






经过模型训练及测试,我们得到了保存在 ‘./runs/detect/train/weights/’ 下的pt类型文件,这种文件保存的是模型的权重信息,为便于进一步推理和部署,需要将pt文件转为onnx格式,再转为engine格式,下面介绍具体实现步骤。
本文主要参考:YOLOv8模型训练 + 部署
目 录
3) 安装 TensorRT Python wheel 文件
一、pt转onnx
这一步是将pt格式的文件转为onnx格式。
1、修改配置文件
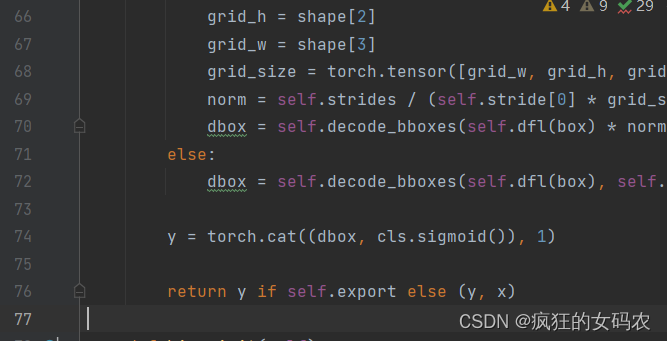
找到yolov8/ultralytics/nn/modules/head.py文件,大约在第76行和第252行,有一句代码“return y if self.export else (y, x)”,将它改为“return y.permute(0, 2, 1) if self.export else (y, x)”。
修改前:

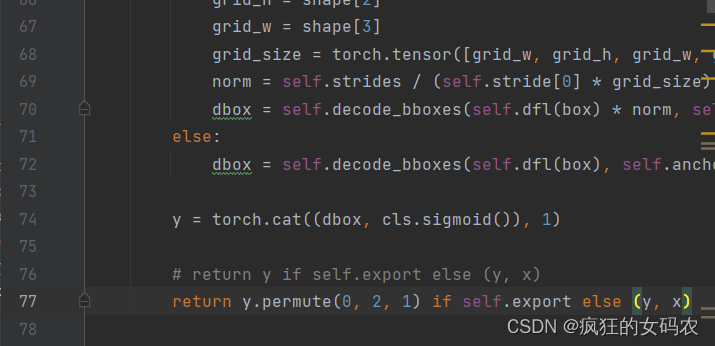
修改后:

2、编写转换程序
在/yolov8下新建文件:pt2onnx.py,内容如下:
from ultralytics import YOLO
model = YOLO('./runs/detect/train/weights/last.pt')
model.export(format="onnx")运行pt2onnx.py程序,即可得到onnx文件,存储在./runs/detect/train/weights/last.onnx中。
对于onnx模型,可以借助 https://netron.app/ 查看该模型的网络结构。
二、onnx转engine
这一步我借助的是TensorRT下的trtexec.exe工具,所以没安装TensorRT的需要先安装一下。
1、安装TensorRT
安装TensorRT我主要参考的是:TensorRT的安装与使用
1)下载合适版本TensorRT
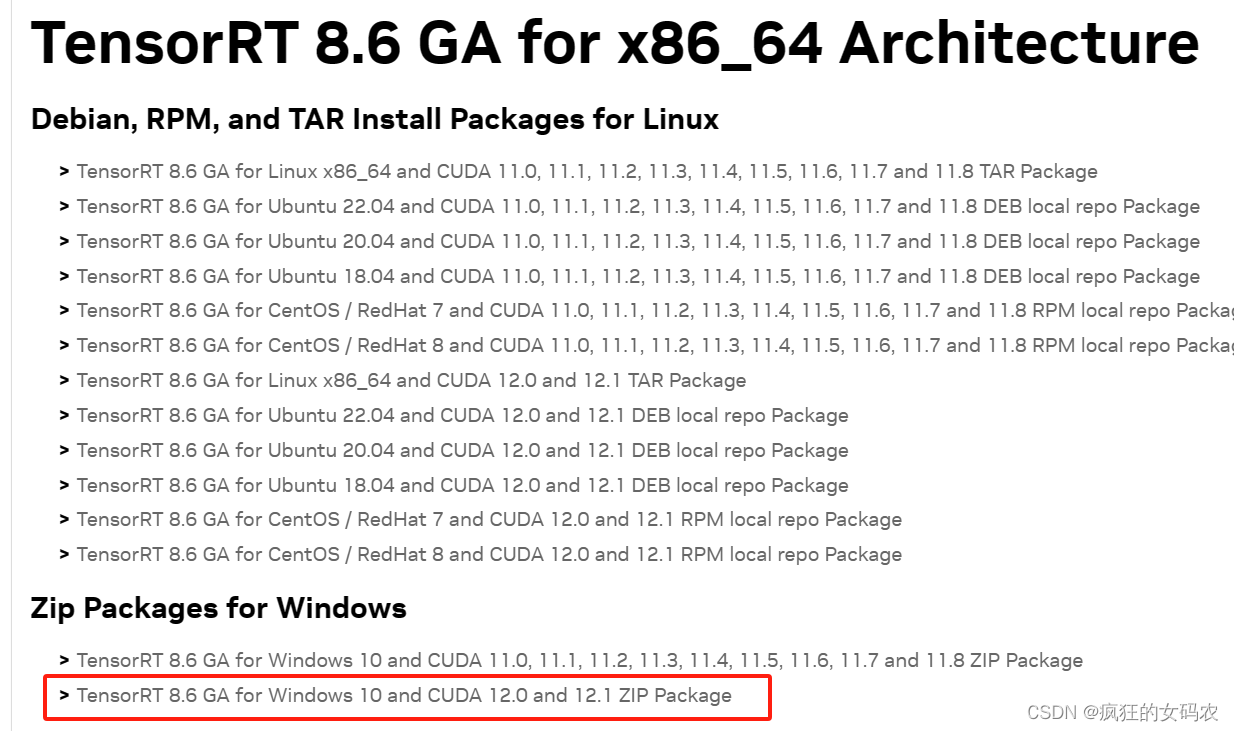
首先,在nvidia官网(NVIDIA TensorRT 8.x Download | NVIDIA Developer)下载TensorRT,勾选I agree to……后,会出现可下载的版本,我选择的是第一个TensorRT 8.6 GA。

