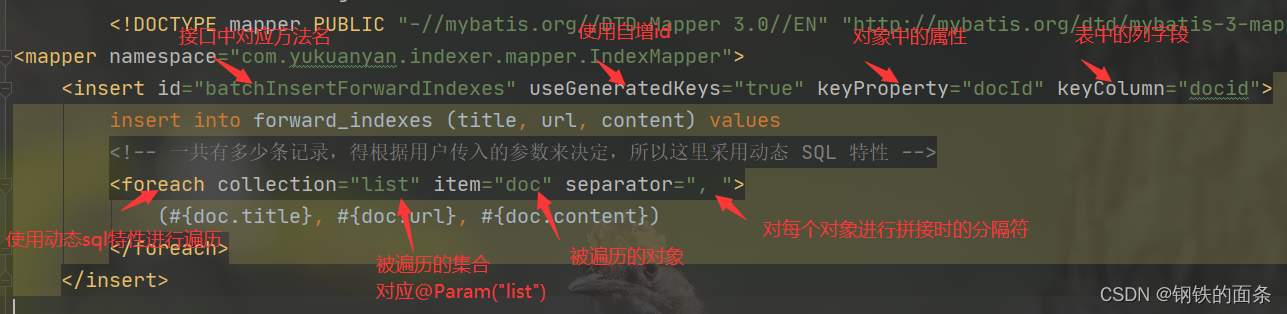
批量插入倒排索引的标签,和正排索引类似
在indexer 包下 新建 core 包,在core包下新建 IndexerManager 类,这个类用来批量保存索引,会用到线程池 和 数据库。

主要功能:保存正排索引和倒排索引。由于插入数据库不需要返回值,所以我们 继承 Runnable 接口 再提交到线程池中执行。
保存正排索引
//多线程生成并保存正排索引
@Timing("多线程保存正排索引")
@SneakyThrows
public void saveForwardIndexesConcurrent(List<Document> documentList) {
//1.每次批量插入数据库的条数,由于是插入正排索引,每条的数据量都比较大,每次10条就好了
int batchSize = 10;
//2.文档的数量
int listSize = documentList.size();
//3.一共需要执行 sql 语句的次数
int times = (int)Math.ceil(listSize/batchSize);
log.debug("一共需要执行 {} 次插入操作");
CountDownLatch latch = new CountDownLatch(times);
//4.开始分批次插入数据库
for (int i = 0; i < listSize; i += batchSize) {
//插入的起始下标
int from = i;
int to = Integer.min(from + batchSize,listSize);
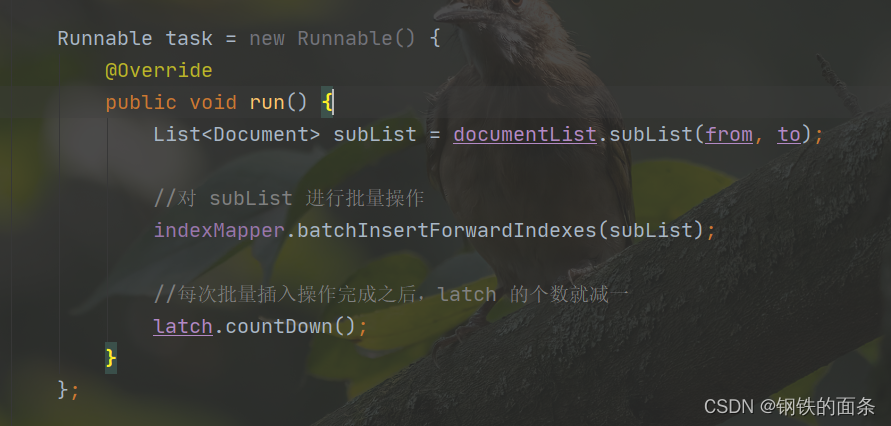
// Runnable task = () -> {
// List<Document> subList = documentList.subList(from, to);
// //对 subList 进行批量操作
// indexMapper.batchInsertForwardIndexes(subList);
// //每次批量插入操作完成之后,latch 的个数就减一
// latch.countDown();
// };
Runnable task = new Runnable() {
@Override
public void run() {
List<Document> subList = documentList.subList(from, to);
//对 subList 进行批量操作
indexMapper.batchInsertForwardIndexes(subList);
//每次批量插入操作完成之后,latch 的个数就减一
latch.countDown();
}
};
//主线程只是负责把一批批的 task 提交到线程池,具体的插入工作由线程池中的线程完成
executorService.submit(task);
}
//循环结束,只是意味着主线程把任务提交给做文案了,但是不知道 task 有没有完成
//主线程在 latch 上,直到 latch 的个数变成 0 ,也就是所有的 task 已经完成了
latch.await();
}
保存倒排索引,先建立静态内部类继承 Runnable 接口设置任务
static class InvertedInsertTask implements Runnable {
private final CountDownLatch latch;
