







一、项目简介
帕尔默企鹅数据集是近年来在数据科学和机器学习领域受到关注的一个数据集,经常被用作鸢尾花数据集的一个替代品。数据集包含了对南极洲不同地区生活的企鹅种群的研究数据,主要用于数据探索和可视化,以及分类任务。本文参考了网上的各种代码,使用了sklearn机器学习库编码实现了四种分类器算法:逻辑回归、支持向量机、K邻近、随机森林、梯度提升。
二、数据预处理与分析
我们从kaggle官网下载下来的数据包括两个文件:penguins_lter.csv和penguins_size.csv
数据下载地址:Palmer Archipelago (Antarctica) penguin data | Kaggle
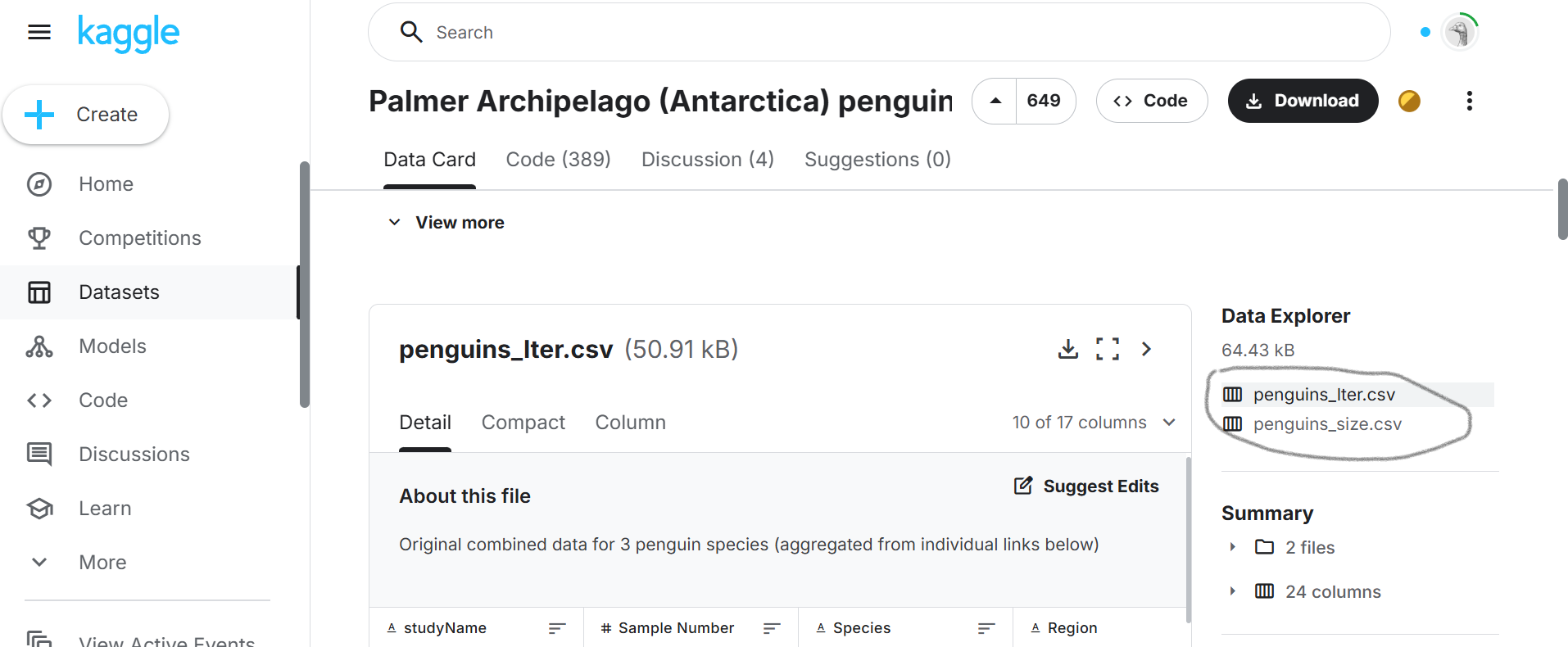

Kaggle所提供的数据描述如下:
| 列标题 | 含义 |
| species | 企鹅的物种名称 |
| island | 企鹅所在的岛屿名称 |
| culmen_length_mm | 企鹅喙部的长度,单位为毫米(mm) |
| culmen_depth_mm | 企鹅喙部的深度,单位为毫米(mm) |
| flipper_length_mm | 企鹅鳍的长度,单位为毫米(mm) |
| body_mass_g | 企鹅的体重,单位为克(g) |
| sex | 企鹅的性别 |
| 列标题 | 含义 |
| studyName | 研究的名称 |
| Sample Number | 样本编号 |
| Species | 企鹅的物种名称 |
| Region | 企鹅所在的区域 |