我的运行环境是windows系统,CUDA版本是12.2,下载了如下图所示的安装包(虽然只说了适用CUDA12.0和CUDA12.1,但本人亲测12.2也可以用):
解压刚下载的TensorRT压缩包,将解压好的文件放置到待安装目录下:

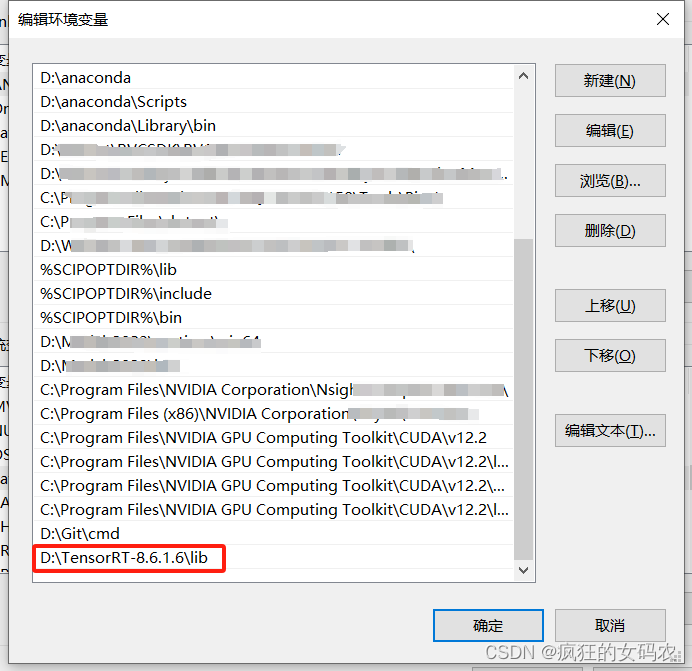
2)配置系统环境
控制面板->系统>高级系统设置–>环境变量–>系统变量–>Path(添加tensorRT的lib路径)
3) 安装 TensorRT Python wheel 文件
打开终端;激活虚拟环境;cd到D:\TensorRT-8.6.1.6\python路径下;查看python版本:

根据当前虚拟环境下的python版本(我的是python3.8),在D:\TensorRT-8.6.1.6\python路径下挑选合适的版本,复制文件名称,在终端采用pip安装:
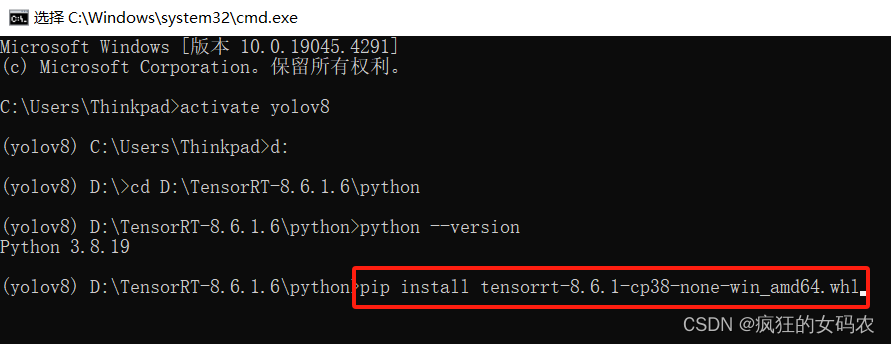
安装完毕后,验证是否安装成功:python -c "import tensorrt;print(tensorrt.__version__)"
如果安装成功会输出TensorRT的版本号。
 2、onnx转engine
2、onnx转engine
将终端路径切换到yolov8文件夹下,输入命令:
D:\TensorRT-8.6.1.6\bin\trtexec.exe --onnx=./runs/detect/train/weights/last.onnx --saveEngine=last.engine --fp16
即可得到我们想要的engine文件。(该过程大约需要3-5分钟,需耐心等待~)
三、推理
在yolov8文件夹下新建inference.py文件,具体内容如下。运行该程序,就完成了模型推理,推理结果保存在/yolov8/output/路径下。
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import shutil
import random
import sys
import threading
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.45
LEN_ALL_RESULT = 705600 ##42000 ##(20*20+40*40+80*80)*(num_cls+4) 一个batch长度
NUM_CLASSES = 1 ##1
OBJ_THRESH = 0.4
def get_img_path_batches(batch_size, img_dir):
ret = []
batch = []
for root, dirs, files in os.walk(img_dir):
for name in files:
if len(batch) == batch_size:
ret.append(batch)
batch = []
batch.append(os.path.join(root, name))
if len(batch) > 0:
ret.append(batch)
return ret
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
class YoLov8TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# Create a Context on this device,
self.ctx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
print('bingding:', binding, engine.get_tensor_shape(binding))
size = trt.volume(engine.get_tensor_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_tensor_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
self.input_w = engine.get_tensor_shape(binding)[-1]
self.input_h = engine.get_tensor_shape(binding)[-2]
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = engine.max_batch_size
def infer(self, raw_image_generator):
threading.Thread.__init__(self)