private final int batchSize;
private final List<Document> documentList;
private final IndexMapper mapper;
InvertedInsertTask(CountDownLatch latch, int batchSize, List<Document> documentList, IndexMapper mapper) {
this.latch = latch;
this.batchSize = batchSize;
this.documentList = documentList;
this.mapper = mapper;
}
@Override
public void run() {
List<InvertedRecord> recordList = new ArrayList<>(); // 放这批要插入的数据
for (Document document : documentList) {
Map<String, Integer> wordToWeight = document.segWordsAndCalcWeight();
for (Map.Entry<String, Integer> entry : wordToWeight.entrySet()) {
String word = entry.getKey();
int docId = document.getDocId();
int weight = entry.getValue();
InvertedRecord record = new InvertedRecord(word, docId, weight);
recordList.add(record);
// 如果 recordList.size() == batchSize,说明够一次插入了
if (recordList.size() == batchSize) {
mapper.batchInsertInvertedIndexes(recordList); // 批量插入
recordList.clear(); // 清空 list,视为让 list.size() = 0
}
}
}
// recordList 还剩一些,之前放进来,但还不够 batchSize 个的,所以最后再批量插入一次
mapper.batchInsertInvertedIndexes(recordList); // 批量插入
recordList.clear();
latch.countDown();
}
}保存倒排索引
@Timing("多线程保存倒排索引")
@SneakyThrows
public void saveInvertedIndexesConcurrent(List<Document> documentList) {
int batchSize = 10000; // 批量插入时,最多 10000 条
int groupSize = 50;
int listSize = documentList.size();
int times = (int) Math.ceil(listSize * 1.0 / groupSize);
CountDownLatch latch = new CountDownLatch(times);
for (int i = 0; i < listSize; i += groupSize) {
int from = i;
int to = Integer.min(from + groupSize, listSize);
