







一、项目简介
共享单车是kaggle上最受欢迎的项目,这个项目利用了kaggle共享单车项目数据,将历史使用模式与天气数据相结合,预测华盛顿特区Capital Bikeshare计划中的自行车租赁需求情况。
本文参考了网上各种实现代码,使用sklearn机器学习库编码实现了三种分类器算法:常规集成学习,XGBoost,神经网络三大模型。
二、数据预处理与分析
我们从kaggle官网下载下来的数据包括三个文件:train.csv,test.csv和sample_submission.csv。其中train.csv是训练集数据,test.csv是测试集数据,sample_submission.csv是提交示例数据。
数据下载地址:Bike Sharing Demand | Kaggle

Kaggle所提供的数据描述如下:
| 列标题 | 含义 |
| datetime | 年/月/日/时间,例:2011/1/1 0:00 |
| season | 季节:1=春,2=夏,3=秋天,4=冬天 |
| holiday | 假日:是否是节假日(0=否,1=是) |
| workingday | 工作日:是否是工作日(0=否,1=是) |
| weather | 天气:1=晴天、多云等(良好),2=阴天薄雾等(普通),3=小雪、小雨等(稍 差),4=大雨、冰雹等(极差) |
| temp | 实际温度(℃) |
| atemp | 感觉温度(℃) |
| humidity | 湿度 |
| windspeed | 风速 |
| casual | 未注册用户租借数量 |
| registered | 注册用户租借数量 |
| count | 总租借数量 |
根据官方数据描述,特征为前9项,分别为日期时间(1)、季节(2)、工作日/节假日(3-4)、天气(5-9)四类;标签为后3项:注册/未注册用户租借数量以及租借总数。因为官方规定的提交文件中要求预测的只有租借总数,因此本项目中只关注租借总数的预测。
第一步:导入数据并初探
print(train_data.shape,test_data.shape)
print(train_data.info())#查看具体字段信息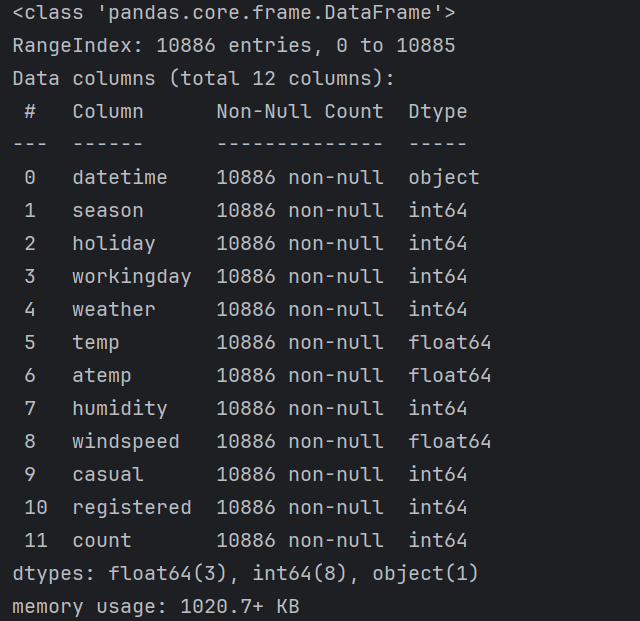
print(train_data.head())#查看头几行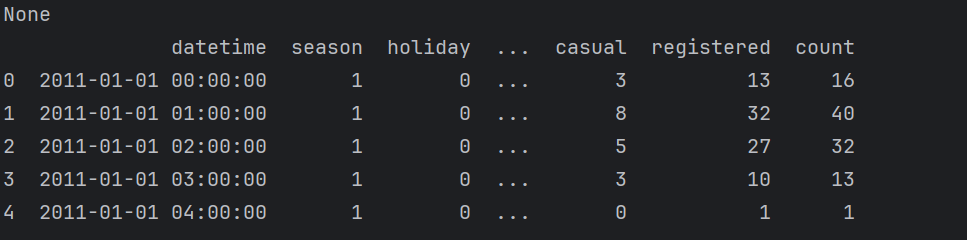
从结果可知,训练数据共12列,10886行;测试数据共9列,6493行,且所有数据完整,没有缺失。相比于训练数据,测试数据缺少注册/未注册用户租借数量以及租借总数3个标签,需要我们通过建模进行预测。
