







前言
这是李宏毅机器学习系列的一个补充博客,对于课程中一些比较模糊的重点会再次进行梳理,起到一个修补的作用
背景
本篇背景是对于机器学习中的神经网络进行梳理,由于李宏毅老师在讲解过程中将神经网络进行了拆分,容易导致初学者对于神经网络不能整体把握,本篇则是作者根据课程和一些博客,对神经网络的进行一次整体梳理。
整体把握
神经网络最基本的模型是由4个函数组成的。它们分别是:
传播函数、激活函数、反向传播函数、损失函数
它们分别实现了几个核心功能:预测、输出映射、反向优化、损失计算
字面上的意思还是比较抽象,我们先来看一下单个神经元的构成图:

神经元中
x
i
x_i
xi是输入信号、
w
i
w_i
wi和
b
i
b_i
bi是预测参数、
a
a
a是预测的基本结果、
h
(
)
h()
h()是激活函数、
y
y
y是最终预测结果以及下一层神经元的输入。
在训练阶段我们输入大量的数据 x i x_i xi,然后根据 y y y的结果来反向传播,得到 d w 和 d b dw和db dw和db,然后进行梯度下降,来对 w i w_i wi和 b i b_i bi进行优化。
以 M N I S T MNIST MNIST数据集为例,来介绍上述过程。
在训练阶段中,流程如下图所示:

测试阶段,流程如下:

接下来,我们再对四大函数进行逐一讲解:
传播函数
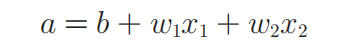
上图是一个典型的传播函数。其中的
w
i
和
b
w_i和b
wi和b的具体意义已经在之前的博客中详细的讲解过了,这里不再赘述。
以下是上图中的参数的意义
权重 w i w_i wi的意义在于体现出 x x x中哪些特征比较重要,比如优化后的 w 1 w_1 w1如果比 w 2 w_2 w2值更大,则说明 x 1 x_1 x1较 x 2 x_2 x2更重要。 b b b的意义就是给网络分类增加平移的能力,使其能够更好的拟合。
激活函数
激活函数有很多类,最常用的就是sigmoid函数,我们也用这个函数来做例子。

从数学上来解析这个式子,我们可以知道:
1 ) 当 x 为 0 时 , h ( x ) 输 出 为 0.5 。 1)当x为0时,h(x)输出为0.5。 1)当x为0时,h(x)输出为0.5。
2 ) 当 x 趋 向 于 负 数 , 且 负 的 越 多 则 h ( x ) 趋 向 于 0 2)当x趋向于负数,且负的越多则h(x)趋向于0 2)当x趋向于负数,且负的越多则h(x)趋向于0
3 ) 当 x 趋 向 于 正 数 , 且 正 的 越 多 则 h ( x ) 趋 向 于 1 3)当x趋向于正数,且正的越多则h(x)趋向于1 3)当x趋向于正数,且正的越多则h(x)趋向于1
从数学的角度来理解,它是将X轴的值映射到了Y轴,如此实现了输入值在0~1区间上的转化。有了激活函数,我们就可以方便地与标签进行对比,以此为基础实现参数的优化。
下图是sigmoid函数的图像:

反向传播函数
反向传播的理解比较困难,所以我们可以先对反向传播进行以下总结,再去作详细的解释:
1)传播函数通过w、b计算出A,通过激活函数又计算出Y
2)反向传播函数通过Y计算出dw和db
3)使用dw和db,通过一种叫“梯度下降”的方法得到新的w和b
4)使用更新后的w和b重复前面的运算过程
需要注意的是, “梯度下降”是一种更新w和b的方法,不同模型可能会使用不同的方法来更新w和b,只是我们这里使用这个比较容易理解的方法而已。而反向传播的原理在之前的博文中已经详细的说明了,这里不再赘述。
损失函数
损失函数并不是固定的,要根据问题的类型来进行选择,以回归问题为例,使用均方差来作为Loss,这里没其他补充的,详见之前的博客。
总结
本文梳理了神经网络的工作流程和函数功能,使之前零散的知识通过流程图串联起来。















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









