







随着LLM基座的不断成熟和生态的不断完善,越来越多的企业开始在自身业务场景的应用探索,以实现降本增效。然而,在这一过程中,企业不得不面对两种AI应用形态的选择:
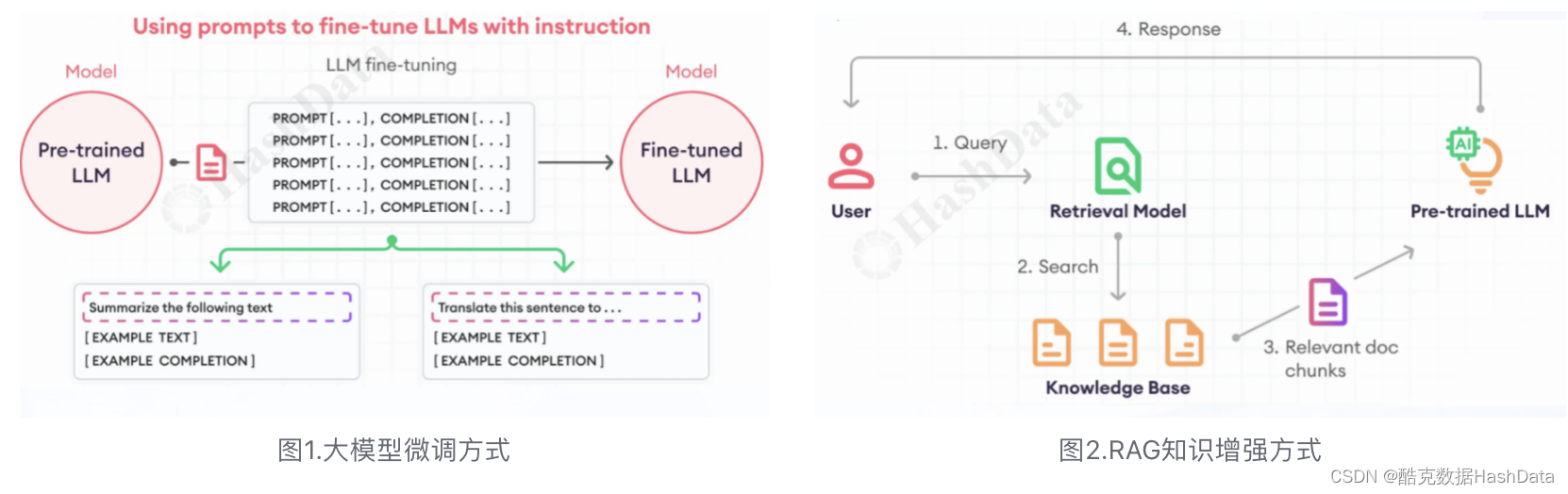
- 一种应用方式是基于大模型微调。这种方式需要将预先训练好的基座大模型,结合场景语料进行微调,从而获得具备行业知识的垂类模型应用。微调过程是精细而复杂的工作,不仅需要在保证语料质量的基础上进行梳理编排,而且还需要定期针对更新的语料重新进行模型微调训练。只有这样,微调后模型才会有更好的性能和泛化能力,从而提供更加准确和高效的推理结果。
- 另一种应用方式是通过RAG(检索增强生成)方式,在大模型基础上建立行业知识库。这种方式可以弥补大模型在特定行业知识方面的不足。知识库的建设同样需要精心准备和规范化的管理,确保知识的正确性和规范性。只有这样,大模型进行检索时才能获得准确、相关的知识提示,从而引导大模型生成更符合需求的答案。
无论是基于微调还是RAG方式的AI应用,企业都需要建立完善的语料数据管理系统,为大模型微调训练提供高质量的语料输入,为RAG提供高质量知识库支持。由此,催生了企业对非结构化多模态语料数据管理的迫切诉求。
非结构化数据管理流程及技术挑战
然而,非结构化多模态语料数据不仅类型多样,而且体量巨大,给传统的数据处理方式带来了前所未有的挑战。
非结构化多模态语料数据管理流程大致可以分为以下5大流程:
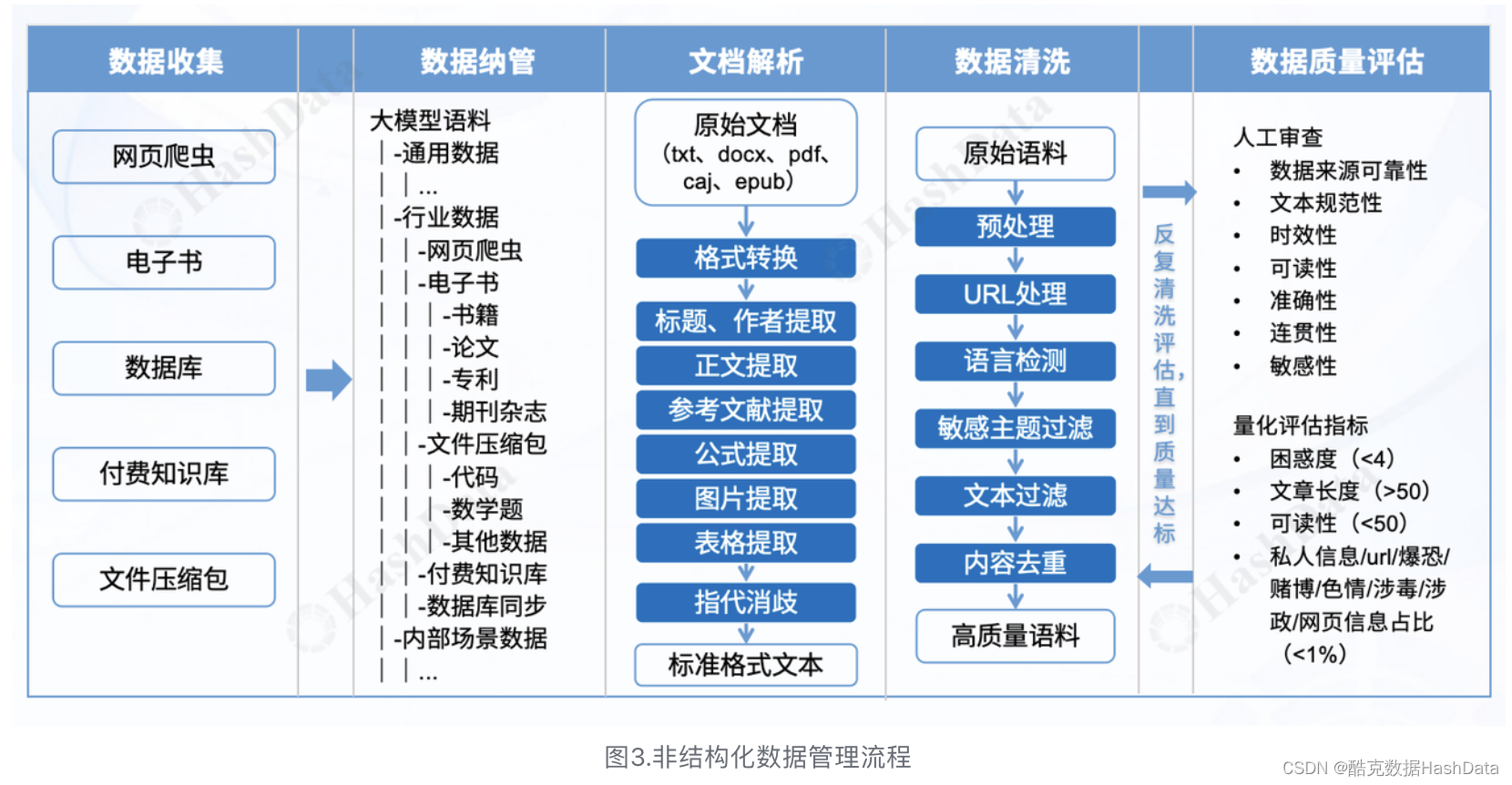
- 数据收集:这是整个流程的起点,涉及从各种来源获取数据。这些数据可能来自网络、第三方电子书库、企业内部数据库、外部购买的知识库、同行业分享的文件等。这些数据格式各异,包括文本、图像、音频、视频等。
- 数据纳管:收集到的数据需要被统一管理,并建立一个清晰的资产目录,以确保数据的可访问性和可维护性。随着模型训练的不断迭代,语料数据会不断增加,因此需要一个统一的维度来管理这些数据,以确保其质量和精选性。
- 文档解析:对收集到的文档进行解析,提取出关键信息,这些信息将被整合成一个标准格式的文档,便于后续处理和分析。
- 数据清洗:清洗过程旨在去除原始语料中的噪声和无关信息,包括去重、处理空格、非法字符、URL替换、语言类型检测以及敏感数据的过滤等,以确保数据的唯一性和准确性。
- 数据质量评估:在将清洗后的语料用于模型训练之前,需要对其进行质量评估。这可以从人工审查和量化评估指标两个维度进行。只有当数据在各个指标上表现良好时,才能被用于模型训练。
在整个管理流程中可以看出,非结构化多模态数据涵盖了各种格式和类型,如文本、图像、音频、视频等等,而且要处理的数据体量庞大,处理过程也十分复杂。企业已有的数据仓库或大数据平台在处理如此大规模的复杂数据时显得力不从心,独立建设又会带来不小的采购与维护
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