| Island | 企鹅所在的岛屿名称 |
| Stage | 企鹅的生活阶段 |
| Individual ID | 个体企鹅的标识符 |
| Clutch Completion | 孵化是否完成 |
| Date Egg | 企鹅蛋的日期 |
| culmen_length_mm | 企鹅喙部的长度,单位为毫米(mm) |
| culmen_depth_mm | 企鹅喙部的深度,单位为毫米(mm) |
| flipper_length_mm | 企鹅鳍的长度,单位为毫米(mm) |
| Body Mass (g) | 企鹅的体重,单位为克(g) |
| Sex | 企鹅的性别 |
| Delta 15 N (o/oo) | 氮同位素比率 |
| Delta 13 C (o/oo) | 碳同位素比率 |
| Comments | 额外的评论或备注信息 |
第一步:导入数据并初探
(1) 导入必要的包
# 导入必要的库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score(2)分析数据
print(train_data.shape, test_data.shape)![]()
print(train_data.info()) # 查看具体字段信息
print(test_data.info()) # 查看具体字段信息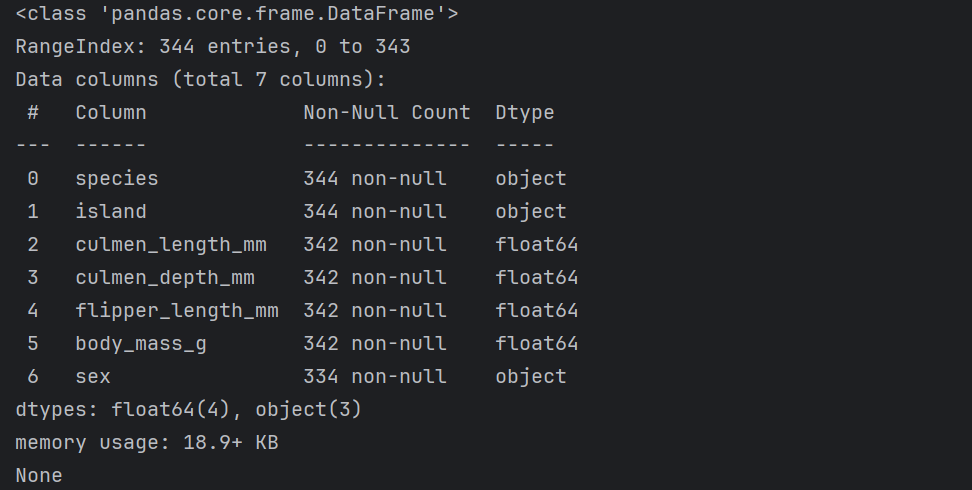
print(train_data.head()) # 查看头几行
print(test_data.head()) # 查看头几行