List<Document> subList = documentList.subList(from, to);
Runnable task = new InvertedInsertTask(latch, batchSize, subList, indexMapper);
executorService.submit(task);
}
latch.await();
}搜索功能
前端
只有两个页面,一个是搜索的主页,一个是显示搜索结果的页面。搜索的主页是一个静态资源,写在index.html内
首页的设计借鉴了青柠起始页的设计,具体细节如下:甲方你请说:仿青柠搜索页模态搜索栏(HTML+CSS+JS)_哔哩哔哩_bilibili
搜索页再主页输入搜索词,点击搜索之后进入。使用了 thmeleaf 模板技术
后端
1.创建springboot项目
同上
2.配置数据库
spring:
main:
log-startup-info: false
banner-mode: off
datasource:
url: jdbc:mysql://127.0.0.1:3306/searcher_refactor?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
profiles:
active: windows
mybatis:
mapper-locations: classpath:mapper/search-mapper.xml
logging:
level:
com.yukuanyan.searcher.web: debug定义SeacherMpaaer接口
package com.yukuanyan.searcher.web.mapper;
import com.yukuanyan.searcher.web.module.Document;
import com.yukuanyan.searcher.web.module.DocumentWithWeight;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
@Mapper
public interface SearchMapper {
List<Document> query(
@Param("word") String word,
@Param("limit") int limit,
@Param("offset") int offset);
List<DocumentWithWeight> queryWithWeight(
@Param("word") String word,
@Param("limit") int limit,
@Param("offset") int offset
);
}
在配置文件中写具体的业务查询语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.yukuanyan.searcher.web.mapper.SearchMapper">
<resultMap id="DocumentResultMap" type="com.yukuanyan.searcher.web.module.Document">
<id property="docId" column="docid" />
<result property="title" column="title" />
<result property="url" column="url" />