# Make self the active context, pushing it on top of the context stack.
self.ctx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# Do image preprocess
batch_image_raw = []
batch_origin_h = []
batch_origin_w = []
batch_input_image = np.empty(shape=[self.batch_size, 3, self.input_h, self.input_w])
for i, image_raw in enumerate(raw_image_generator):
input_image, image_raw, origin_h, origin_w = self.preprocess_image(image_raw)
batch_image_raw.append(image_raw)
batch_origin_h.append(origin_h)
batch_origin_w.append(origin_w)
np.copyto(batch_input_image[i], input_image)
batch_input_image = np.ascontiguousarray(batch_input_image)
# Copy input image to host buffer
np.copyto(host_inputs[0], batch_input_image.ravel())
start = time.time()
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# context.execute_async(batch_size=self.batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
end = time.time()
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# Do postprocess
for i in range(self.batch_size):
result_boxes, result_scores, result_classid = self.post_process_new(
output[i * LEN_ALL_RESULT: (i + 1) * LEN_ALL_RESULT], batch_origin_h[i], batch_origin_w[i],
batch_input_image[i]
)
if result_boxes is None:
continue
# Draw rectangles and labels on the original image
for j in range(len(result_boxes)):
box = result_boxes[j]
plot_one_box(
box,
batch_image_raw[i],
label="{}:{:.2f}".format(
categories[int(result_classid[j])], result_scores[j]
),
)
return batch_image_raw, end - start
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
def get_raw_image(self, image_path_batch):
"""
description: Read an image from image path
"""
for img_path in image_path_batch:
yield cv2.imread(img_path)
def get_raw_image_zeros(self, image_path_batch=None):
"""
description: Ready data for warmup
"""
for _ in range(self.batch_size):
yield np.zeros([self.input_h, self.input_w, 3], dtype=np.uint8)
def preprocess_image(self, raw_bgr_image):
"""
description: Convert BGR image to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = raw_bgr_image
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# Calculate widht and height and paddings
r_w = self.input_w / w
r_h = self.input_h / h
if r_h > r_w:
tw = self.input_w
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((self.input_h - th) / 2)
ty2 = self.input_h - th - ty1
else:
tw = int(r_h * w)
th = self.input_h
tx1 = int((self.input_w - tw) / 2)
tx2 = self.input_w - tw - tx1
ty1 = ty2 = 0
# Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, None, (128, 128, 128)
)
image = image.astype(np.float32)
# Normalize to [0,1]
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes numpy, each row is a box [center_x, center_y, w, h]
return:
y: A boxes numpy, each row is a box [x1, y1, x2, y2]
"""
y = np.zeros_like(x)
r_w = self.input_w / origin_w
r_h = self.input_h / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def post_process_new(self, output, origin_h, origin_w, img_pad):
# Reshape to a two dimentional ndarray
c, h, w = img_pad.shape
ratio_w = w / origin_w
ratio_h = h / origin_h
num_anchors = int(((h / 32) * (w / 32) + (h / 16) * (w / 16) + (h / 8) * (w / 8)))
pred = np.reshape(output, (num_anchors, 4 + NUM_CLASSES))
results = []
for detection in pred:
score = detection[4:]
classid = np.argmax(score)
confidence = score[classid]
if confidence > CONF_THRESH:
if ratio_h > ratio_w:
center_x = int(detection[0] / ratio_w)
center_y = int((detection[1] - (h - ratio_w * origin_h) / 2) / ratio_w)
width = int(detection[2] / ratio_w)
height = int(detection[3] / ratio_w)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
else:
center_x = int((detection[0] - (w - ratio_h * origin_w) / 2) / ratio_h)
center_y = int(detection[1] / ratio_h)
width = int(detection[2] / ratio_h)
height = int(detection[3] / ratio_h)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
results.append([x1, y1, x2, y2, confidence, classid])
results = np.array(results)