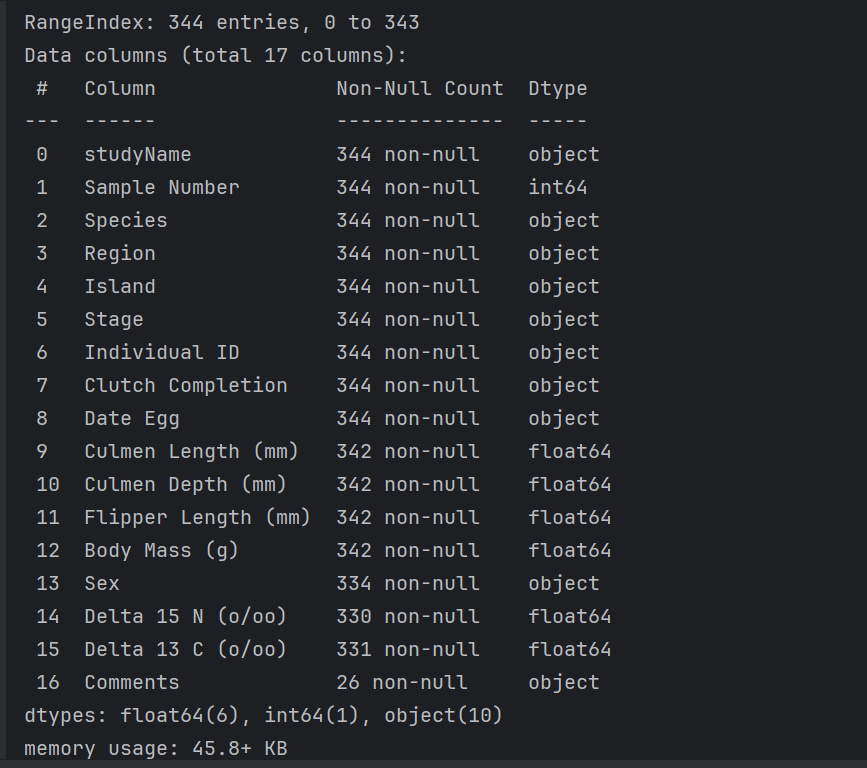
第二步:数据预处理
# 合并数据
data = pd.concat([data1, data2])
# 处理缺失值
data = data.dropna()
# 转换分类变量
data = pd.get_dummies(data, columns=['species', 'island', 'sex'], drop_first=True)
# 查看前几行数据
print(data.head())第三步:数据分析及可视化
1)单维度特征可视化
(1)物种分布
clean_size_df = train_data.dropna()
#物种分布
plt.figure(figsize=(8, 6))
sns.countplot(data=data, x='species', palette='pastel')
plt.title('Species Distribution')
plt.show()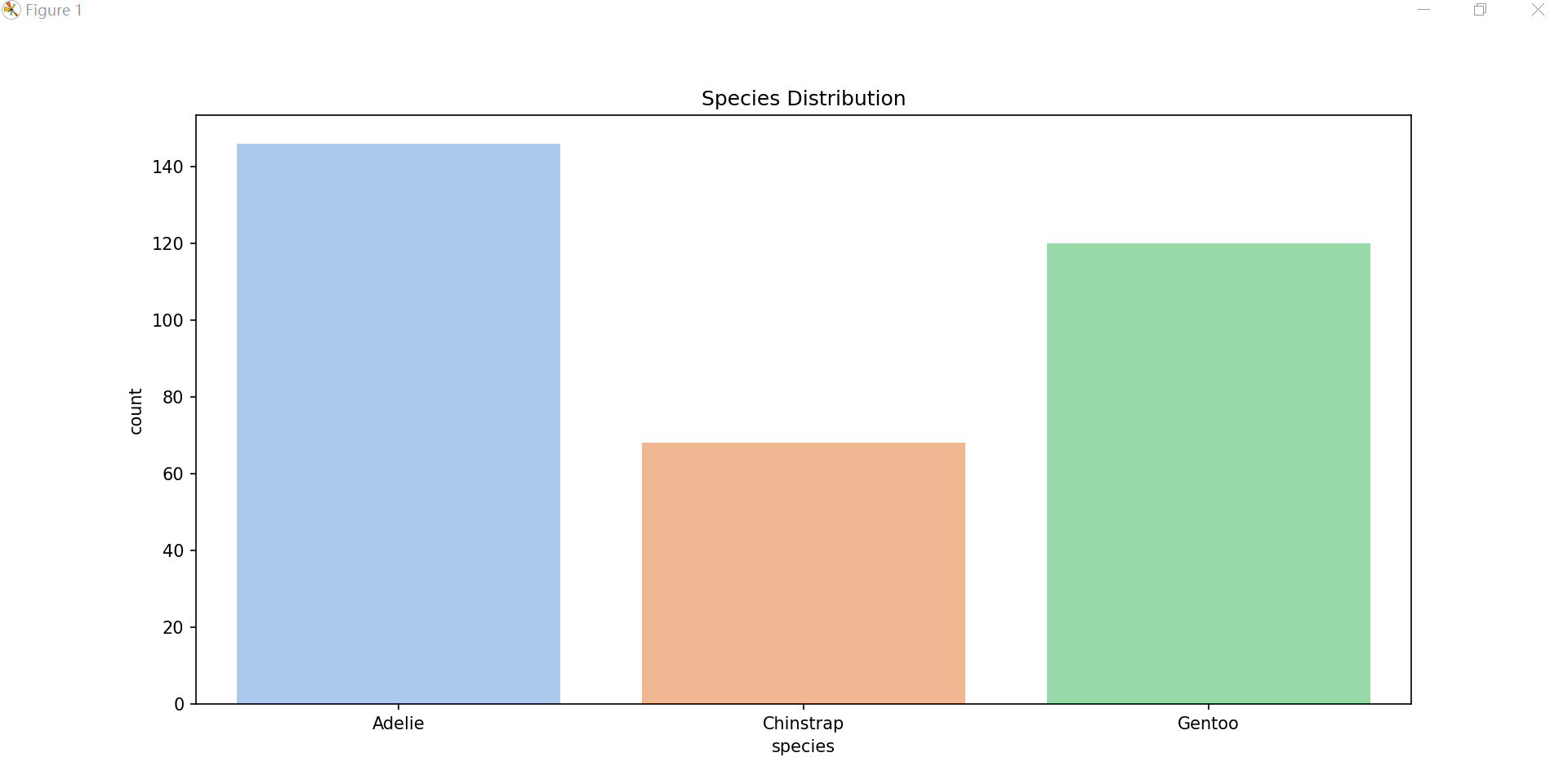
(2)岛屿分布
#岛屿分布
clean_size_df = train_data.dropna()
plt.figure(figsize=(8, 6))
sns.countplot(x='island', data=data,hue='species', palette='Set2')
plt.title('岛屿分布')
plt.show()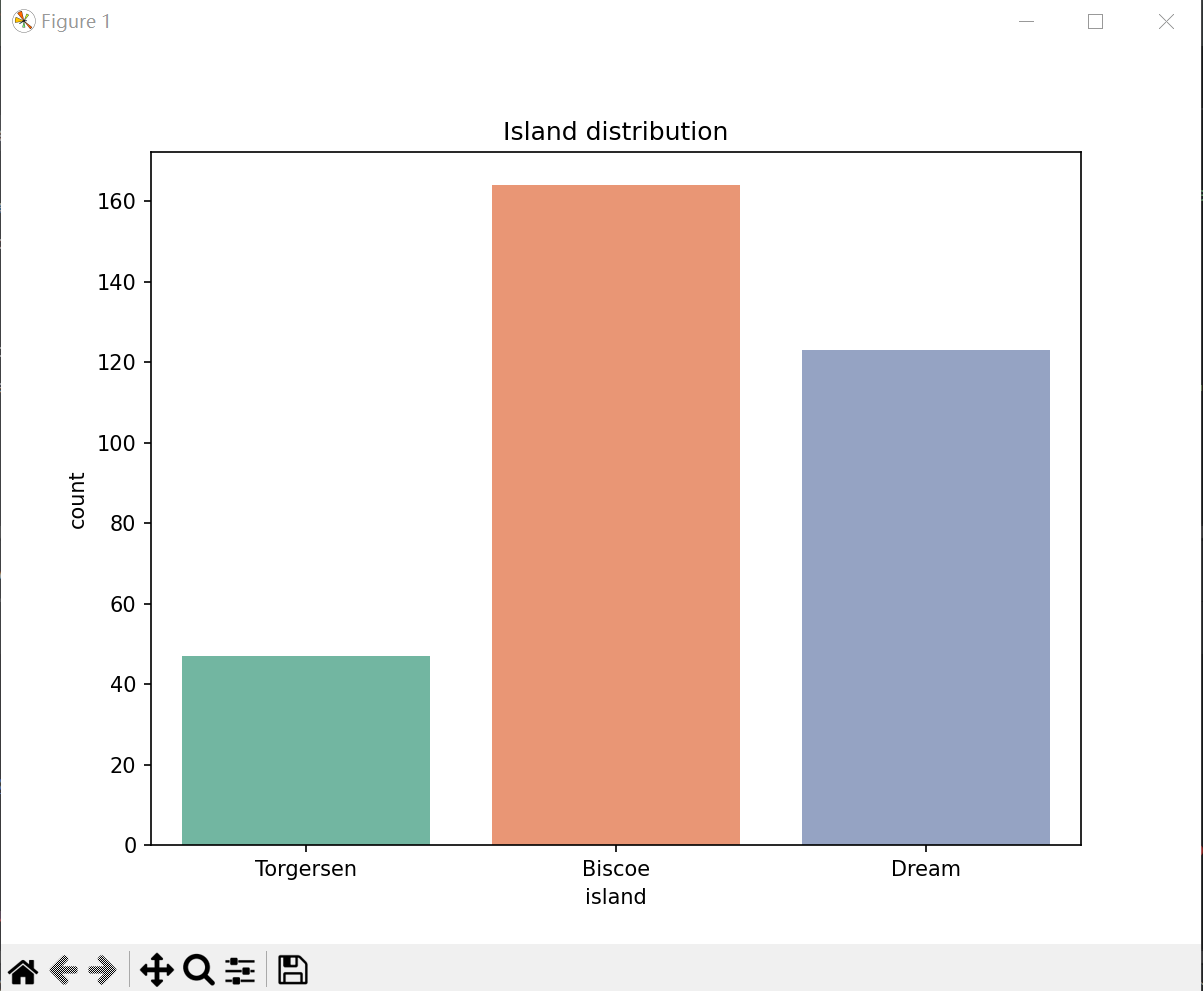
(3) 喙部长度分布