第二步:数据预处理
# 合并两种数据,使其共同进行数据规范化
# 使用 pd.concat 合并
data = pd.concat([train_data, test_data], ignore_index=True)
# 打印合并后的数据和形状
print(data.shape)
# 拆分年、月、日、时
data['year'] = data.datetime.apply(lambda x: x.split()[0].split('-')[0])
data['year'] = data['year'].apply(lambda x: int(x))
data['month'] = data.datetime.apply(lambda x: x.split()[0].split('-')[1])
data['month'] = data['month'].apply(lambda x: int(x))
data['day'] = data.datetime.apply(lambda x: x.split()[0].split('-')[2])
data['day'] = data['day'].apply(lambda x: int(x))
data['hour'] = data.datetime.apply(lambda x: x.split()[1].split(':')[0])
data['hour'] = data['hour'].apply(lambda x: int(x))
data['date'] = data.datetime.apply(lambda x: x.split()[0])
data['weekday'] = pd.to_datetime(data['date']).dt.day_name()
data['weekday'] = data['weekday'].map({'Monday': 1, 'Tuesday': 2, 'Wednesday': 3, 'Thursday': 4, 'Friday': 5, 'Saturday': 6, 'Sunday': 7})
data = data.drop('datetime', axis=1)
# 重新安排整体数据特征
# 定义列名集合
cols = {'year', 'month', 'day', 'weekday', 'hour', 'season', 'holiday', 'workingday',
'weather', 'temp', 'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count'}
# 将集合转换为列表
cols = list(cols)
