






执行器是数据库最重要的模块之一,作为连接查询计划和存储引擎的桥梁,负责从存储引擎读取数据,并基于查询计划树执行对应的算子,得到最终的查询结果。在PostgreSQL技术内幕系列(十六)的直播中,光城老师为大家介绍了PG执行器基本原理和实现机制,并演示了如何从0到1写一个执行器算子。以下内容根据直播文字整理而成。
01执行器的处理模型
执行器的处理模型主要分为两大类:基于拉操作的Pull模型和基于推操作的Push模型。
Pull模型
Pull模型,也被称为火山模型,是一种高效且灵活的数据处理机制。在Pull模型中,上游节点通过“拉取”操作(即主动请求)来驱动下游节点的数据处理,这种机制特别适用于处理如join查询等复杂的数据操作。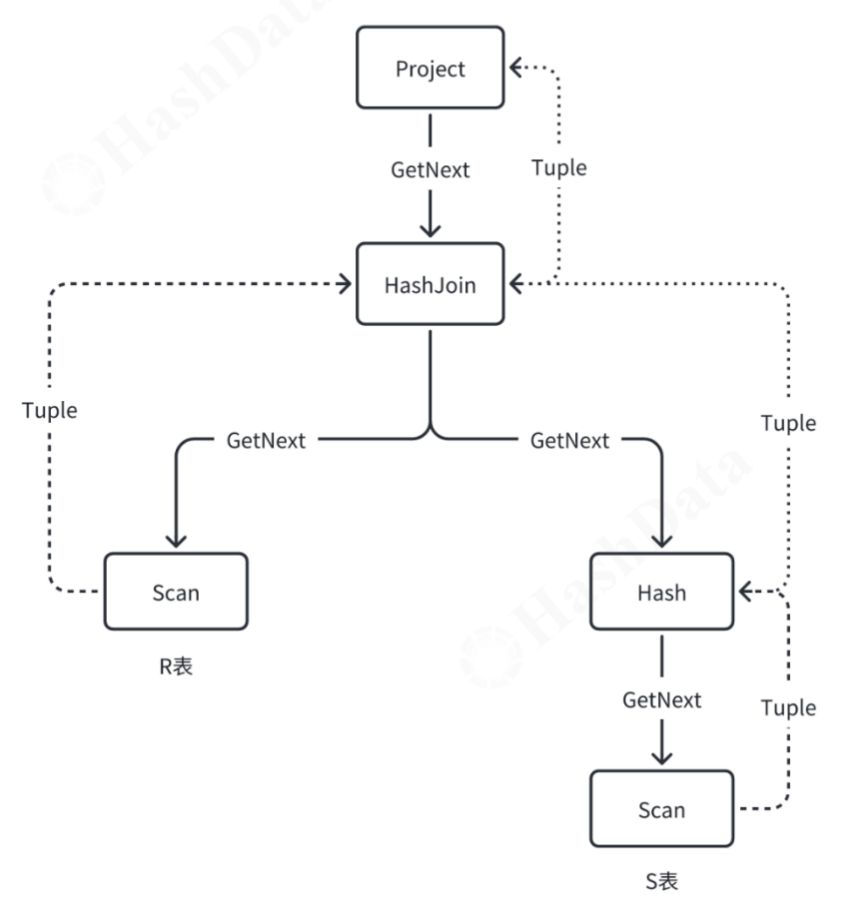 以图1所示查询为例,数据流从查询的顶层开始,逐层向下传递至各个处理节点。当上游节点需要数据时,它会发起GetNext操作来从下游节点“拉取”数据,并将处理后的结果返回给上游。这种逐层向下拉取数据的方式赋予了Pull模型极大的灵活性和高效性。由于数据是按照实际需求被拉取的,因此可以避免不必要的数据传输和处理,从而节省系统资源。同时,这种机制也使得查询执行过程更加可控,能够精确地满足用户的查询需求。如果将这种模型比作火山喷发,那么数据的流动就像是从火山顶部开始,逐层向下流动,并在需要时从底部喷发到顶部。因此,Pull模型有时也被称为火山模型。优点:
以图1所示查询为例,数据流从查询的顶层开始,逐层向下传递至各个处理节点。当上游节点需要数据时,它会发起GetNext操作来从下游节点“拉取”数据,并将处理后的结果返回给上游。这种逐层向下拉取数据的方式赋予了Pull模型极大的灵活性和高效性。由于数据是按照实际需求被拉取的,因此可以避免不必要的数据传输和处理,从而节省系统资源。