# 喙部长度分布
clean_size_df = train_data.dropna()
plt.figure(figsize=(8, 6))
sns.histplot(data['culmen_length_mm'], kde=True)
plt.title('Beak length distribution')
plt.show()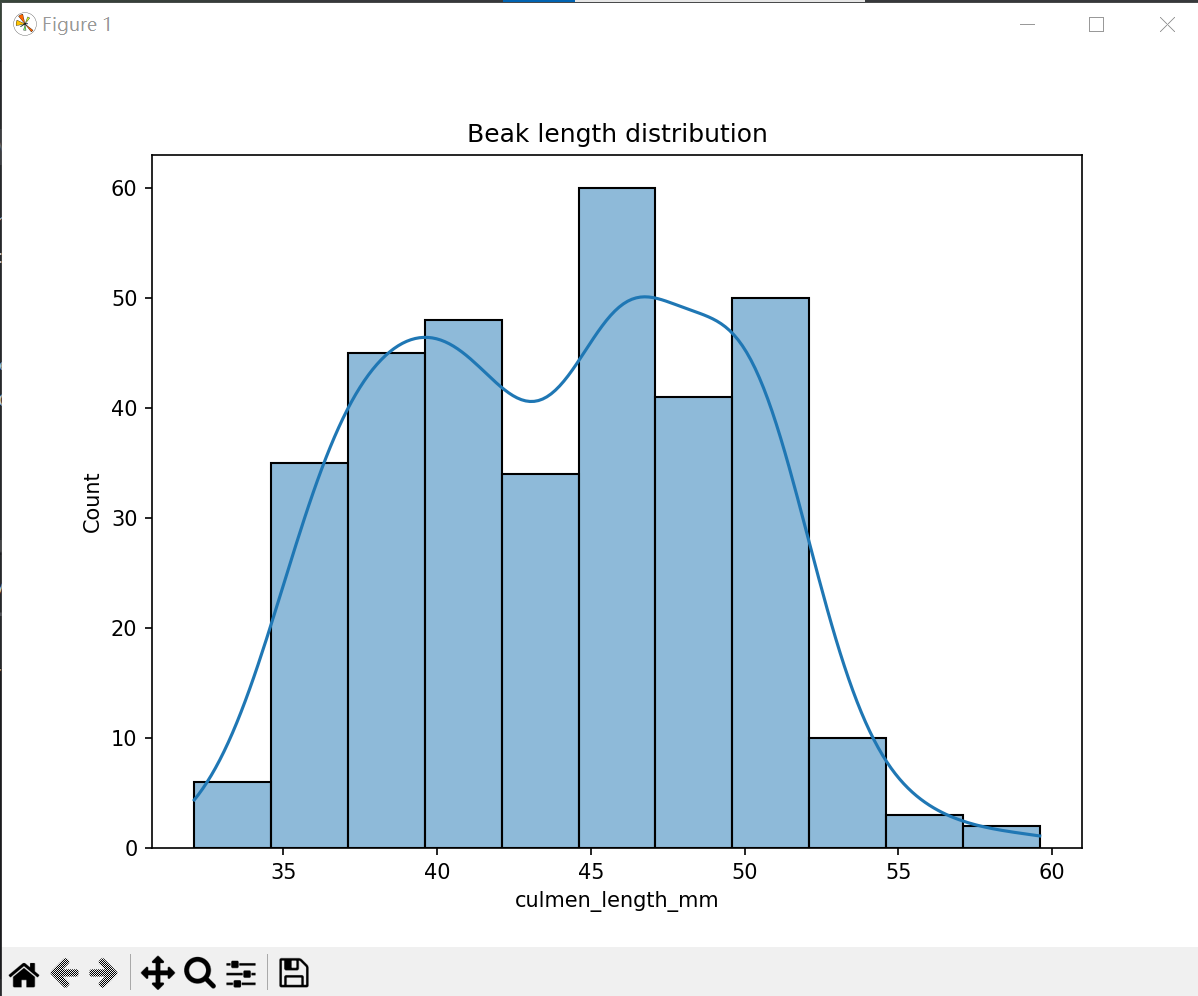
(4) 鳍长度分布
# 鳍长度分布
clean_size_df = train_data.dropna()
plt.figure(figsize=(8, 6))
sns.histplot(data['flipper_length_mm'], kde=True)
plt.title('Fin length distribution')
plt.show()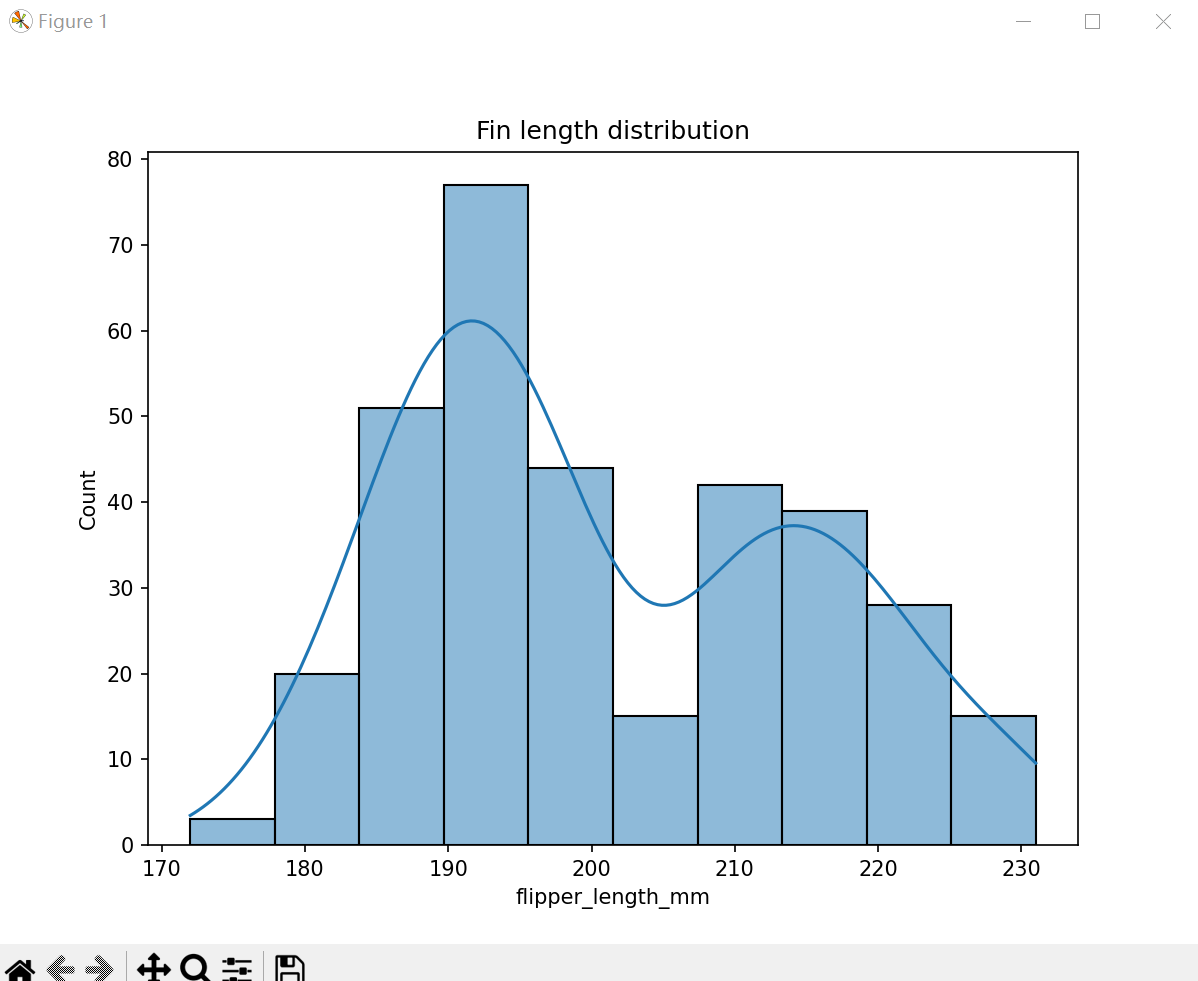
(5) 性别比例
#性别比例
clean_size_df = train_data.dropna()
plt.figure(figsize=(8, 6))
sns.countplot(x='sex', data=clean_size_df)
plt.title('Sex ratio')
plt.show()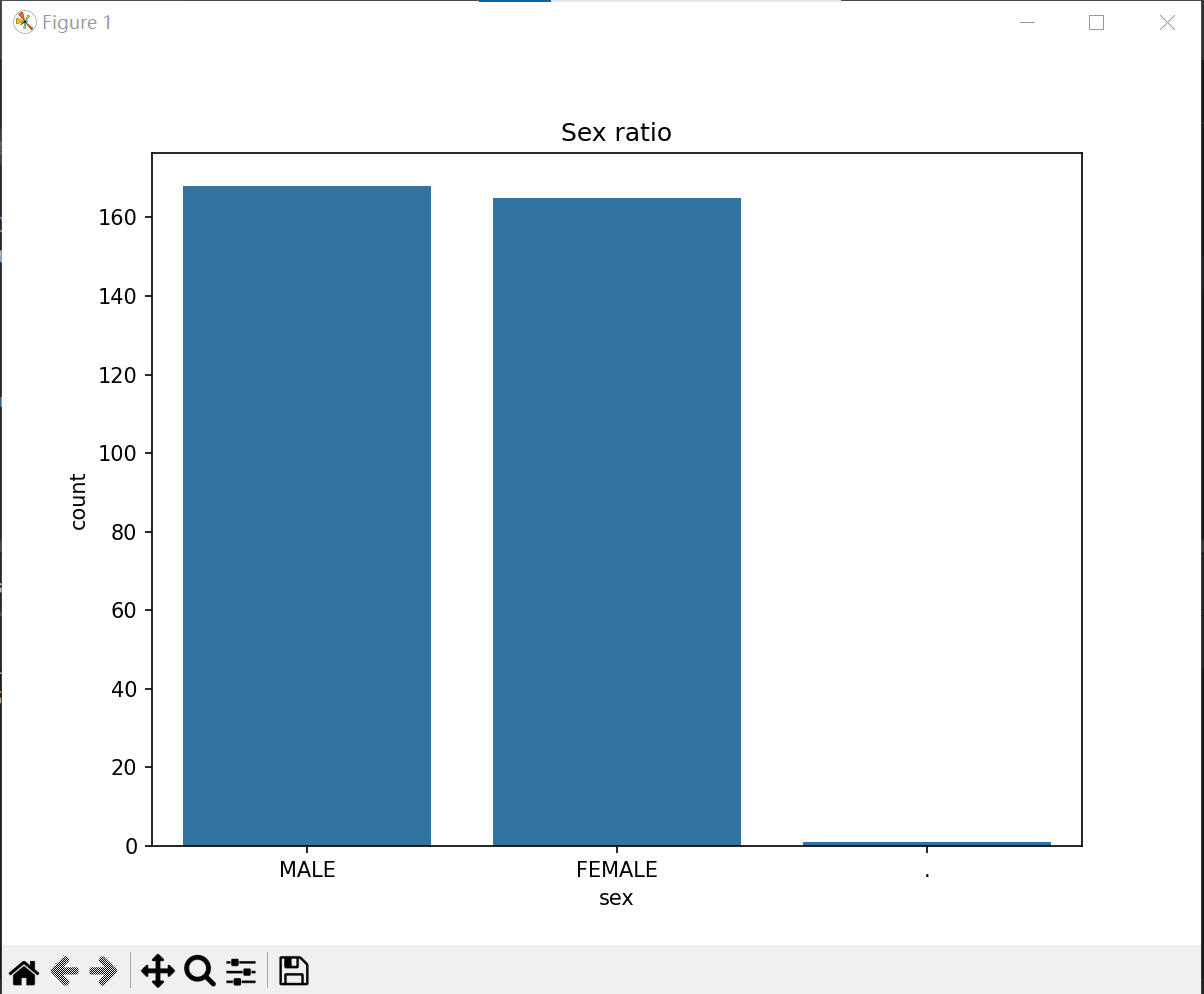
1)多维度特征可视化
(1)物种与岛屿的关系
clean_size_df = train_data.dropna()
# 物种与岛屿的关系
plt.figure(figsize=(8, 6))