if len(results) <= 0:
return None, None, None
# Do nms
boxes = self.non_max_suppression(results, origin_h, origin_w, conf_thres=CONF_THRESH, nms_thres=IOU_THRESHOLD)
result_boxes = boxes[:, :4] if len(boxes) else np.array([])
result_scores = boxes[:, 4] if len(boxes) else np.array([])
result_classid = boxes[:, 5] if len(boxes) else np.array([])
return result_boxes, result_scores, result_classid
def bbox_iou(self, box1, box2, x1y1x2y2=True):
"""
description: compute the IoU of two bounding boxes
param:
box1: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
box2: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
x1y1x2y2: select the coordinate format
return:
iou: computed iou
"""
if not x1y1x2y2:
# Transform from center and width to exact coordinates
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# Get the coordinates of the intersection rectangle
inter_rect_x1 = np.maximum(b1_x1, b2_x1)
inter_rect_y1 = np.maximum(b1_y1, b2_y1)
inter_rect_x2 = np.minimum(b1_x2, b2_x2)
inter_rect_y2 = np.minimum(b1_y2, b2_y2)
# Intersection area
inter_area = np.clip(inter_rect_x2 - inter_rect_x1 + 1, 0, None) * \
np.clip(inter_rect_y2 - inter_rect_y1 + 1, 0, None)
# Union Area
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
return iou
def non_max_suppression(self, prediction, origin_h, origin_w, conf_thres=0.5, nms_thres=0.4):
"""
description: Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
param:
prediction: detections, (x1, y1,x2, y2, conf, cls_id)
origin_h: original image height
origin_w: original image width
conf_thres: a confidence threshold to filter detections
nms_thres: a iou threshold to filter detections
return:
boxes: output after nms with the shape (x1, y1, x2, y2, conf, cls_id)
"""
# Get the boxes that score > CONF_THRESH
boxes = prediction[prediction[:, 4] >= conf_thres]
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
# boxes[:, :4] = self.xywh2xyxy(origin_h, origin_w, boxes[:, :4])
# clip the coordinates
boxes[:, 0] = np.clip(boxes[:, 0], 0, origin_w)
boxes[:, 2] = np.clip(boxes[:, 2], 0, origin_w)
boxes[:, 1] = np.clip(boxes[:, 1], 0, origin_h)
boxes[:, 3] = np.clip(boxes[:, 3], 0, origin_h)
# Object confidence
confs = boxes[:, 4]
# Sort by the confs
boxes = boxes[np.argsort(-confs)]
# Perform non-maximum suppression
keep_boxes = []
while boxes.shape[0]:
large_overlap = self.bbox_iou(np.expand_dims(boxes[0, :4], 0), boxes[:, :4]) > nms_thres
label_match = boxes[0, -1] == boxes[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
keep_boxes += [boxes[0]]
boxes = boxes[~invalid]
boxes = np.stack(keep_boxes, 0) if len(keep_boxes) else np.array([])
return boxes
def img_infer(yolov5_wrapper, image_path_batch):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image(image_path_batch))
for i, img_path in enumerate(image_path_batch):
parent, filename = os.path.split(img_path)
save_name = os.path.join('output', filename)
# Save image
cv2.imwrite(save_name, batch_image_raw[i])
print('input->{}, time->{:.2f}ms, saving into output/'.format(image_path_batch, use_time * 1000))
def warmup(yolov5_wrapper):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image_zeros())
print('warm_up->{}, time->{:.2f}ms'.format(batch_image_raw[0].shape, use_time * 1000))
if __name__ == "__main__":
engine_file_path = r"E:\yolov8\last.engine"
# load coco labels
categories = ["dog", "cat", "rabbit", "people", "car"]
if os.path.exists('output/'):
shutil.rmtree('output/')
os.makedirs('output/')
yolov8_wrapper = YoLov8TRT(engine_file_path)
try:
print('batch size is', yolov8_wrapper.batch_size)
image_dir = r"E:\yolov8\data\data_nc5\test_images"
image_path_batches = get_img_path_batches(yolov8_wrapper.batch_size, image_dir)
for i in range(10):
warmup(yolov8_wrapper)
for batch in image_path_batches:
img_infer(yolov8_wrapper, batch)
finally:
yolov8_wrapper.destroy()















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