同时,这种机制也使得查询执行过程更加可控,能够精确地满足用户的查询需求。如果将这种模型比作火山喷发,那么数据的流动就像是从火山顶部开始,逐层向下流动,并在需要时从底部喷发到顶部。因此,Pull模型有时也被称为火山模型。优点:
- 通用性强:Pull模型不受数据及规模的限制,可以处理任意规模的数据集。
- 灵活性高:Pull模型可以灵活控制输出的数量,比如Limit算子及时短路。
缺点:
- 阻塞节点:对于排序节点,需要首先读取下层节点所有数据,并根据数据量选择合适的排序算法。
- 函数调用开销:在数据流动过程中,每条元组在节点之间都会涉及大量的函数调用。
- 缓存不友好:过多的控制语句和函数调用容易导致缓存失效。
- 并行处理受限:在并行处理场景下,其性能可能受到一定限制。
push模型
Push模型采用了一种自底向上的数据处理方式,从最底层的节点起始,持续生成数据,并逐级将数据推送给上层节点。其核心理念在于基于物化的操作流程:每个节点会处理所有输入的数据,将这些数据处理并物化后,再传递给上一层节点。 优点:
优点:
- 并行处理能力强:Push模型非常适合并行处理,各节点可以独立运作,提高了整体处理效率。
- 减少函数调用和缓存切换:与Pull模型相比,Push模型显著减少了函数调用次数和缓存切换的频率,从而降低了这些操作带来的开销。
- 缓存使用率高:由于各节点内部处理逻辑的一致性,使得缓存的使用率得到显著提升。
缺点:
- 内存占用较大:由于每个节点都需要物化处理后的数据,这可能导致在处理大量数据时占用较多的内存资源。
向量化执行引擎