# 使用 loc 选择指定的列
data = data.loc[:, cols]
# 分离测试数据和训练数据
train = data.iloc[:10886] # 前 10886 行作为训练数据
test = data.iloc[10886:] # 剩余的行作为测试数据为了方便特征转换,合并训练集与测试集,通过查看数据,训练和测试数据均无缺失、不一致和非法等问题。日期时间特征由年、月、日和具体小时组成,还可以根据日期计算其星期,因此可以将日期时间拆分成年、月、日、时和星期5个特征。
第三步:数据分析及可视化
1、快速查看各影响因素对租借数的影响:
#1、计算相关系数,并快速查看
correlation = train.corr()
influence_order = correlation['count'].sort_values(ascending=False)
influence_order_abs = abs(correlation['count']).sort_values(ascending=False)
print(influence_order)
print(influence_order_abs)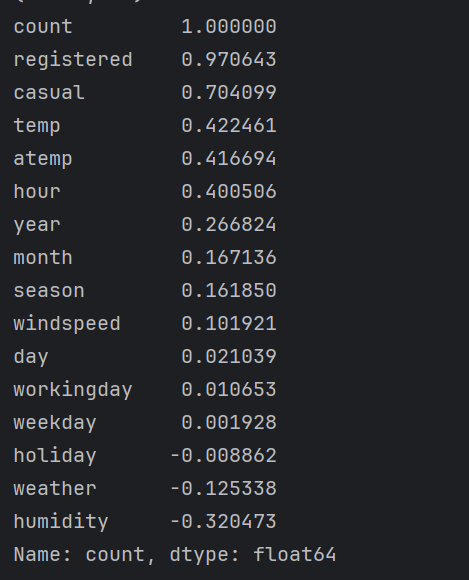
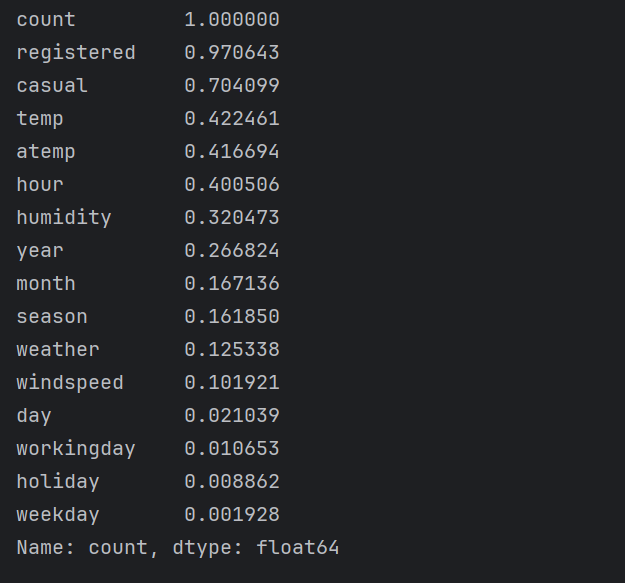
从相关系数可以看出,天气(包括温度、湿度)对租借数存在明显影响,其中temp和atemp的意义及其与count的相关系数十分接近,因此可以只取atemp作为温度特征。此外,year、month、season等时间因素对count也存在明显影响,而holiday和weekday与count的相关系数极小。
2、为了更加直观地展现所有特征之间的影响,作相关系数热力图:
f,ax =plt.subplots(figsize=(16,16))
cmap = sn.cubehelix_palette(light=1,as_cmap=True)
sn.heatmap(correlation,annot=True,center=1,cmap=cmap,linewidths=1,ax=ax)
sn.heatmap(correlation,vmax=1,square=True,annot=True,linewidths=1)
plt.show()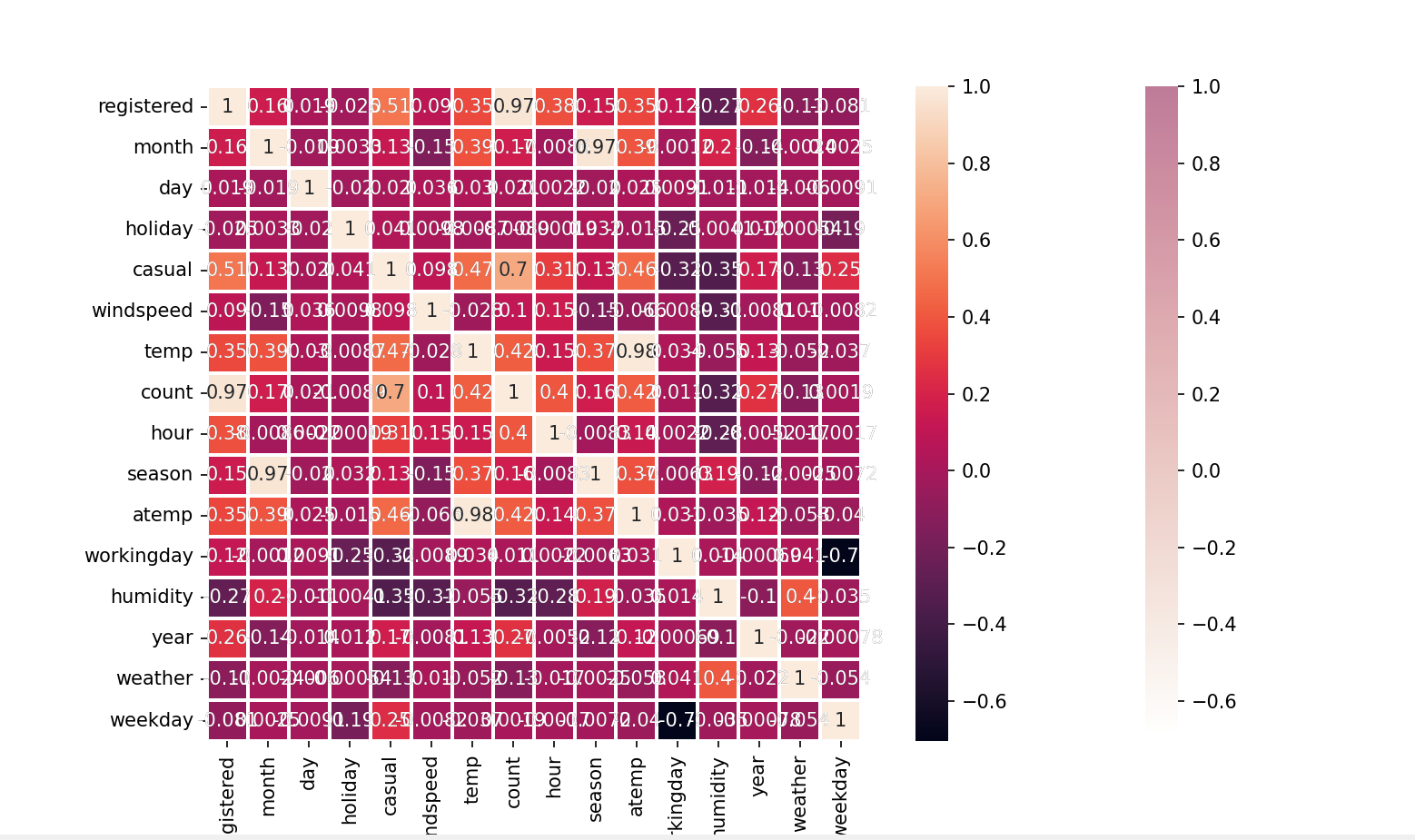
3、每个特征对租借量的影响
(1)年份对租借数的影响
#年份对租借的影响
sn.boxplot(x='year', y='count', data=train, legend=False, palette='viridis')
