







一.项目简介
如今,大大小小的网站以及软件都可能会涉及到搜索这一功能,因此,计划写出一个基于web的搜索相关文档的搜索引擎项目。以锻炼自己的能力,加强对技术的应用,能够更好的掌握相关的技术,了解互联网的发展。众所周知,搜索本身看起来貌似很简单,很多方法其实都可以做出来,比如简简单单的sql语句的模糊匹配也就可以实现这一功能,为什么非要做一个项目来实现搜索引擎呢?最主要的原因还是相关的性能问题,试想一下,若在平时生活中搜索一个词的时间长达几分钟甚至更长,这是人们所接受不了的,因此,设计一个搜索引擎就显现的非常的重要,能够加快搜索的性能,能够实现很快出结果,在性能上能够进行日常的应用
二.模块管理
该项目一共分为两大模块,一大模块是建立索引模块,另一大模块是搜索模块。
建立索引模块分为扫描文档,构建文档,构建保存正排索引和构建保存倒排索引。
扫描文档是将本地文档进行扫描,并将其保存到内存中以供其之后的操作,构建文档相当于
正排索引是把相关的文档进行编号,每篇文档有自己的编号id,以及自己的标题,自己的url,自己的正文等相关的信息,目的是通过倒排索引相关的单词找到正排索引并且进行展示相关的文档,能够查到到相关的文档。
倒排索引相当于把文档中包括标题的每一个进行分割开来,并且每篇进行词的统计,保存相应词语的文章id跟权重(为了显示的时候的排序问题),权重的计算方法为文章标题出现的次数* 10 + 文章正文出现的次数,根据单词进行查询,找到相关文档的id,然后根据id显示。
该项目的软件层次结构图如下:
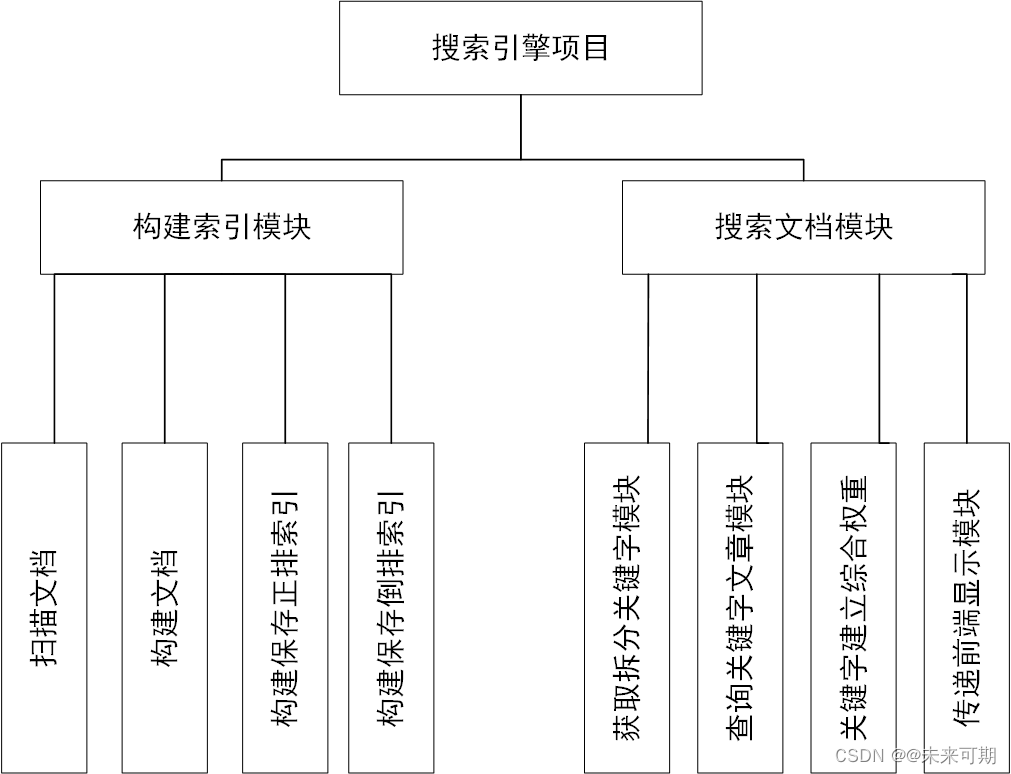
软件层次图
三.数据库的设计
该设计的数据库主要作用是进行正排索引和倒排索引的保存。
1.正排索引
正排索引的字段主要有:
docId --文章的id
title --文章的标题
url --文章对应的url
content --文章的正文
表的结构如图所示。

正排索引表
建表语句如下
CREATE TABLE `forward_indexes`
( `docid` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(100) NOT NULL,
`url` varchar(200) NOT NULL,
`content` longtext NOT NULL,
PRIMARY KEY (`docid`))
COMMENT=\'存放正排索引\\ndocid -> 文档的完整信息\''
2.倒排索引表
id --对应单词的id
word --对应的单词
docid --对应的文章id
weight --该单词在该文章对应的权重
表的结构如下图所示。

倒排索引表
值得注意的是,在后续的查询过程中,为了提高查询的效率,在该表建立了相关word和weight的联合索引,以达到性能提升的目的。
CREATE TABLE `inverted_indexes`
( `id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(100) NOT NULL,
`docid` int(11) NOT NULL,
`weight` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `INDEX_word_weight` (`word`,`weight`))
ENGINE=InnoDB AUTO_INCREMENT=2155795 DEFAULT CHARSET=utf8mb4
COMMENT=\'倒排索引\\n通过 word -> [ { docid + weight }, { docid + weight }, ... ]'
--建立索引--
ALTER TABLE `searcher_refactor`. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