sns.countplot(x='island', hue='species', data=clean_size_df, palette='Set2')
plt.title('Species per Island')
plt.show()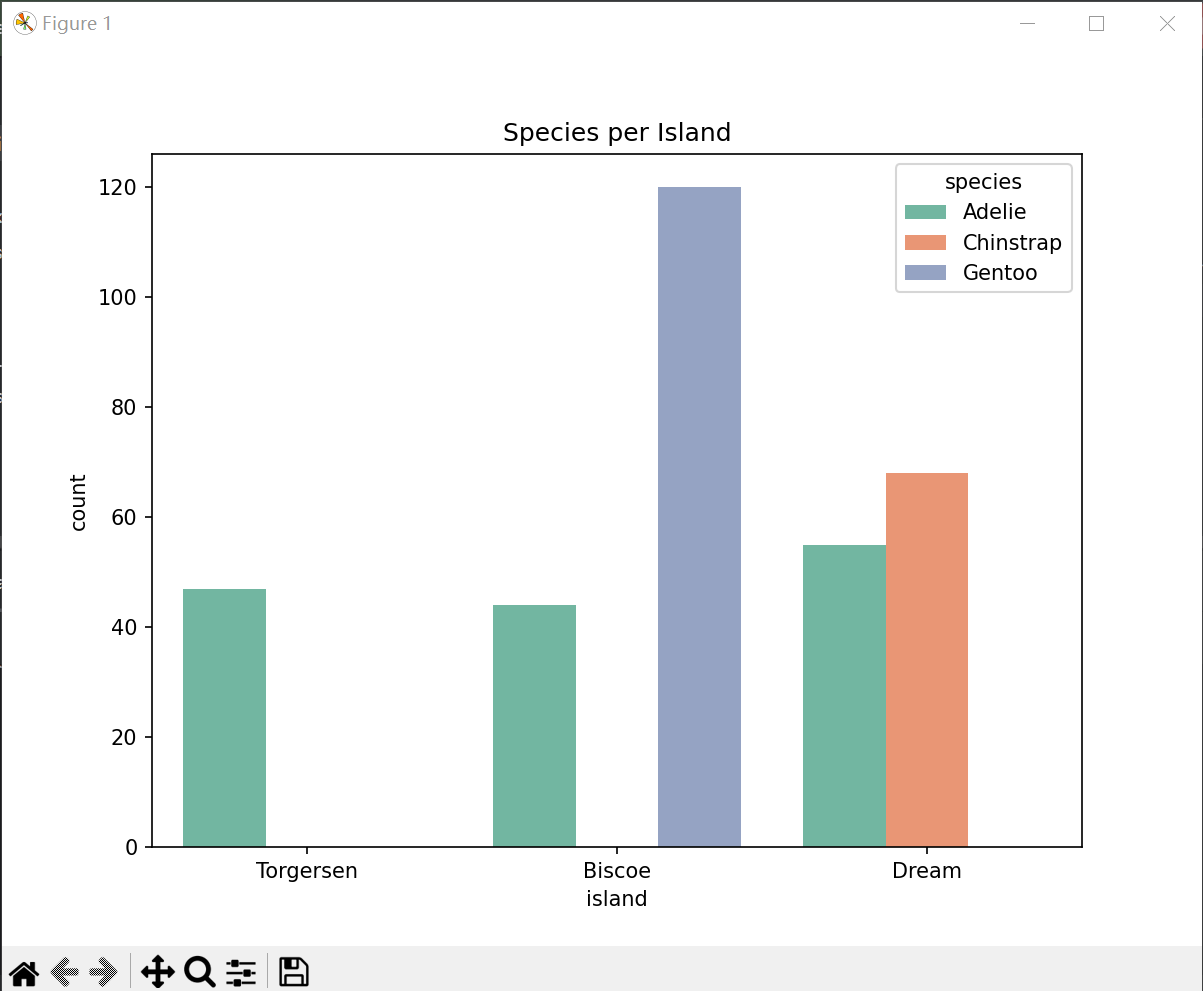
(2) 喙部长度与深度的关系
# 喙部长度与深度的关系
sns.scatterplot(data=clean_size_df, x='culmen_length_mm', y='culmen_depth_mm', hue='species')
plt.title('Culmen Length vs Depth by Species')
plt.xlabel('Culmen Length (mm)')
plt.ylabel('Culmen Depth (mm)')
plt.show()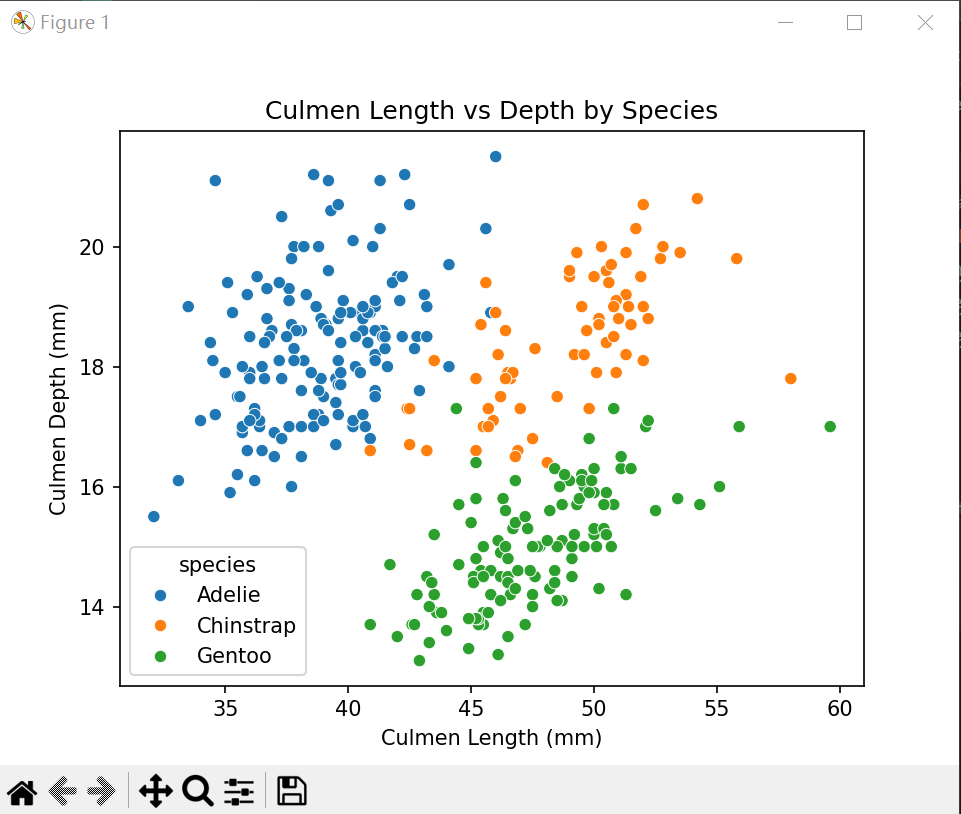
(3) 物种与鳍长度的关系
clean_size_df = train_data.dropna()
# 物种与鳍长度的关系
plt.figure(figsize=(8, 6))
sns.boxplot(x='species', y='flipper_length_mm', data=clean_size_df)
plt.title('species and fin length')
plt.show()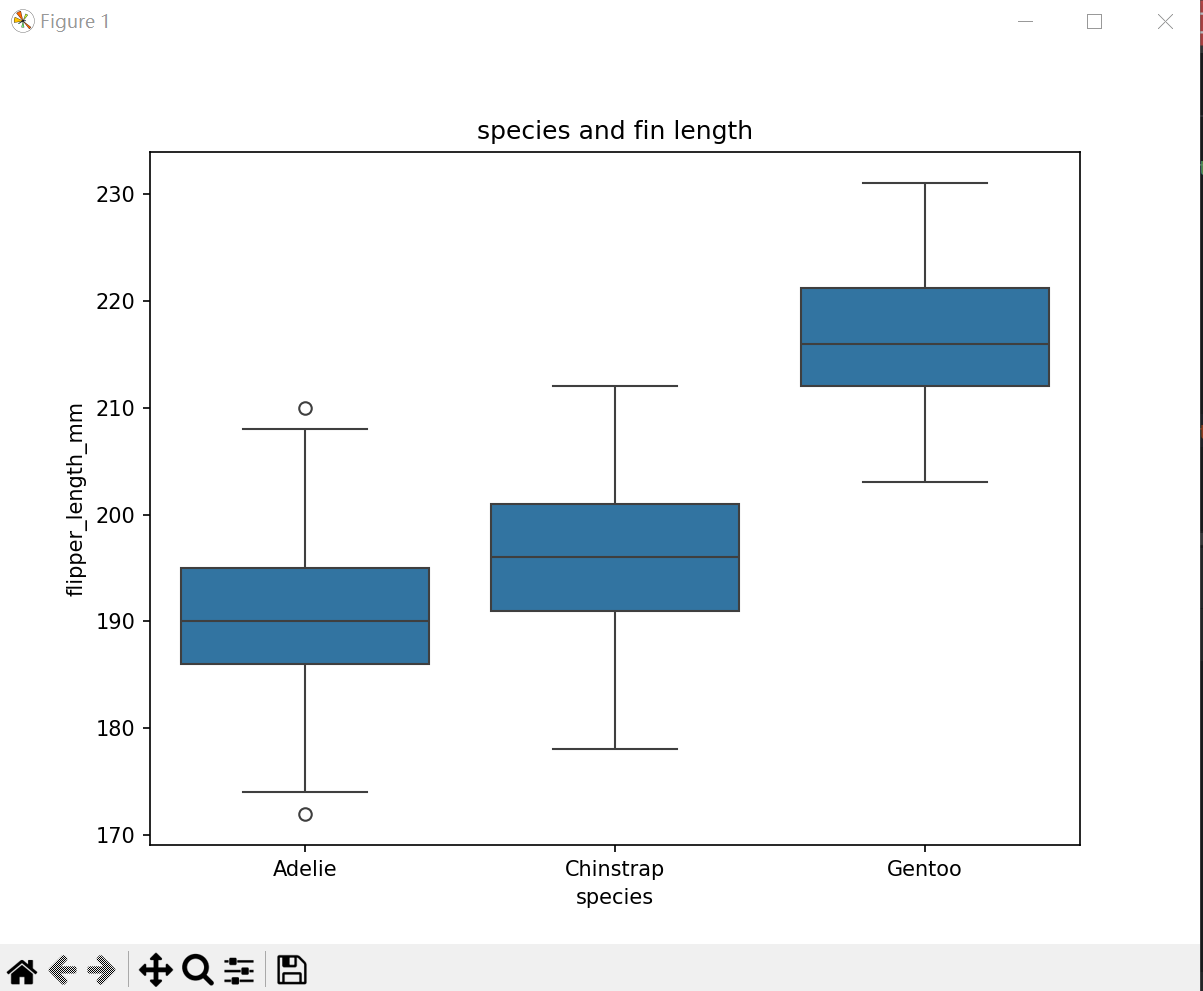
(4)体重与物种的关系