plt.title('The influence of year')
plt.show()
2012年的租借数明显比2011年高,说明随着时间的推移,共享单车逐渐被更多的人熟悉和认可,使用者越来越多。
(2) 月份对租借数的影响
#月份对租借的影响
sn.pointplot(x='month', y='count', data=train)
plt.title('The influence of month')
plt.show()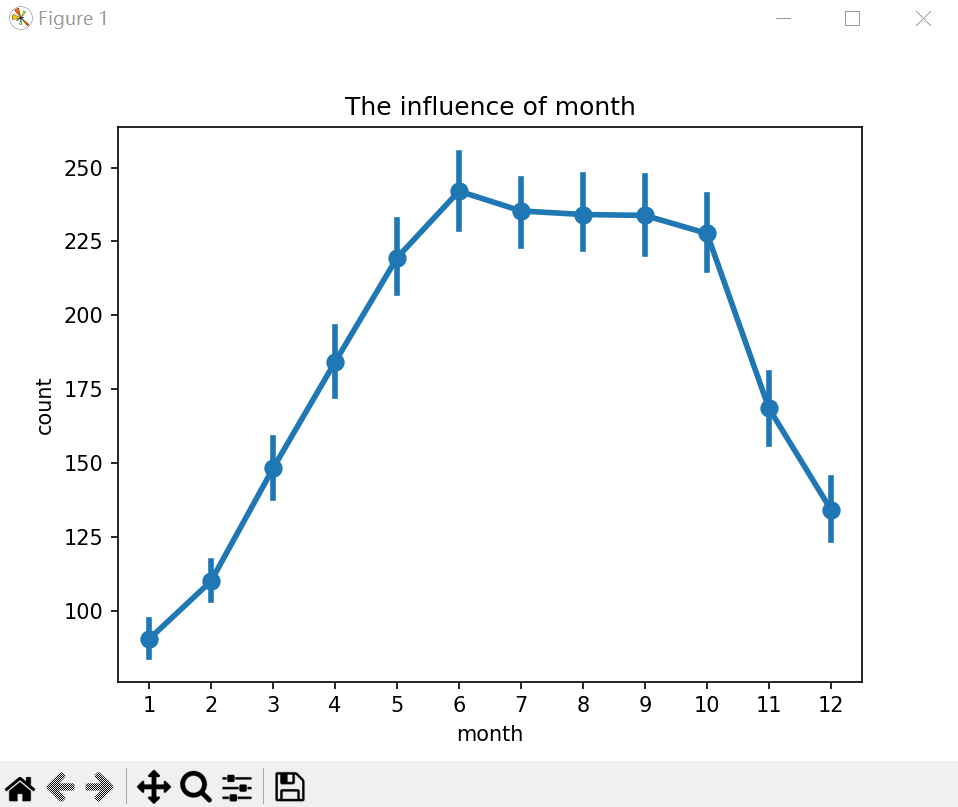
月份对租借数影响显著,从1月份开始每月的租借数快速增加,到6月份达到顶峰,随后至10月缓慢降低,10月后急剧减少。这明显与季节有关。
(3) 季节对租借数的影响
#季节对租借的影响
sn.boxplot(x='season', y='count', data=train, legend=False, palette='viridis')
plt.title('The influence of season')
plt.show()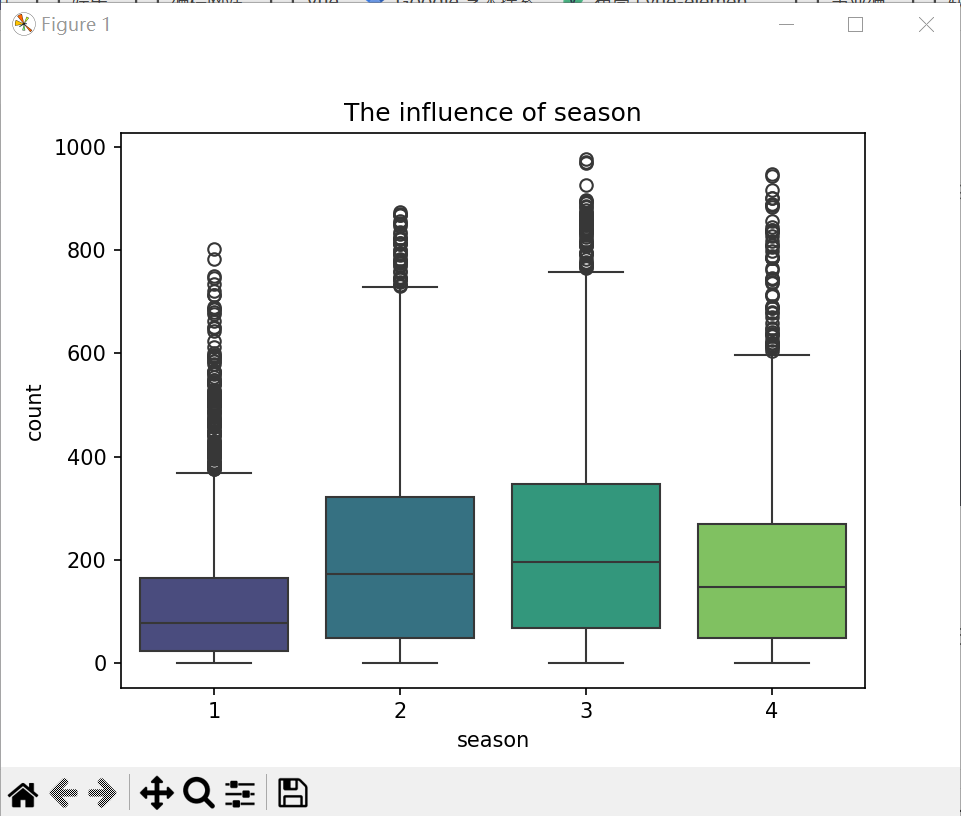
通过各季度箱型图可以看出季节对租借数的影响符合预期:春季天气仍然寒冷,骑车人少;随着天气转暖,骑车人逐渐增多,并在秋季(天气最适宜时)达到顶峰;随后进入冬季,天气变冷,骑车人减少。因为月份和季节对租借数的影响重合,且月份更加详细,因此在随后的建模过程中选取月份特征,删除季节特征。
(4) 时间(小时)对租借数的影响
#时间(一小时)对租借的影响
sn.barplot(x='hour', y='count', data=train, legend=False, palette='viridis')
plt.title('The influence of hour')
plt.show()
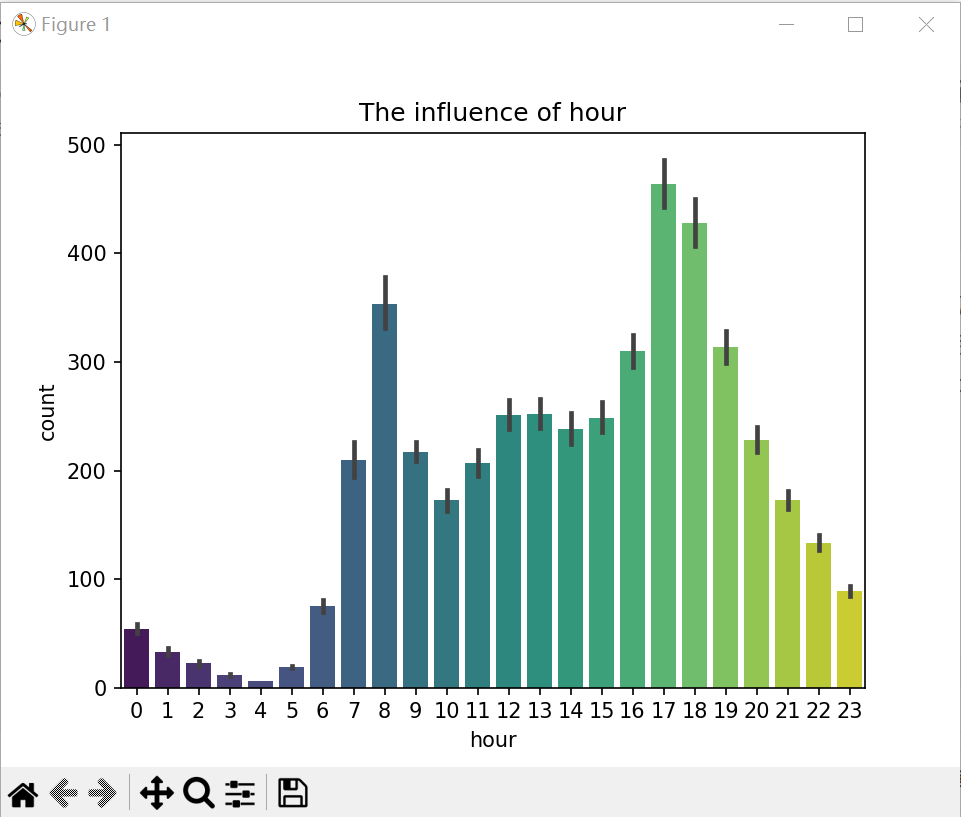
从时间的分布上来看,每天有两个高峰期,分别是早上8点左右和下午17点左右,正好是工作日的上下班高峰期。而介于两者之间的白天时间变化规律不明显,可能与节假日有关,因此以此为基础需要考虑节假日和星期的影响。
# 创建一个 3x1 的子图布局
fig, axes = plt.subplots(3, 1, figsize=(12, 8))
# 第一个子图:按工作日分类
sn.pointplot(x='hour', y='count', hue='weekday', data=train, ax=axes[0], palette='tab10')
axes[0].set_title('The influence of hour (weekday)')