<result property="content" column="content" />
</resultMap>
<resultMap id="DocumentWithWeightResultMap" type="com.yukuanyan.searcher.web.module.DocumentWithWeight">
<id property="docId" column="docid" />
<result property="title" column="title" />
<result property="url" column="url" />
<result property="content" column="content" />
<result property="weight" column="weight" />
</resultMap>
<!-- #{...} 会添加引号上去; ${...} 不会添加引号 -->
<select id="query" resultMap="DocumentResultMap">
select ii.docid, title, url, content
from inverted_indexes ii
join forward_indexes fi
on ii.docid = fi.docid
where word = #{word}
order by weight desc
limit ${limit}
offset ${offset}
</select>
<select id="queryWithWeight" resultMap="DocumentWithWeightResultMap">
select ii.docid, title, url, content, weight
from inverted_indexes ii
join forward_indexes fi
on ii.docid = fi.docid
where word = #{word}
order by weight desc
limit ${limit}
offset ${offset}
</select>
</mapper>3.实现查询功能
"/web"路由对输入的查询词进行处理并且返回结果

由于可能存在多个查询词,需要对多个查询结果进行聚合
按降序排列
使用了springMVC的模板渲染技术(ViewReview),这里具体使用的是Tymeleaf。Model添加渲染需要的数据:query,docList,page
return “search” 对应resource/templates/search.html
search.html 使用了thmeleaf的语法
th:xxxx都是
th:text vs th:utext 一个进行HTML转义,一个不转义
th:href=“……” 修改标签的href
th:each=”doc:${doclist}”
package com.yukuanyan.searcher.web.controller;
import com.yukuanyan.searcher.web.component.DescBuilder;
import com.yukuanyan.searcher.web.module.Document;
import com.yukuanyan.searcher.web.module.DocumentWithWeight;
import com.yukuanyan.searcher.web.mapper.SearchMapper;