clean_size_df = train_data.dropna()
# 体重与物种的关系
plt.figure(figsize=(8, 6))
sns.boxplot(x='body_mass_g', y='species', data=clean_size_df)
plt.title('species and weight')
plt.show()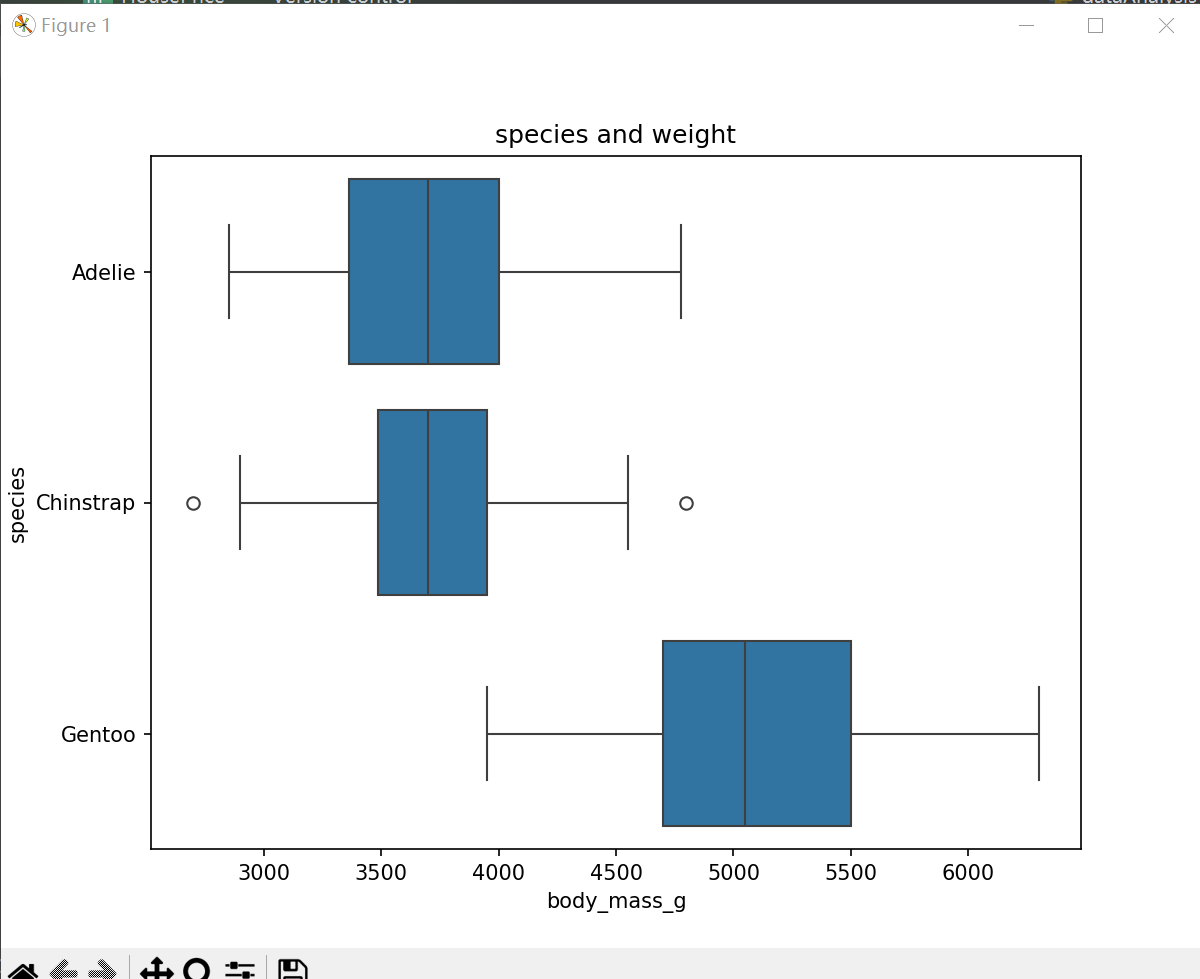
(5) 性别与物种的关系
clean_size_df = train_data.dropna()
# 性别与物种的关系
plt.figure(figsize=(8, 6))
sns.countplot(x='species', hue='sex', data=clean_size_df)
plt.title('sex and species')
plt.show()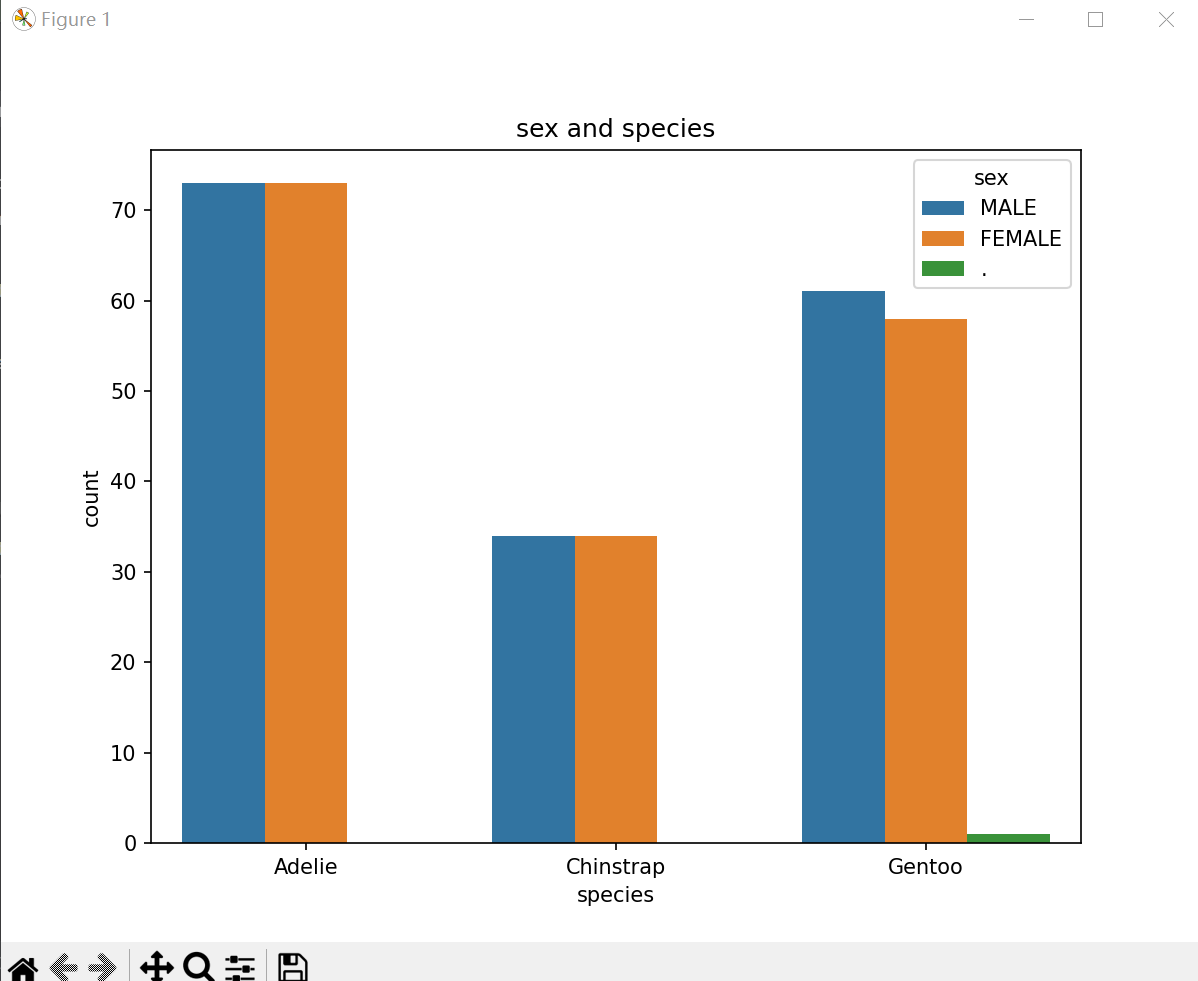
第四步:特征工程
# 特征工程
# 定义特征和目标变量
X = data.drop(columns=['species'])
y = data['species']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)第五步:构建模型
分别采用逻辑回归(Logistic Regression)、支持向量机(Support Vector)、K邻近(K-Nearest Neighbors)、随机森林(Random Forest)、梯度提升(Gradient Boosting)来构建模型进行数据分析