# 第二个子图:按工作日分类
sn.pointplot(x='hour', y='count', hue='workingday', data=train, ax=axes[1], palette='Set2')
axes[1].set_title('The influence of hour (workingday)')
# 第三个子图:按假期分类
sn.pointplot(x='hour', y='count', hue='holiday', data=train, ax=axes[2], palette='Set2')
axes[2].set_title('The influence of hour (holiday)')
# 调整布局
plt.tight_layout()
plt.show()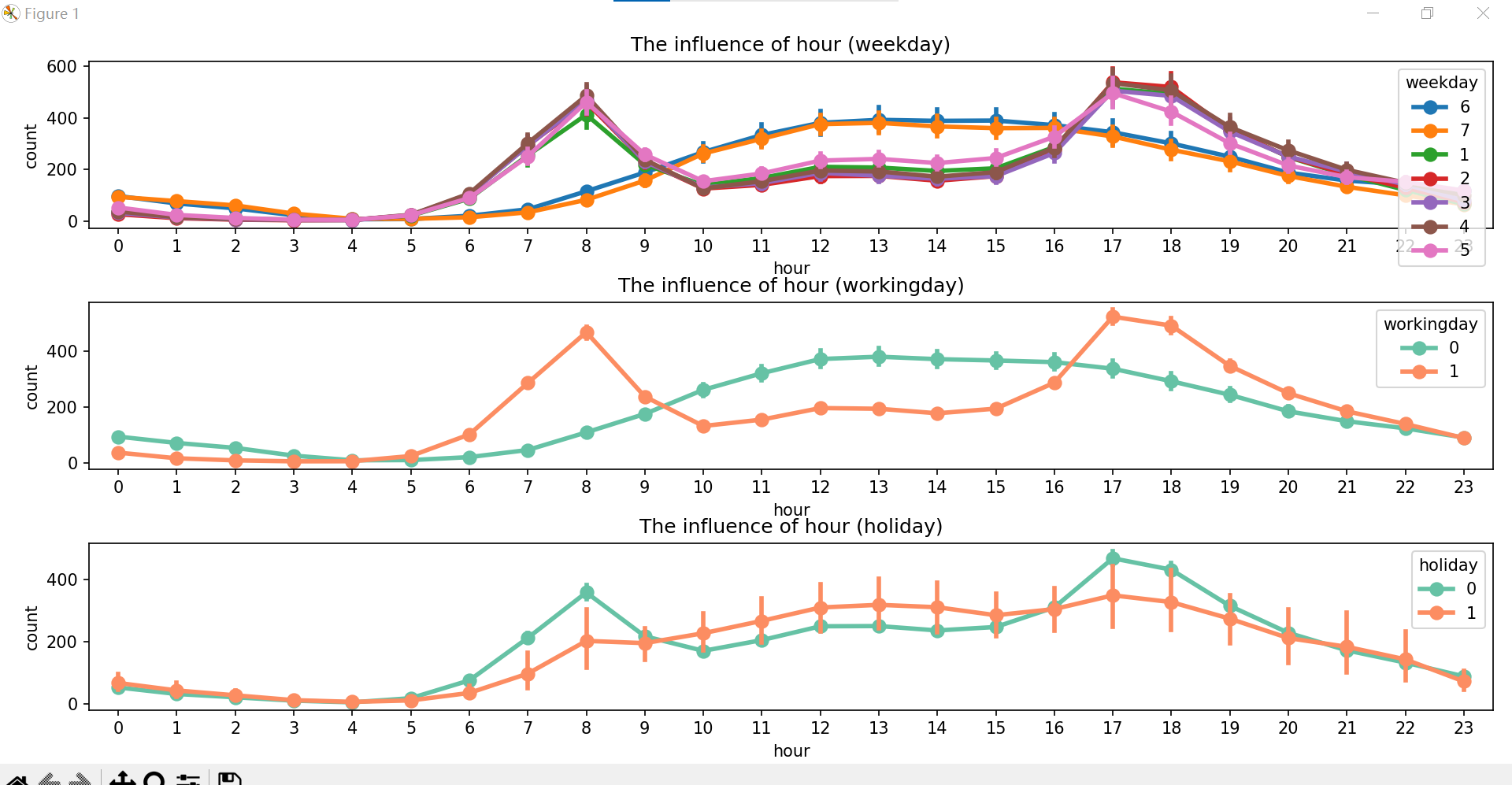
可以看出,工作日早晚上班高峰期租借量高,其余时间租借量低;节假日中午及午后租借量较高,符合节假日人们出行用车的规律。
(5)天气对租借数的影响
#天气对租借的影响
sn.boxplot(x='weather', y='count', data=train, legend=False, palette='viridis')
plt.title('The influence of weather')
plt.show()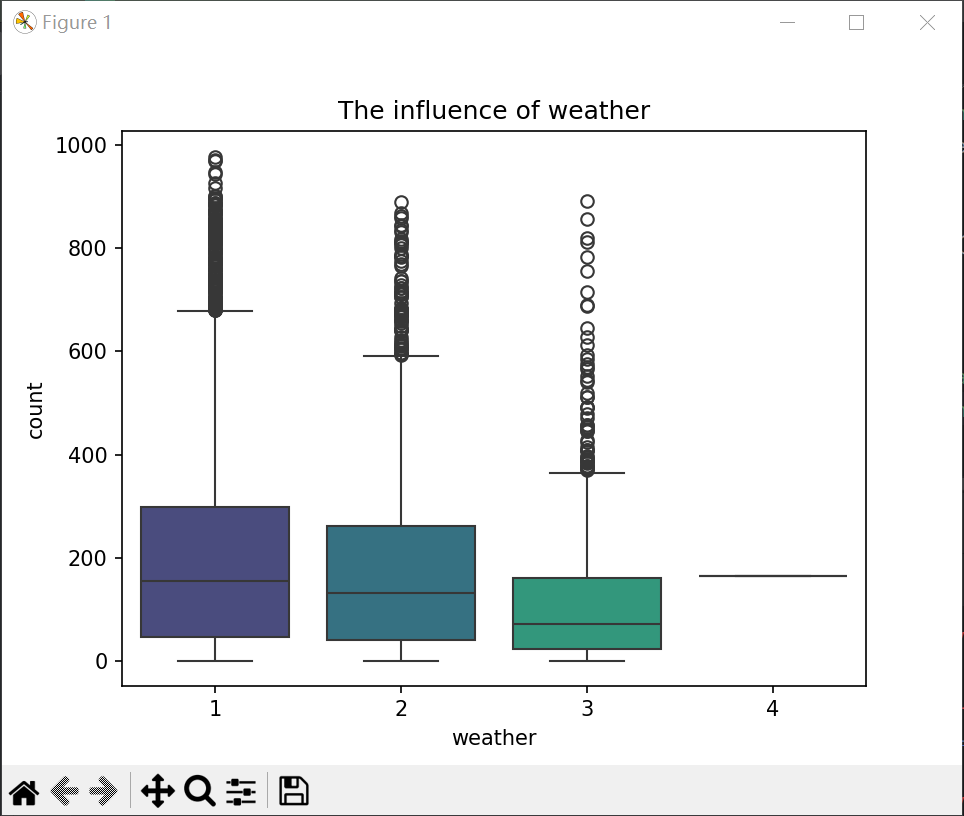
(6)温度、湿度和风速对租借量的影响
# 温度、湿度和风速对租借量的影响
cols = ['temp','atemp','humidity','windspeed','count']
sn.pairplot(train[cols])
plt.show()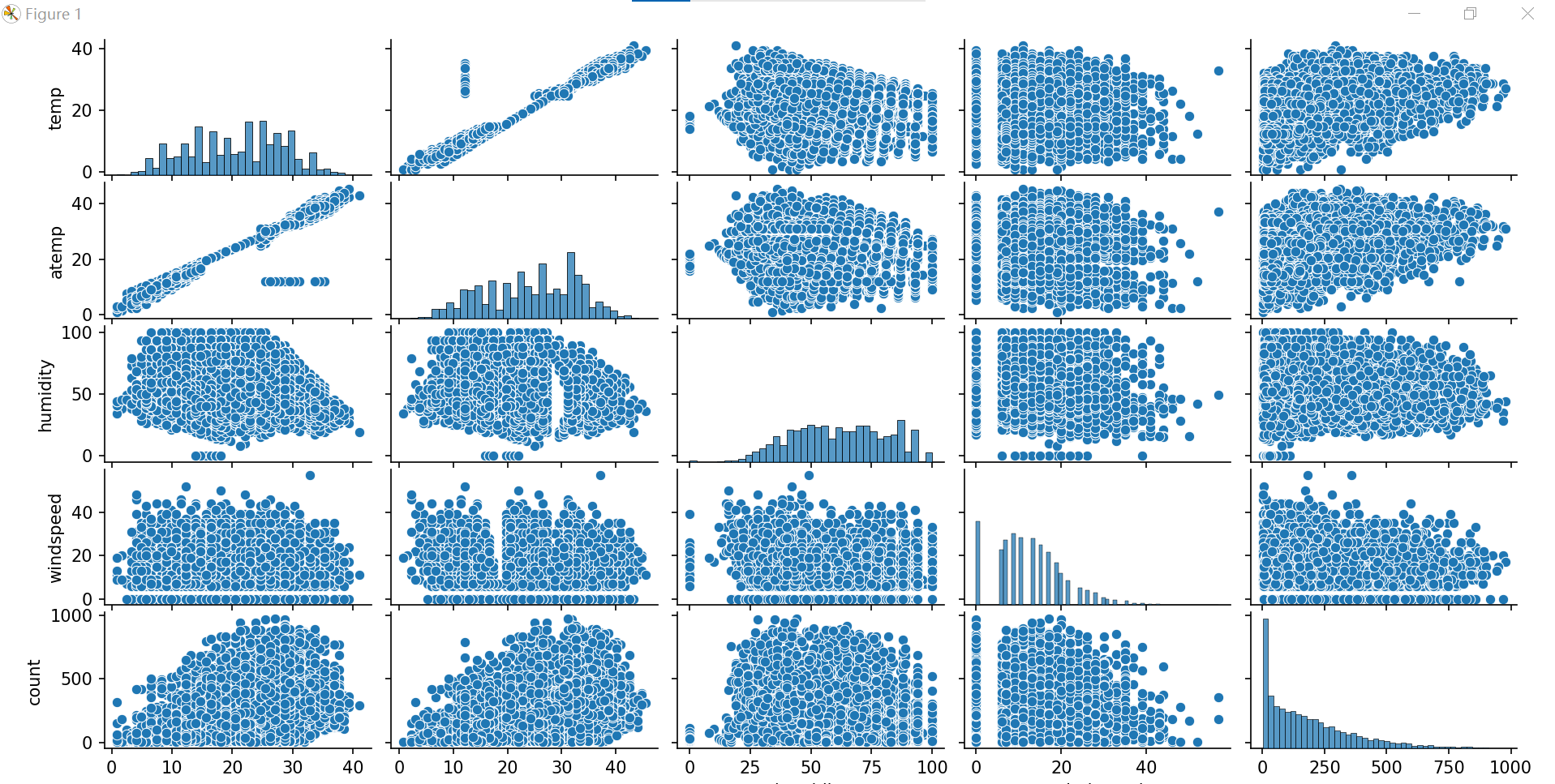
作出多个连续变量之间的相关图,可以比较任意两个连续变量之间的关系。图中可以明显看出temp和atemp大致成线性关系,但也存在一组数据显著偏离线性相关趋势,可能与湿度和风速有关。因此,可以认为temp、humidity和windspeed三者共同决定了atemp,因此在后续建模过程中可以删除atemp特征。
进一步研究温度、湿度和风速对租借数的影响
#进一步研究温度、湿度和风速对租借数的影响
# 创建一个 1x3 的子图布局
fig, axes = plt.subplots(1, 3, figsize=(24, 8))
# 在第一个子图中绘制温度对租借数的影响
sn.regplot(x='temp', y='count', data=train, ax=axes[0],color='orange')