import lombok.extern.slf4j.Slf4j;
import org.ansj.domain.Term;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.ansj.splitWord.analysis.ToAnalysis;
import org.springframework.web.bind.annotation.RequestParam;
import java.util.*;
import java.util.stream.Collectors;
@Slf4j
@Controller
public class SearchController {
private final SearchMapper mapper;
private final DescBuilder descBuilder;
@Autowired
public SearchController(SearchMapper mapper, DescBuilder descBuilder) {
this.descBuilder = descBuilder;
ToAnalysis.parse("预热分词");
this.mapper = mapper;
}
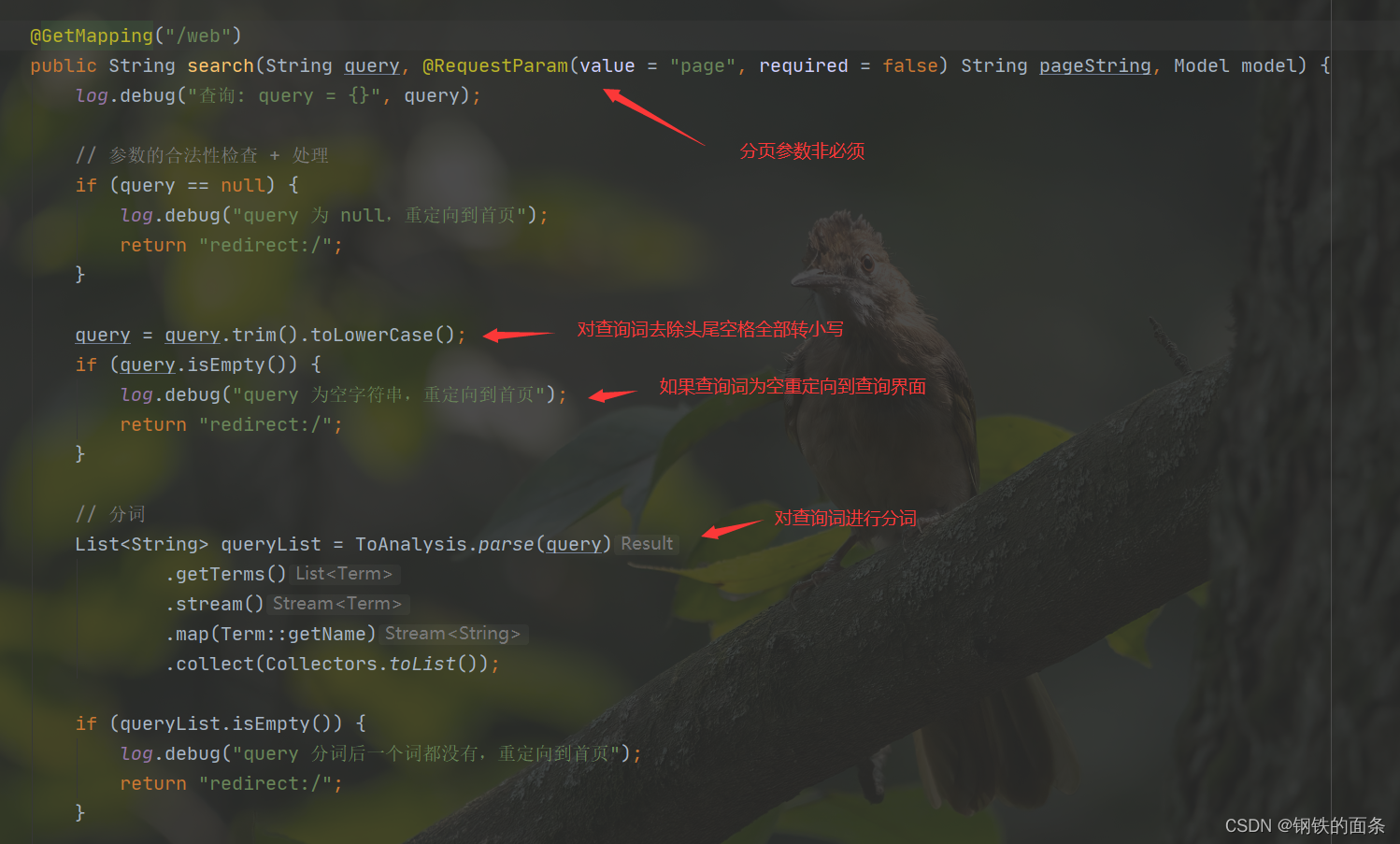
@GetMapping("/web")
public String search(String query, @RequestParam(value = "page", required = false) String pageString, Model model) {
log.debug("查询: query = {}", query);
// 参数的合法性检查 + 处理
if (query == null) {
log.debug("query 为 null,重定向到首页");
return "redirect:/";
}
query = query.trim().toLowerCase();
if (query.isEmpty()) {
log.debug("query 为空字符串,重定向到首页");
return "redirect:/";
}
// 分词
List<String> queryList = ToAnalysis.parse(query)
.getTerms()
.stream()
.map(Term::getName)
.collect(Collectors.toList());
if (queryList.isEmpty()) {
log.debug("query 分词后一个词都没有,重定向到首页");
return "redirect:/";
}
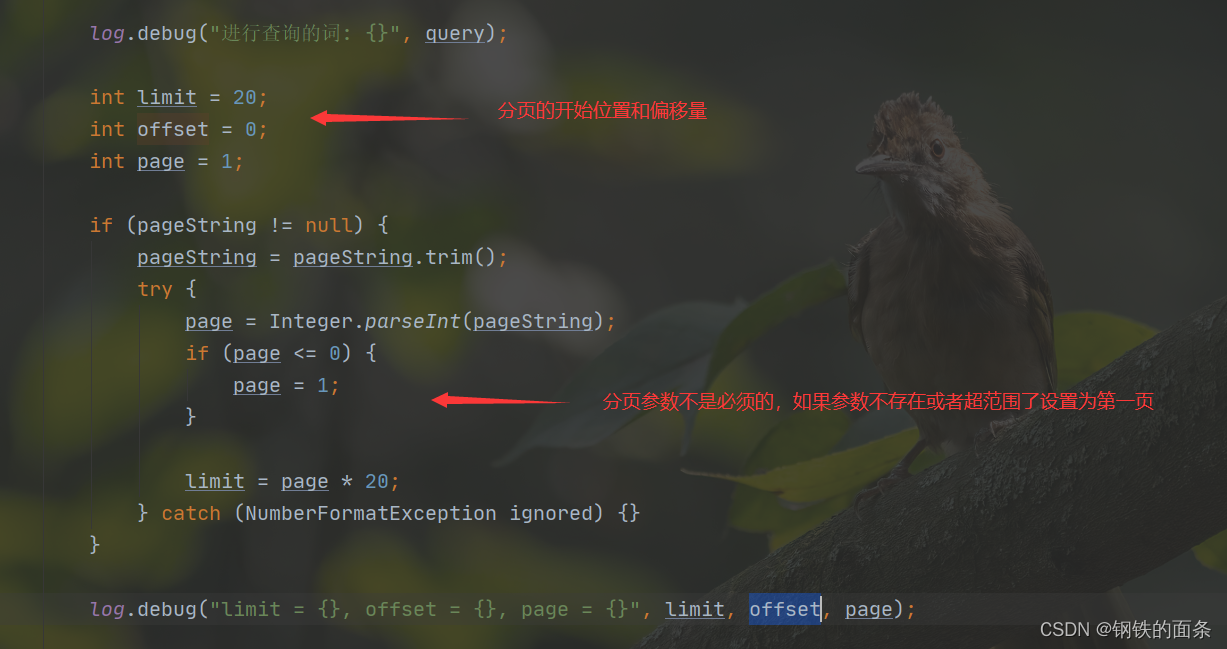
log.debug("进行查询的词: {}", query);
int limit = 20;
int offset = 0;
int page = 1;
if (pageString != null) {
pageString = pageString.trim();
try {
page = Integer.parseInt(pageString);
if (page <= 0) {
page = 1;
}
limit = page * 20;
} catch (NumberFormatException ignored) {}
}