# 定义多个模型
models = {
'Logistic Regression': LogisticRegression(max_iter=1000),
'Support Vector Machine': SVC(probability=True),
'K-Nearest Neighbors': KNeighborsClassifier(n_neighbors=5),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'Gradient Boosting': GradientBoostingClassifier(n_estimators=100, random_state=42)
}
# 训练和评估每个模型
for name, model in models.items():
print(f"\n训练和评估模型:{name}")
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"模型:{name}")
print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred))
print("\n准确率:", accuracy_score(y_test, y_pred))
# 特征重要性(仅适用于支持特征重要性评估的模型)
if hasattr(model, 'feature_importances_'):
feature_importances = pd.Series(model.feature_importances_, index=X.columns)
plt.figure(figsize=(10, 6))
feature_importances.nlargest(10).plot(kind='barh')
plt.title(f'{name} - Feature Importances')
plt.show()
(1) 随机森林(Random Forest)模型的分析结果及特征重要性:
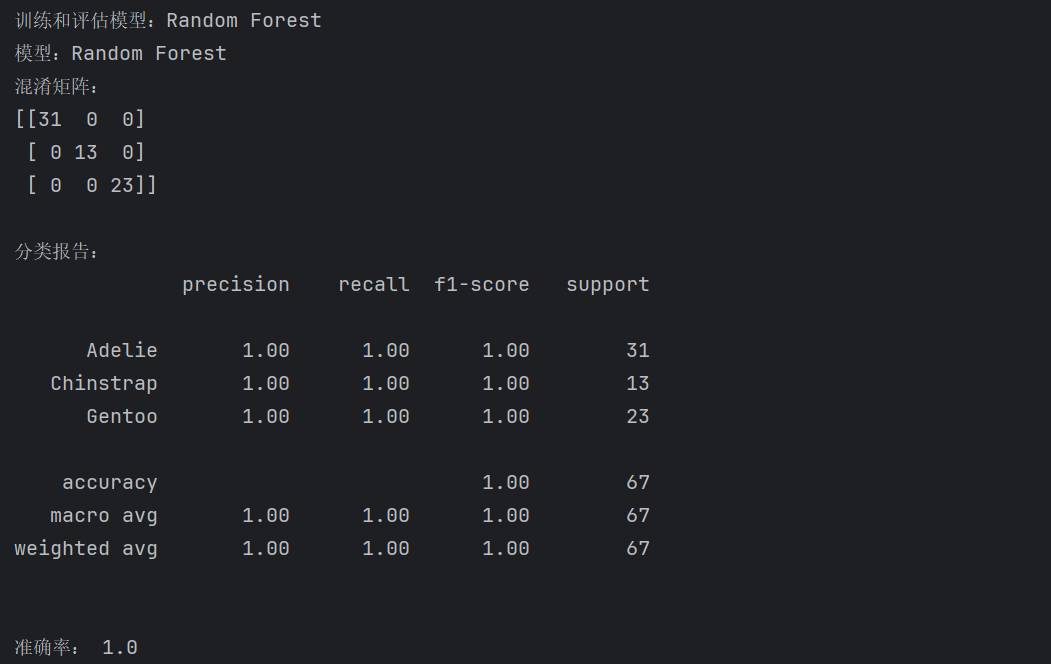
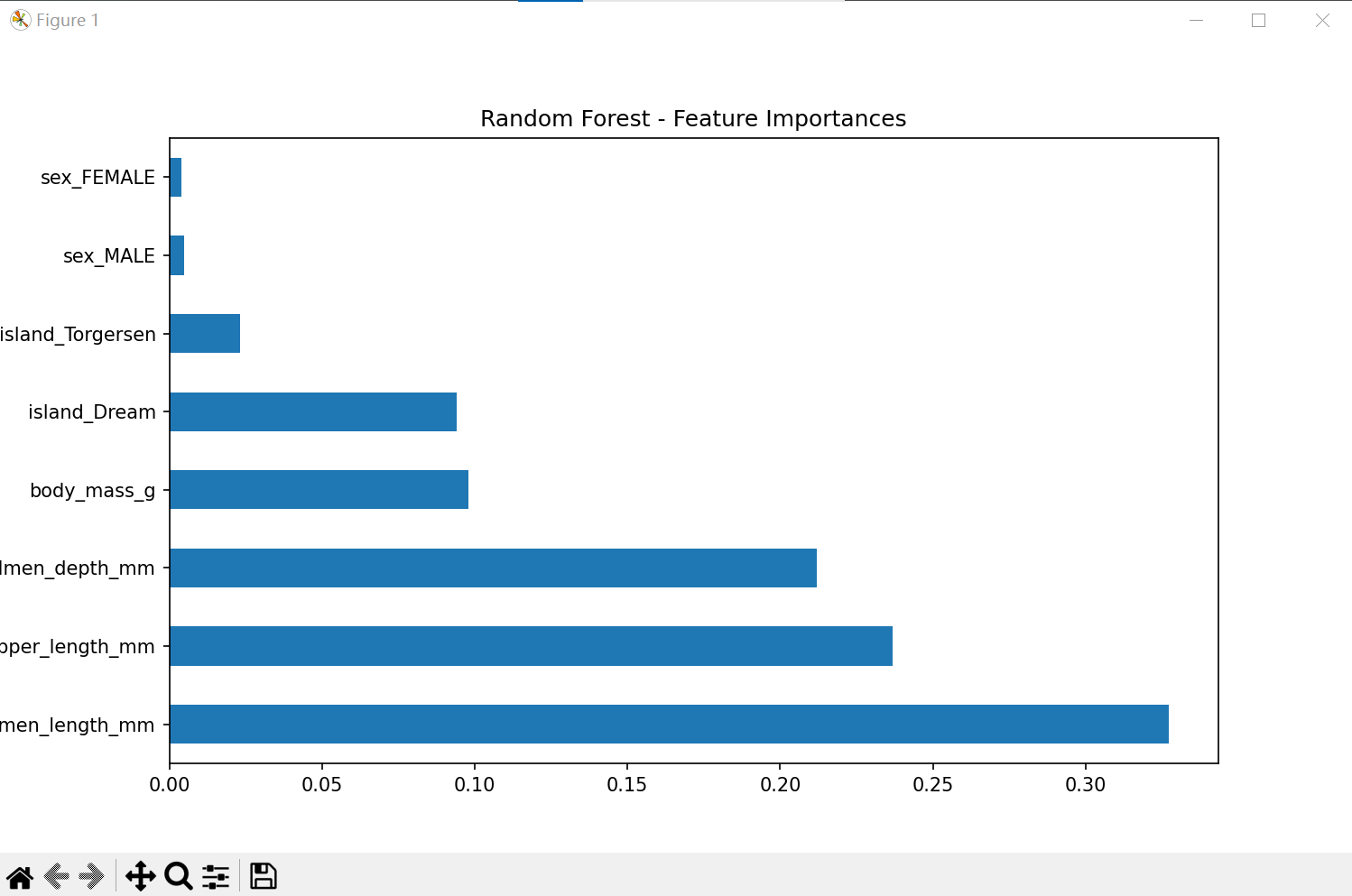
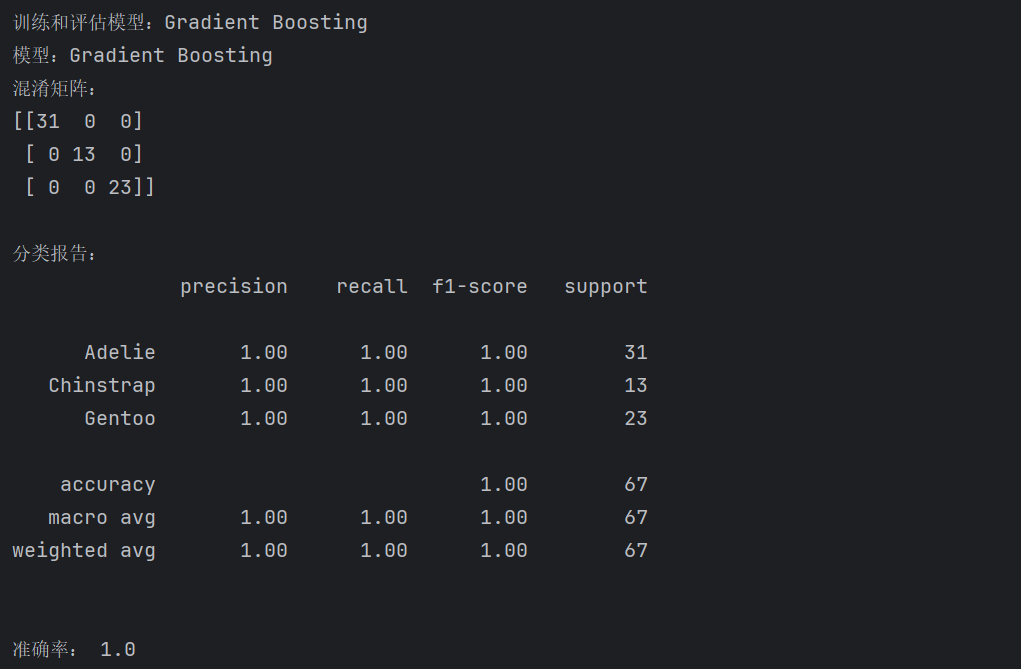
(2) 梯度提升(Gradient Boosting)分析结果及特征重要性
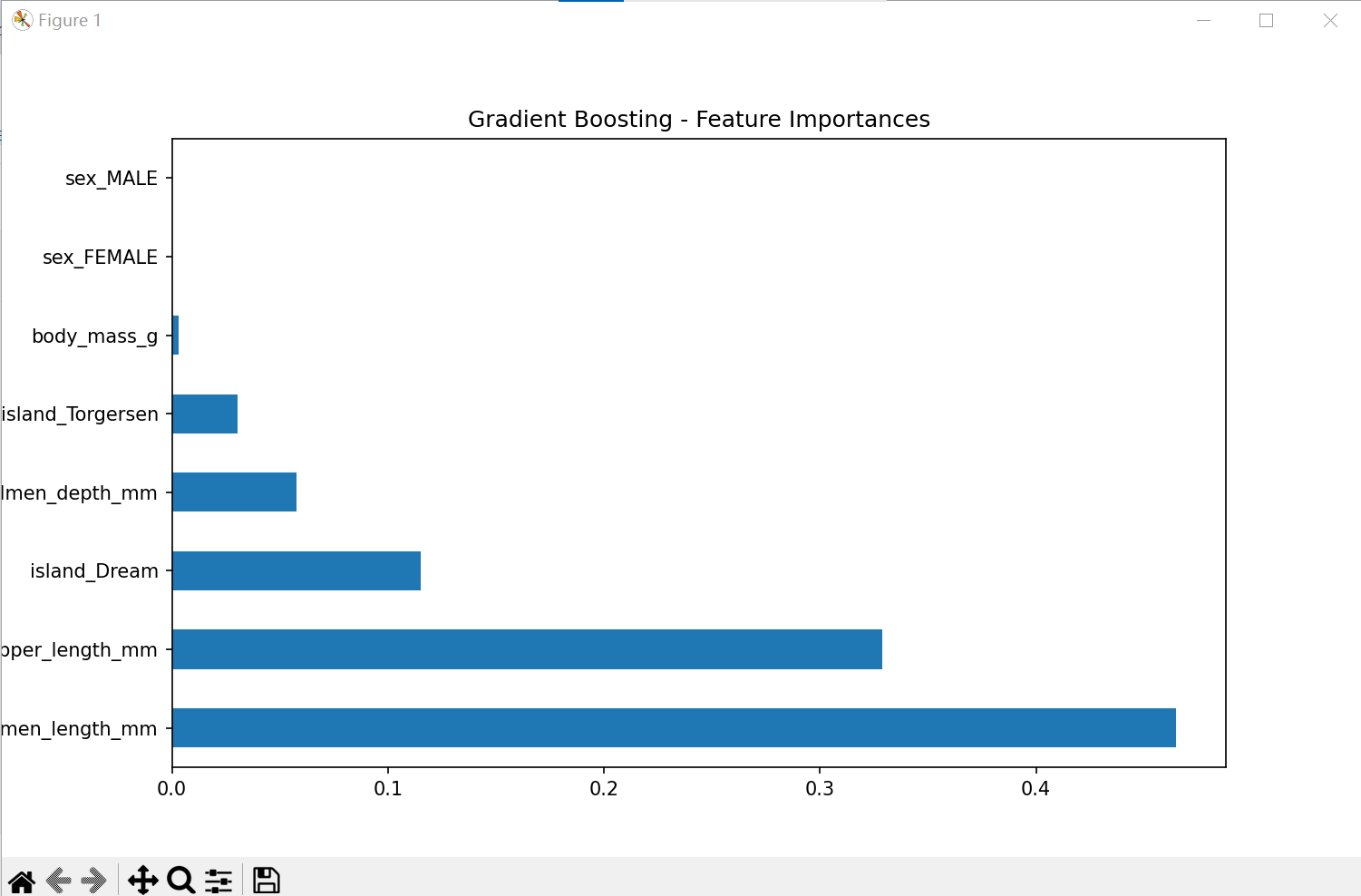
(3) 逻辑回归(Logistic Regression)的分析结果
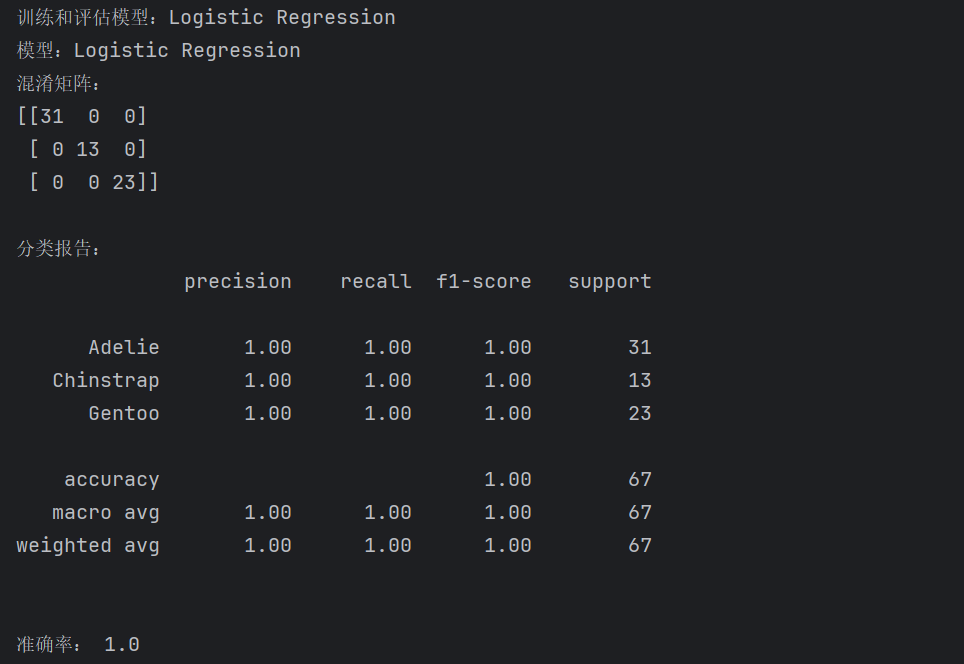
(4) 支持向量机(Support Vector)的分析结果
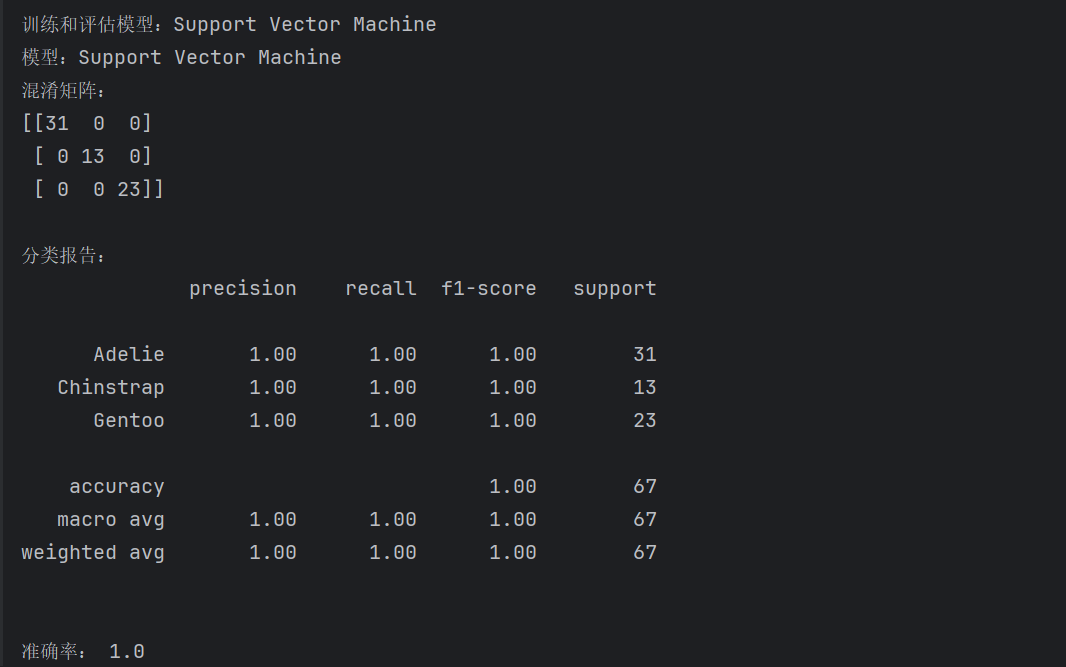
(5) K邻近(K-Nearest Neighbors)的分析结果
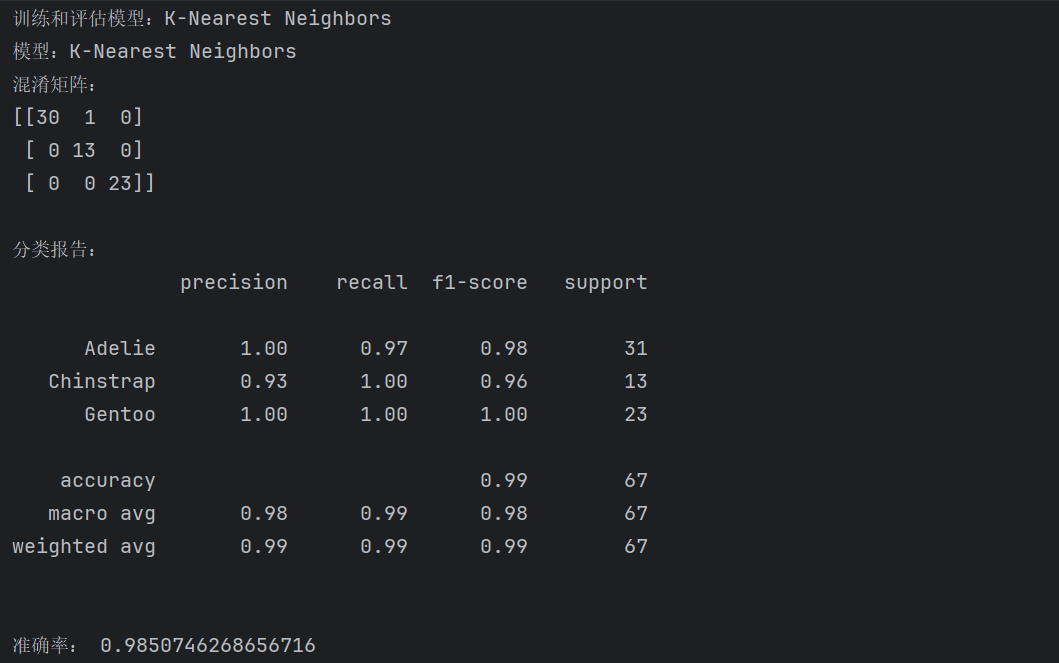
通过分析可知K邻近的准确率最低。

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