axes[0].set_title('The influence of temperature')
# 在第二个子图中绘制湿度对租借数的影响
sn.regplot(x='humidity', y='count', data=train, ax=axes[1],color='pink')
axes[1].set_title('The influence of humidity')
# 在第三个子图中绘制风速对租借数的影响
sn.regplot(x='windspeed', y='count', data=train, ax=axes[2],color='green')
axes[2].set_title('The influence of windspeed')
plt.show()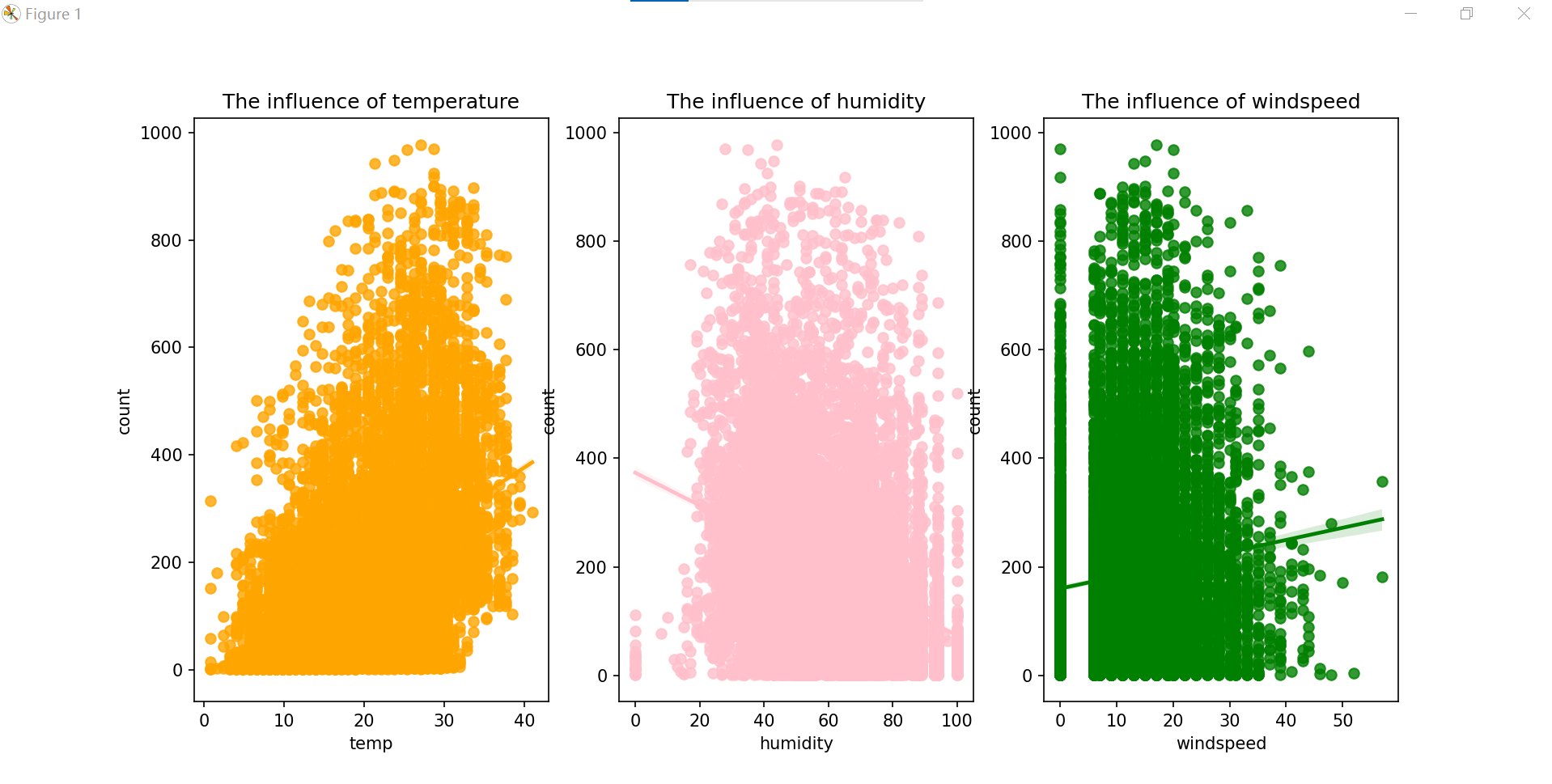
虽然三种天气因素对租借数的影响比较分散,但可以明显看出温度和风速与租借数成正相关,湿度与租借数成负相关
第四步:特征工程
#所选取的特征year,mouth,workingday,holiday,workingday,holiday,weather,temp,humidity,windspeed
#(1) 删除不要变量
data = data.drop(['day','weekday','season','atemp','casual','registered'],axis=1)
#(2)离散型变量转换
column_trans = ['year','month','hour','weather']
data = pd.get_dummies(data,columns=column_trans)
# 保存处理后的训练数据到 CSV 文件
train.to_csv('C:\\03WorkDisk\\02Code\\MachineLearning\\SharedBicycles\\data\\train_processed.csv', index=False)
# 保存处理后的测试数据到 CSV 文件
test.to_csv('C:\\03WorkDisk\\02Code\\MachineLearning\\SharedBicycles\\data\\test_processed.csv', index=False)综上所述,本项目提取特征year、month、hour、workingday、holiday、weather、temp、humidity和windspeed共9个特征预测租借总数。其中year、month、hour、workingday、holiday和weather为离散量,且由于workingday和holiday已经是二元属性,因此其余四个需要进行独热编码(one-hot)方式进行转换。