log.debug("limit = {}, offset = {}, page = {}", limit, offset, page);
// 分别搜索 -> 聚合 -> 排序 -> 区间
List<DocumentWithWeight> totalList = new ArrayList<>();
for (String s : queryList) {
List<DocumentWithWeight> documentList = mapper.queryWithWeight(s, limit, offset);
totalList.addAll(documentList);
}
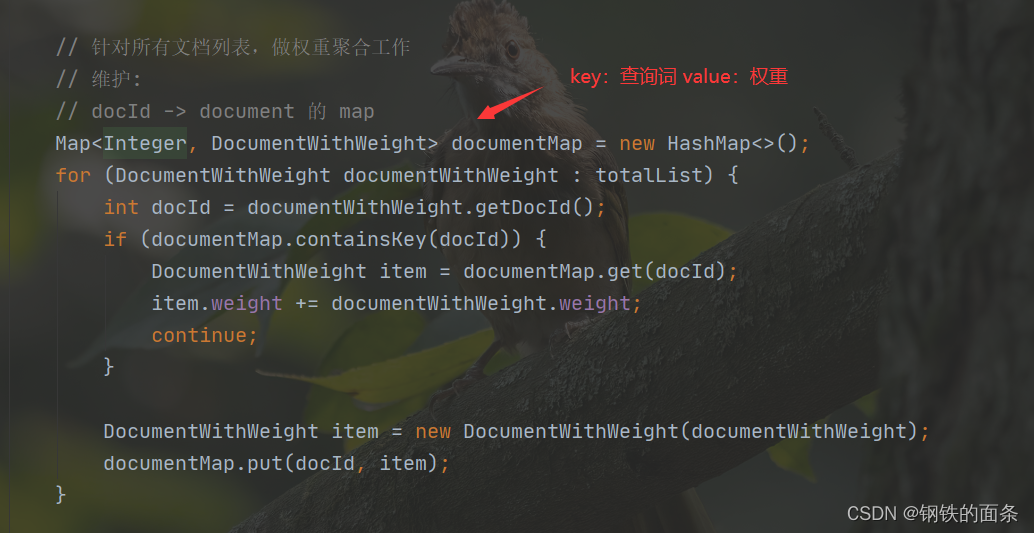
// 针对所有文档列表,做权重聚合工作
// 维护:
// docId -> document 的 map
Map<Integer, DocumentWithWeight> documentMap = new HashMap<>();
for (DocumentWithWeight documentWithWeight : totalList) {
int docId = documentWithWeight.getDocId();
if (documentMap.containsKey(docId)) {
DocumentWithWeight item = documentMap.get(docId);
item.weight += documentWithWeight.weight;
continue;
}
DocumentWithWeight item = new DocumentWithWeight(documentWithWeight);
documentMap.put(docId, item);
}
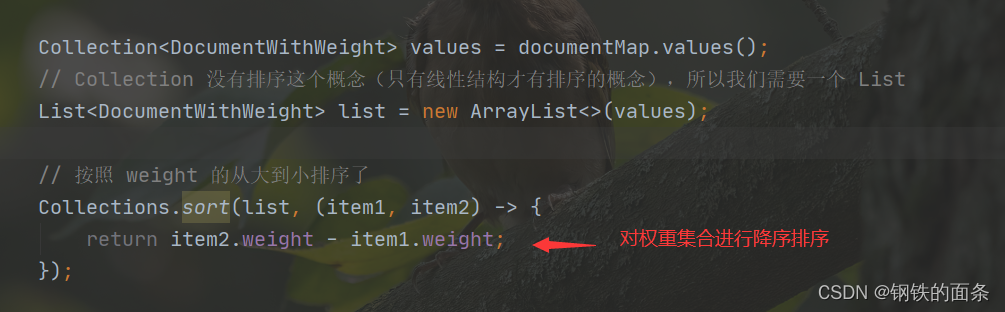
Collection<DocumentWithWeight> values = documentMap.values();
// Collection 没有排序这个概念(只有线性结构才有排序的概念),所以我们需要一个 List
List<DocumentWithWeight> list = new ArrayList<>(values);
// 按照 weight 的从大到小排序了
Collections.sort(list, (item1, item2) -> {
return item2.weight - item1.weight;
});
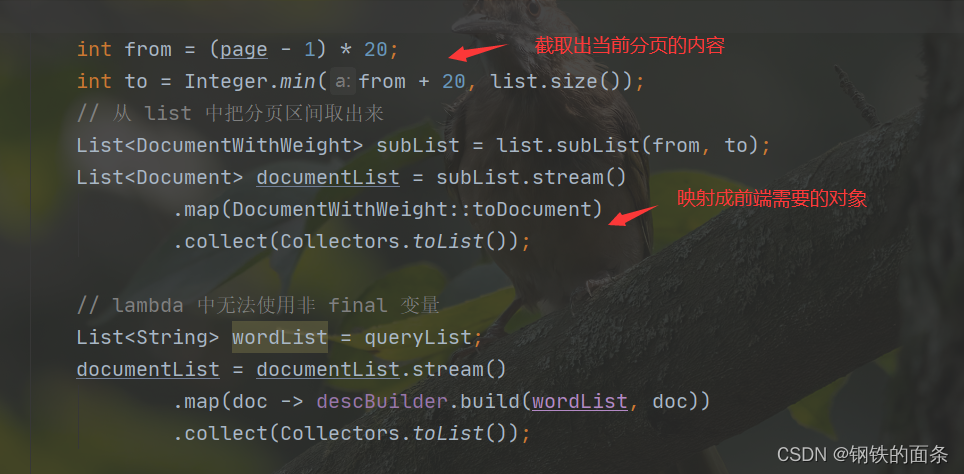
int from = (page - 1) * 20;
int to = Integer.min(from + 20, list.size());
// 从 list 中把分页区间取出来
List<DocumentWithWeight> subList = list.subList(from, to);
List<Document> documentList = subList.stream()
.map(DocumentWithWeight::toDocument)
.collect(Collectors.toList());
// lambda 中无法使用非 final 变量
List<String> wordList = queryList;
documentList = documentList.stream()
.map(doc -> descBuilder.build(wordList, doc))
