







Cats vs. Dogs(猫狗大战)来源于 Kaggle
上的一个竞赛,内容非常简单,
Kaggle 提供了一个猫和狗的数据集,我们需要建立一个算法进行训练,最后这个算法要能准确识别出猫和狗。Kaggle
提供的数据集分为训练集和测试集,训练集包含猫和狗各 12500
张图片 测试集包含
12500
张猫和狗的图片。
数据来源:Kaggle
上
Cats vs. Dogs
的网址为
https://www.kaggle.com/c/dogs-vs-cats
。
这里主要选取了深度学习中VGG16模型,使用tensorflow-gpu2.6.0版本环境。
数据划分:选取了下载的数据集中train文件夹中的3000张图片作为本次实验的主要数据集。将猫狗各1000张图片放入其目录下用于训练的train文件夹中,即用于训练train文件夹中的数据集一共有2000张图片;将猫狗各500张图片放入其目录下用来验证的validation文件夹中,即用于验证的validation的文件夹中一共有1000张图片;将猫狗各500张图片放入test文件夹中,即用于测试的test文件中一共有1000张图片,划分情况如下:
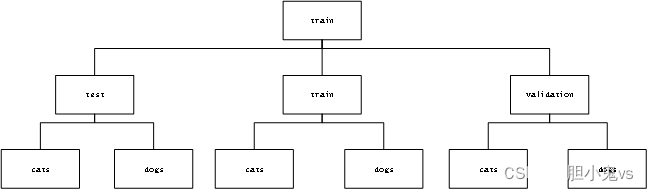
(1)数据划分:
#从训练集中选取4000张图片,2000张用于训练,1000张用于验证,1000张用于测试
import os, shutil
original_dataset_dir = './DataSet/train'
base_dir ='./train_dataset/train'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 训练集文件
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
# 验证集文件
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
#测试集文件
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
#train--cats
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
#validation---cats
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
#test---cats
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
(2)基于VGG16构建模型:
from keras import models, layers
from tensorflow.keras.applications import VGG16
from tensorflow import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
#训练样本的目录
train_dir='./train_dataset/train/train'
#验证样本的目录
validation_dir='./train_dataset/train/validation'
#测试样本目录
test_dir='./train_dataset/train/test'
#训练集生成器---训练集数据加强
train_datagen=ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
train_generator=train_datagen.flow_from_directory(
directory=train_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
#验证样本生成器
validation_datagen=ImageDataGenerator(rescale=1./255)
validation_generator=validation_datagen.flow_from_directory(
directory=validation_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
#测试样本生成器
test_datagen=ImageDataGenerator(rescale=1./255)
test_generator=test_datagen.flow_from_directory(
directory=test_dir,
target_size=(150,150),
class_mode='binary',
batch_size=20
)
print(train_generator.class_indices)
print(test_generator.class_indices)
print(validation_generator.class_indices)
#VGG 16实例化---使用imagenet数据集训练,不包含顶层(即全连接层)
conv_base = VGG16(weights='imagenet',
include_top=False, #是否指定模型最后是否包含密集连接分类器