第五步:构建模型
分别采用三种典型集成学习模型(普通随机森林、极端随机森林模型和梯度提升树模型)、XGBoost模型和人工神经网络模型。此处均采用模型的默认参数或简单参数,如人工神经网络选用三层神经网络,每层包含神经元数量相同,且均为特征个数。
# 特征选择
col_trans = [
'holiday', 'workingday', 'temp', 'humidity', 'windspeed',
'year_2011', 'year_2012', 'month_1', 'month_2', 'month_3', 'month_4',
'month_5', 'month_6', 'month_7', 'month_8', 'month_9', 'month_10',
'month_11', 'month_12', 'hour_0', 'hour_1', 'hour_2', 'hour_3',
'hour_4', 'hour_5', 'hour_6', 'hour_7', 'hour_8', 'hour_9', 'hour_10',
'hour_11', 'hour_12', 'hour_13', 'hour_14', 'hour_15', 'hour_16',
'hour_17', 'hour_18', 'hour_19', 'hour_20', 'hour_21', 'hour_22',
'hour_23', 'weather_1', 'weather_2', 'weather_3', 'weather_4'
]
X_train = data[col_trans].iloc[:10886]
X_test = data[col_trans].iloc[10886:]
y_train = data['count'].iloc[:10886]
# 分割训练数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.25, random_state=40)# 建模预测,分别采用常规集成学习方法、XGBoost和神经网络三大类模型
# (1)集成学习方法——普通随机森林
rf = RandomForestRegressor()
rf.fit(x_train, y_train)
rf_y_predict = rf.predict(x_test)
print("集成学习方法——普通随机森林回归模型的R方得分为:", r2_score(y_test, rf_y_predict))# (2)极端随机树模型
etr = ExtraTreesRegressor()
