






ByteBuffer
字节缓冲区 NIO下的类
ByteBuffer的父类是Buffer类,意思为缓冲区类,ByteBuffer为字节缓冲区,当然他也可以处理int, long, char等基本数据类型。
相比于Buffer类的其他继承类CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer 和 ShortBuffer,ByteBuffer类应用更广泛。
其实现类如下:

| 实现类 | 描述 | 优点 |
| — | — | — |
| HeapByteBuffer | 在jvm堆上面的一个buffer,底层的本质是一个数组 | 由于内容维护在jvm里,所以把内容写进buffer里速度会快些;并且,可以更容易回收 |
| DirectByteBuffer | 底层的数据其实是维护在操作系统的内存中,而不是jvm里,DirectByteBuffer里维护了一个引用address指向了数据,从而操作数据 | 跟外设(IO设备)打交道时会快很多,因为外设读取jvm堆里的数据时,不是直接读取的,而是把jvm里的数据读到一个内存块里,再在这个块里读取的,如果使用DirectByteBuffer,则可以省去这一步,实现zero copy |
ByteBuffer的属性及方法
ByteBuffer的属性
-
byte[] buff 缓存数组 //buff即内部用于缓存的数组。
-
capacity 容量 //初始化时候的容量。
-
limit 限制 缓冲区的临界区,即最多可读到哪个位置
-
当写数据到buffer中时,limit一般和capacity相等。
-
当读数据时,limit代表buffer中有效数据的长度。
-
int position = 0位置 //当前读取的位置。 -
int mark = -1标记 //一个临时存放的位置下标,为某一读过的位置做标记,便于某些时候回退到该位置。 -
调用mark()会将mark设为当前的position的值,以后调用reset()会将position属性设置为mark的值。
-
mark的值总是小于等于position的值,如果将position的值设的比mark小,当前的mark值会被抛弃掉。
这些属性总是满足以下条件:
0 <= mark <= position <= limit <= capacity
ByteBuffer的常用方法
-
ByteBuffer allocate(int capacity) //创建一个指定容量capacity的ByteBuffer。
-
ByteBuffer allocateDirect(int capacity) //创建一个direct的ByteBuffer,这样的ByteBuffer在参与IO操作时性能会更好
-
ByteBuffer wrap(byte [] array)// 把一个byte数组包装成ByteBuffer。
-
ByteBuffer wrap(byte [] array, int offset, int length) //把一个byte数组或byte数组的一部分包装成ByteBuffer。
-
Buffer clear() 把position设为0,把limit设为capacity,一般在把数据写入Buffer前调用。
-
Buffer flip() 把limit设为当前position,把position设为0,一般在从Buffer读出数据前调用。
-
Buffer rewind() 把position设为0,limit不变,一般在把数据重写入Buffer前调用。
-
compact() 将 position 与 limit之间的数据复制到buffer的开始位置,复制后 position = limit -position,limit = capacity, 但如果position 与limit 之间没有数据的话发,就不会进行复制。
-
mark() & reset() 通过调用Buffer.mark()方法,可以标记Buffer中的一个特定position。之后可以通过调用Buffer.reset()方法恢复到这个position。
-
int remaining() 剩余可读元素,limit - position
-
boolean isReadOnly() 是否是只可读缓冲区
-
boolean isDirect() 是否是堆外内存
-
//get put
-
byte get(int index)
-
ByteBuffer put(byte b)
-
int getInt() //从ByteBuffer中读出一个int值。
-
ByteBuffer putInt(int value) // 写入一个int值到ByteBuffer中。
-
xxx
端点排序
endian 字节存放次序
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
-
LITTLE-ENDIAN(小字节序、低字节序),即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
-
与之对应的是:BIG-ENDIAN(大字节序、高字节序)
不同语言、场景下的字节序
JAVA默认是Big-Endian 大端点序
TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序
代码示例
大端点序
ByteBuffer byteBuffer = ByteBuffer.allocate(4);
byteBuffer.order(ByteOrder.BIG_ENDIAN);
byteBuffer.putInt(88);
byte[] result = byteBuffer.array();
System.out.println(Arrays.toString(result));
打印[0,0,0,88]
小端点序
ByteBuffer byteBuffer = ByteBuffer.allocate(4);
byteBuffer.order(ByteOrder.LITTLE_ENDIAN);
byteBuffer.putInt(88);
byte[] result = byteBuffer.array();
System.out.println(Arrays.toString(result));
打印[88,0,0,0]
读数据
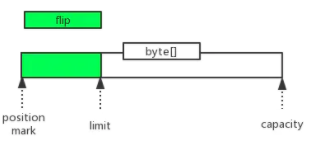
flip
开始读的时候,将postion复位到0,并将limit设为当前postion。(即写转读的时候用到)
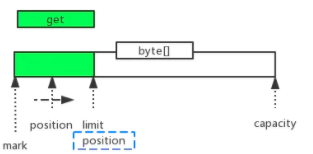
get
从buffer里读一个字节,并把postion移动一位。上限是limit,即写入数据的最后位置。
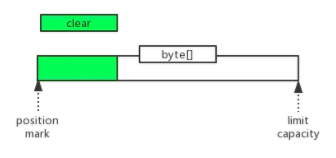
clear
将limit设置为容量大小,将position置为0,并不清除buffer内容。
写数据
put
写模式下,往buffer里写一个字节,并把postion移动一位。写模式下,一般limit与capacity相等。

实例
以Mysql空间数据类型 Geometry 来实操一波
Geometry 实际存储格式为:长度为25个字节
- 4个字节用于整数SRID(0)
写在最后
作为一名即将求职的程序员,面对一个可能跟近些年非常不同的 2019 年,你的就业机会和风口会出现在哪里?在这种新环境下,工作应该选择大厂还是小公司?已有几年工作经验的老兵,又应该如何保持和提升自身竞争力,转被动为主动?
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!

Java经典面试问题(含答案解析)

阿里巴巴技术笔试心得

,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!**
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!
[外链图片转存中…(img-D1c5SkaN-1719250629528)]
Java经典面试问题(含答案解析)
[外链图片转存中…(img-4c7wNnP7-1719250629529)]
阿里巴巴技术笔试心得
[外链图片转存中…(img-MxA6zwW4-1719250629530)]















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