input_shape=(150, 150, 3))
#冻结卷积基----保证其权重在训练过程中不变--不训练这个,因为参数太多
conv_base.trainable = False
#构建网络模型----基于VGG16建立模型
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten(input_shape=conv_base.output_shape[1:])) #图片输出四维,1代表数量
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid')) #二分类
#定义优化器、代价函数、训练过程中计算准确率
model.compile(optimizer=optimizers.Adam(lr=0.0005/10),
loss='binary_crossentropy',
metrics=['acc'])
model.summary()
#拟合模型
history=model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=20,
validation_data=validation_generator,
validation_steps=50
)
#保存模型
model.save('./model/data/model4_2_VGG 16_cats_vs_dogs_1.h5')
#评估测试集的准确率
test_eval=model.evaluate_generator(test_generator)
print("测试集准确率:",test_eval)
train_eval=model.evaluate_generator(train_generator)
print("训练集准确率:",train_eval)
val_eval=model.evaluate_generator(validation_generator)
print("验证集准确率:",val_eval)
#绘制训练过程中的损失曲线和精度曲线
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo')
plt.plot(epochs, acc, 'b', label='Training acc')
plt.plot(epochs,val_acc, 'ro')
plt.plot(epochs, val_acc, 'r', label='Validation acc')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo')
plt.plot(epochs, loss,'b', label ='Training Loss')
plt.plot(epochs, val_loss,'ro')
plt.plot(epochs, val_loss,'r',label='Validation Loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Training Loss and Validation Loss")
plt.legend()
plt.show()模型训练20次的训练过程:
 模型训练后得到训练集验证集的准确率与损失率的效果:
模型训练后得到训练集验证集的准确率与损失率的效果:

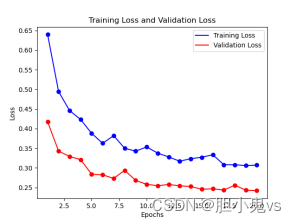
从test测试集中选取猫50张图片,狗50张图片组成新的一个test2进行模型的预测:
在test2文件夹中同样分cats、dogs两个分类,其中在cats有50张猫的图片,dogs中50张狗的图片
from keras.models import load_model
from keras.preprocessing.image import ImageDataGenerator, img_to_array,load_img
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.metrics import recall_score
#加载模型
model = load_model('./model/data/model4_2_VGG 16_cats_vs_dogs_1.h5')
model.summary()
test_datagen=ImageDataGenerator(rescale=1./255)
test_generator=test_datagen.flow_from_directory(
directory="./train_dataset/test2",
target_size=(150,150),
shuffle=False, #不打乱数据集
class_mode='binary',
batch_size=20
)
# print(test_datagen)
# print(test_generator.labels)
#预测
result=model.predict(test_generator) #y_pred
result = [(int) ((result[i][0] + 0.5) / 1.0) for i in range(len(result))] #转为整数
print(result)