.collect(Collectors.toList());
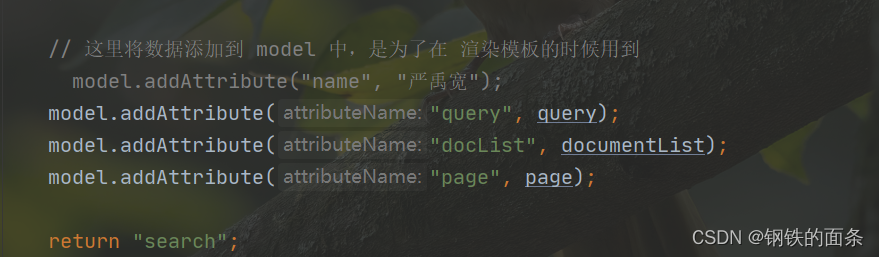
// 这里将数据添加到 model 中,是为了在 渲染模板的时候用到
// model.addAttribute("name", "严禹宽");
model.addAttribute("query", query);
model.addAttribute("docList", documentList);
model.addAttribute("page", page);
return "search";
}
}
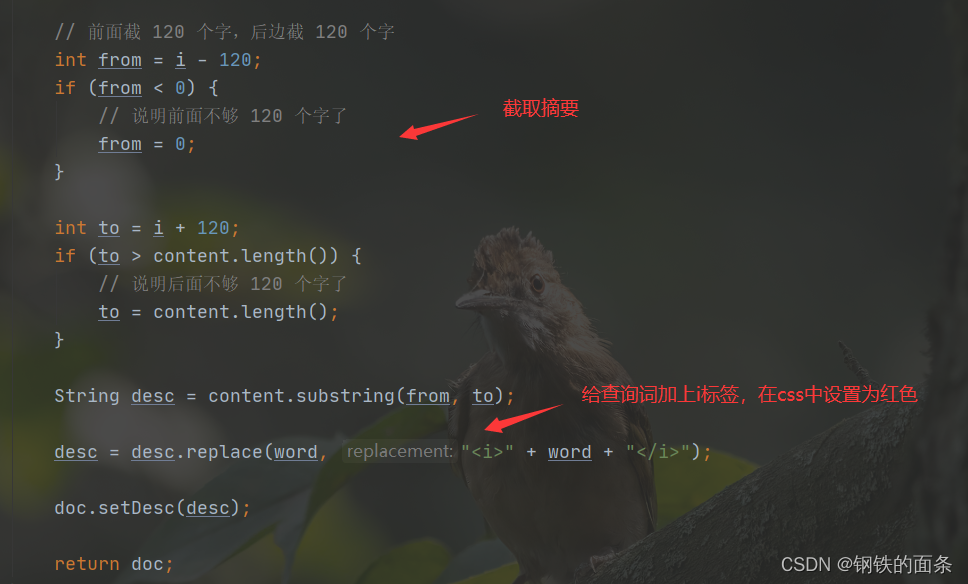
4.处理搜索结果的描述

5.处理过程中用到的承载数据的类
package com.yukuanyan.searcher.web.module;
import lombok.Data;
@Data
public class Document {
private Integer docId;
private String title;
private String url;
private String content;
private String desc;
@Override
public String toString() {
return String.format("Document{docId=%d, title=%s, url=%s}", docId, title, url);
}
}
package com.yukuanyan.searcher.web.module;
import lombok.Data;
@Data
public class DocumentWithWeight {
private int docId;
private String title;
private String url;
private String content;
public int weight;
public DocumentWithWeight() {}
public DocumentWithWeight(DocumentWithWeight documentWithWeight) {
this.docId = documentWithWeight.docId;
this.title = documentWithWeight.title;
this.url = documentWithWeight.url;
this.content = documentWithWeight.content;
this.weight = documentWithWeight.weight;
}
public Document toDocument() {
Document document = new Document();
document.setDocId(this.docId);
document.setTitle(this.title);
document.setUrl(this.url);
document.setContent(this.content);
return document;
}
}
gitee:
索引构造器:indexer: 搜索引擎构建索引day1















 2767
2767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