etr.fit(x_train, y_train)
etr_y_predict = etr.predict(x_test)
print("极端随机树回归模型的R方得分为:", r2_score(y_test, etr_y_predict))# (3)梯度提升树模型
gbr = GradientBoostingRegressor()
gbr.fit(x_train, y_train)
gbr_y_predict = gbr.predict(x_test)
print("梯度提升树回归模型的R方得分为:", r2_score(y_test, gbr_y_predict))三个模型预测结果如下:

保存三者数据:
# 创建提交文件
# 假设 test_data 包含 datetime 列,并且它是第一列
submission_rf = pd.DataFrame({'datetime': test_data['datetime'], 'count': rf.predict(X_test)})
submission_etr = pd.DataFrame({'datetime': test_data['datetime'], 'count': etr.predict(X_test)})
submission_gbr = pd.DataFrame({'datetime': test_data['datetime'], 'count': gbr.predict(X_test)})
# 保存为 CSV 文件
submission_rf.to_csv(r'C:\03WorkDisk\02Code\MachineLearning\SharedBicycles\data\submission_rf.csv', index=False)
submission_etr.to_csv(r'C:\03WorkDisk\02Code\MachineLearning\SharedBicycles\data\submission_etr.csv', index=False)
submission_gbr.to_csv(r'C:\03WorkDisk\02Code\MachineLearning\SharedBicycles\data\submission_gbr.csv', index=False)在Kaggle上运行的结果如下:
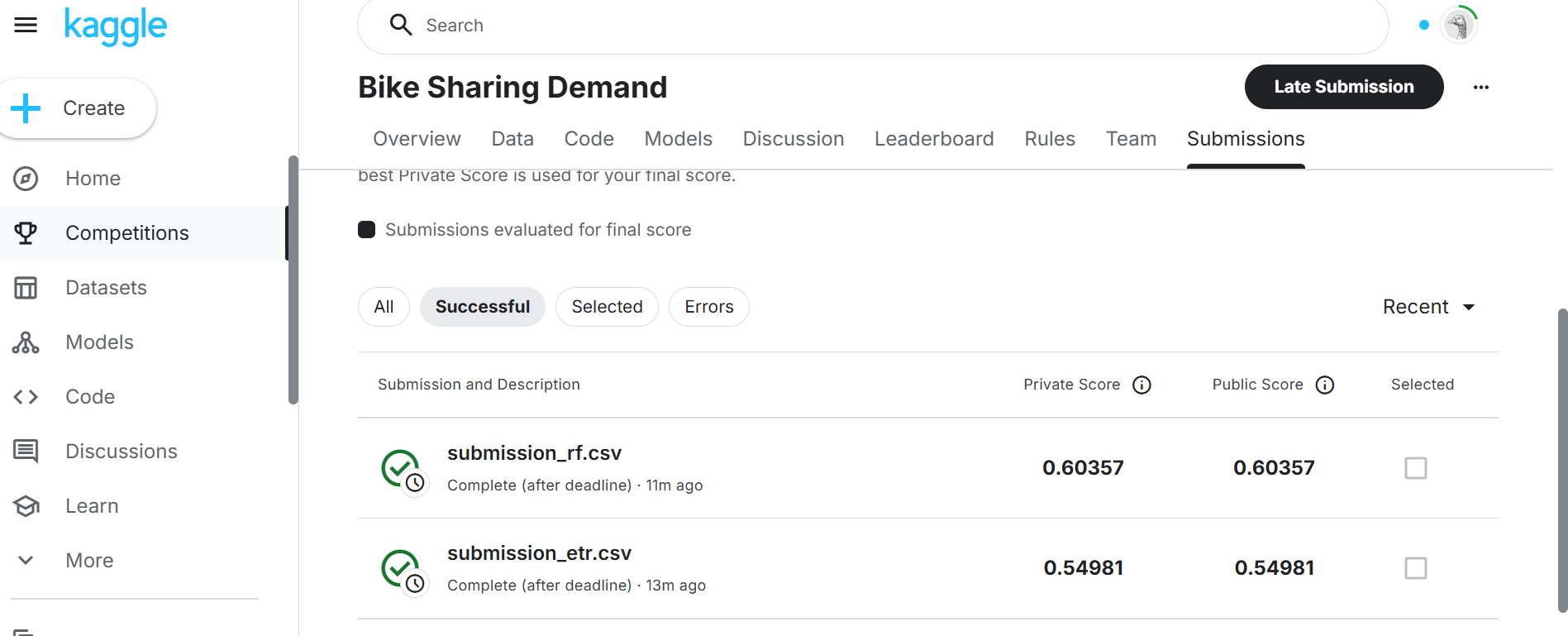
梯度提升树模型因为值为负数值未提交成功

















 2457
2457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