test_label=test_generator.classes #y_test
print(test_label)
#分类报告
from sklearn.metrics import classification_report
print("分类报告:\n",classification_report(test_label, result))
print("混淆矩阵:\n",confusion_matrix(test_label, result))
print("召回率:",recall_score(test_label,result))
#绘制混淆矩阵
predict = ["cat","dog"]
fact = ["cat","dog"]
classes = list(set(fact))
r1 = confusion_matrix(test_label, result)
plt.figure(figsize=(12,10))
confusion = r1
plt.imshow(confusion, cmap=plt.cm.Blues)
indices = range(len(confusion))
indices2 = range(3)
plt.xticks(indices,classes,rotation=40,fontsize=18)
plt.yticks([0.00,1.00],classes,fontsize=18)
plt.ylim(1.5,-0.5) #设置y的纵坐标的上下限
plt.title("Confusion matrix",fontdict={'weight':'normal','size':18})
#设置color bar的标签大小
cb = plt.colorbar()
cb.ax.tick_params(labelsize=18)
plt.xlabel('Predict label',fontsize=18)
plt.ylabel('True label',fontsize=18)
print("len(confusion",len(confusion))
for first_index in range(len(confusion)):
for second_index in range(len(confusion[first_index])):
if confusion[first_index][second_index]>200:
color='black'
else:
color="black"
plt.text(first_index,second_index,confusion[first_index][second_index],fontsize=18,color=color,verticalalignment='center',horizontalalignment='center')
# plt.show()
#绘画错分报告
#使用迭代器选取图片的x_test--遍历整个test2文件夹--test2中有100张图片
count=0
it=iter(test_generator)
x_test,_ = next(test_generator)
print(_)
for x in it:
yy,_ = x
x_test = np.concatenate((x_test,yy),axis=0)
count+=1
if count==100:
break
#绘画错分报告
result = np.reshape(result, (-1, 1))
test_label = np.reshape(test_label, (-1, 1))
ins = test_label != result
diff_index = np.where(ins == True)[0] # 查找不相同的下标
# print("diff_index:",diff_index)
numForPaint = 8 #只选取前8张错分图片
plt.figure()
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负
lables = ['猫','狗']
for i in range(numForPaint): #只显示前8个
j=diff_index[i]
img = x_test[j]
y_t = test_label[j][0]
y_p = result[j][0]
plt.subplot(2, 4, i + 1, xticks=[], yticks=[]) # 2*8子图显示
plt.imshow(img) # 黑白显示
plt.title(f'{lables[y_t]}--> {lables[y_p]}') # 显示标题
plt.subplots_adjust(wspace=0.1, hspace=0.2) # 调整子图间距
plt.show()
得到的分类报告结果:
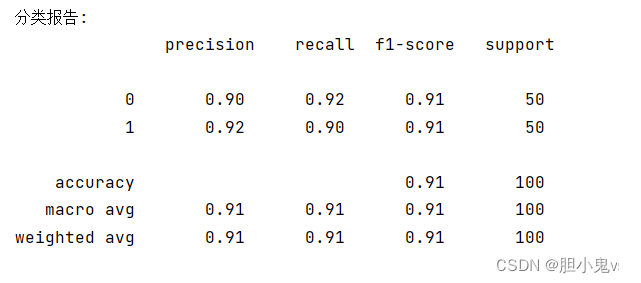
混淆矩阵:
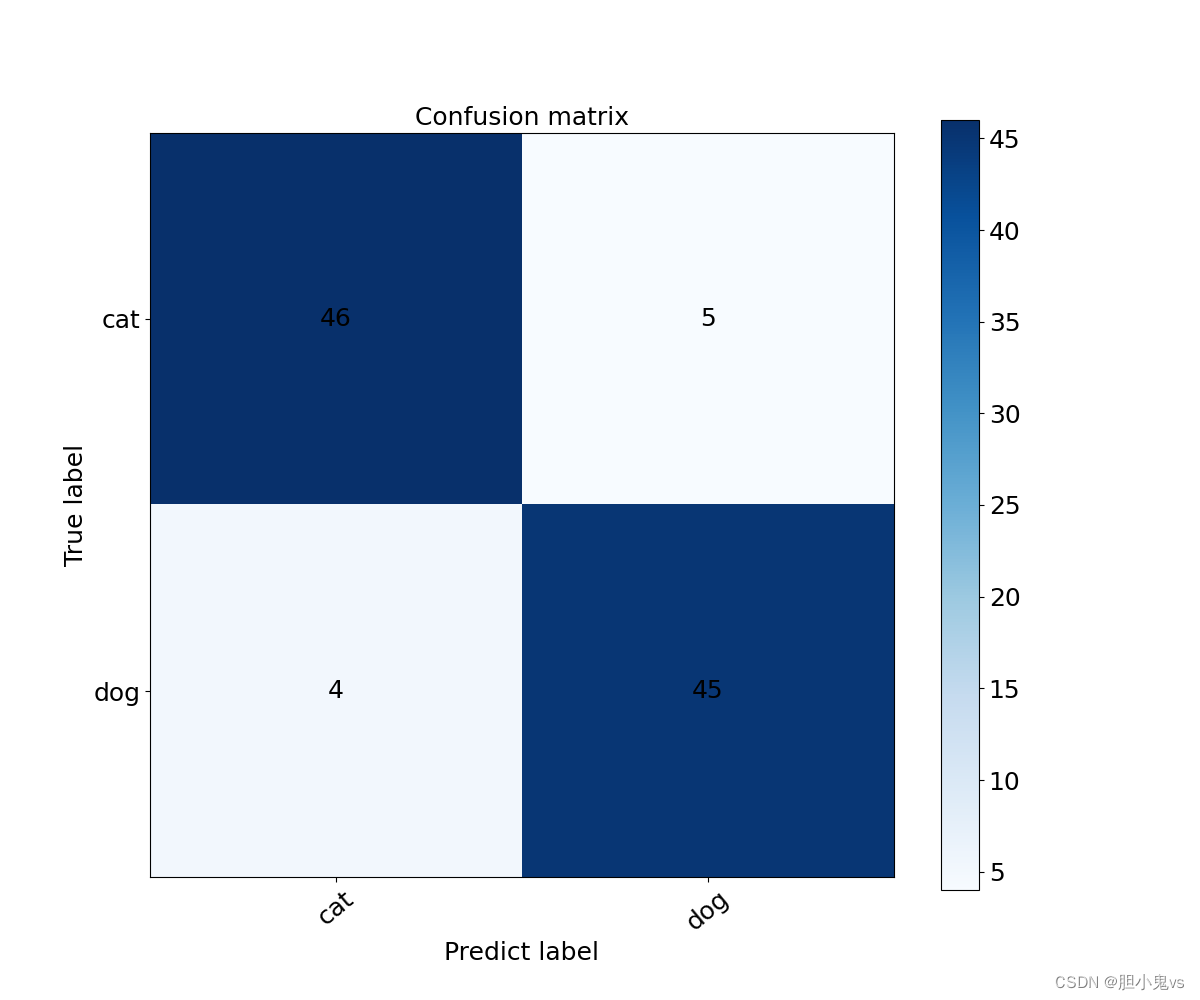
错分报告:
















 3762
3762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