除了Pull模型和Push模型这两大经典模型之外,CloudberryDB在PostgreSQL基础上,引入了自研的向量化执行引擎,为执行器性能带来了革命性的提升。与传统的逐行处理方式不同,向量化执行引擎能够一次性处理一批数据,通过减少函数调用次数和缓存切换频率,显著提高查询的执行效率。同时,结合列式存储和SIMD指令,向量化执行引擎进一步放大了这种优势,使得执行器的性能可以得到显著提升。CloudberryDB开源数据库自研的向量化执行引擎将在未来适时开源,如果大家对此感兴趣,可以关注CloudberryDB公众号,获取最新产品资讯。
02执行器流程
上文提到了执行器是连接查询计划和存储层的关键环节。根据图3所示执行器流程,我们可以清晰地看到执行器与存储层是通过算子实现关联的。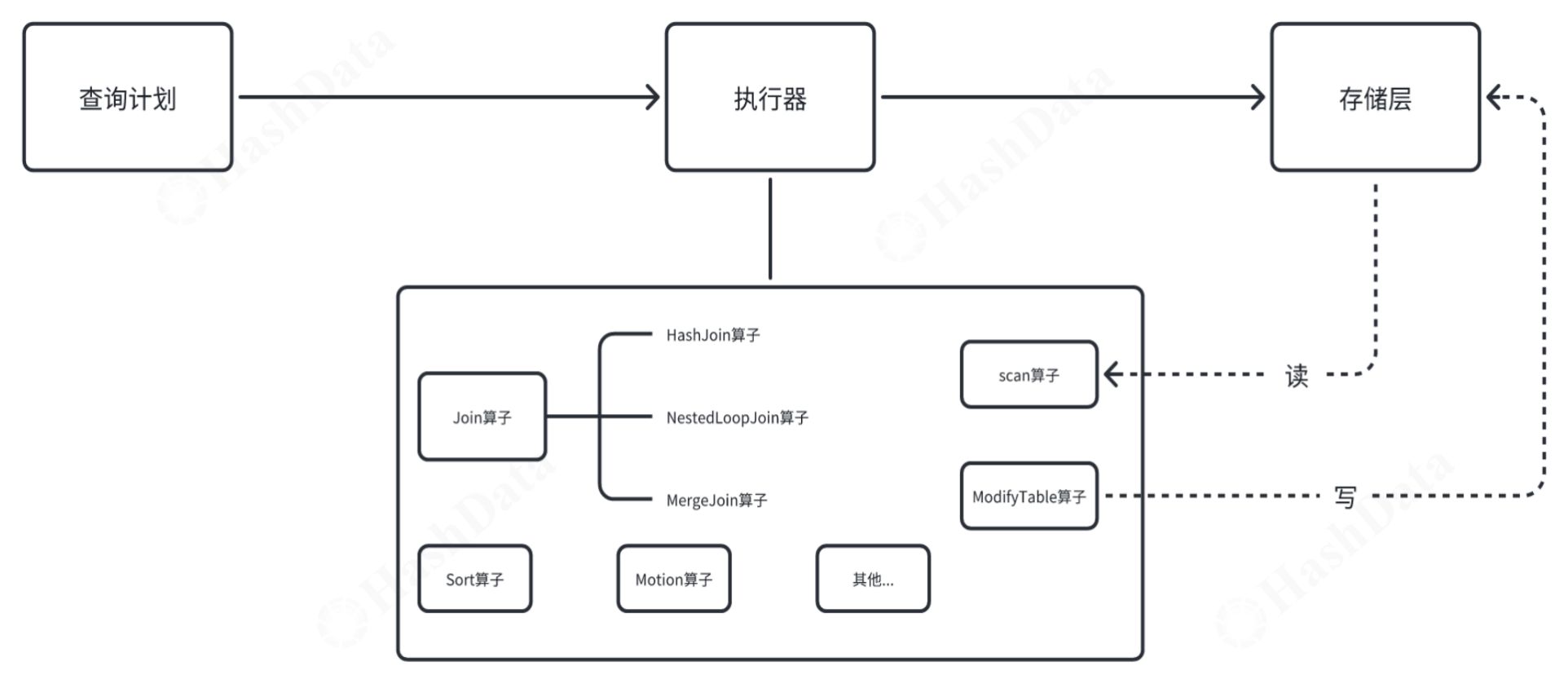 由此引出了以下三个关键问题:
由此引出了以下三个关键问题:
- 执行器与各个算子之间如何关联?
- 执行器与查询计划是如何关联的?
- 执行器又是如何与存储层建立联系的?
执行器与算子如何关联?
在数据库内核层面,执行器的操作流程可以概括为四个关键阶段,它们依次是:ExecutorStart、ExecutorRun、ExecutorFinish和ExecutorEnd。这四个阶段在执行器和算子之间建立了紧密的关联,并各自扮演着不同的角色。 PS:这里的执行器“四部曲”理念与外界常提的“三部曲”理念(即Start、Run、Finish)有所不同,我们在此特别强调了“Finish”这一阶段。此阶段在执行某些操作后进行必要的清理或总结,具有不可忽视的重要性。为确保内容的完整性,我们将对“Finish”阶段后续展开论述。
PS:这里的执行器“四部曲”理念与外界常提的“三部曲”理念(即Start、Run、Finish)有所不同,我们在此特别强调了“Finish”这一阶段。此阶段在执行某些操作后进行必要的清理或总结,具有不可忽视的重要性。为确保内容的完整性,我们将对“Finish”阶段后续展开论述。
ExecutorStart:
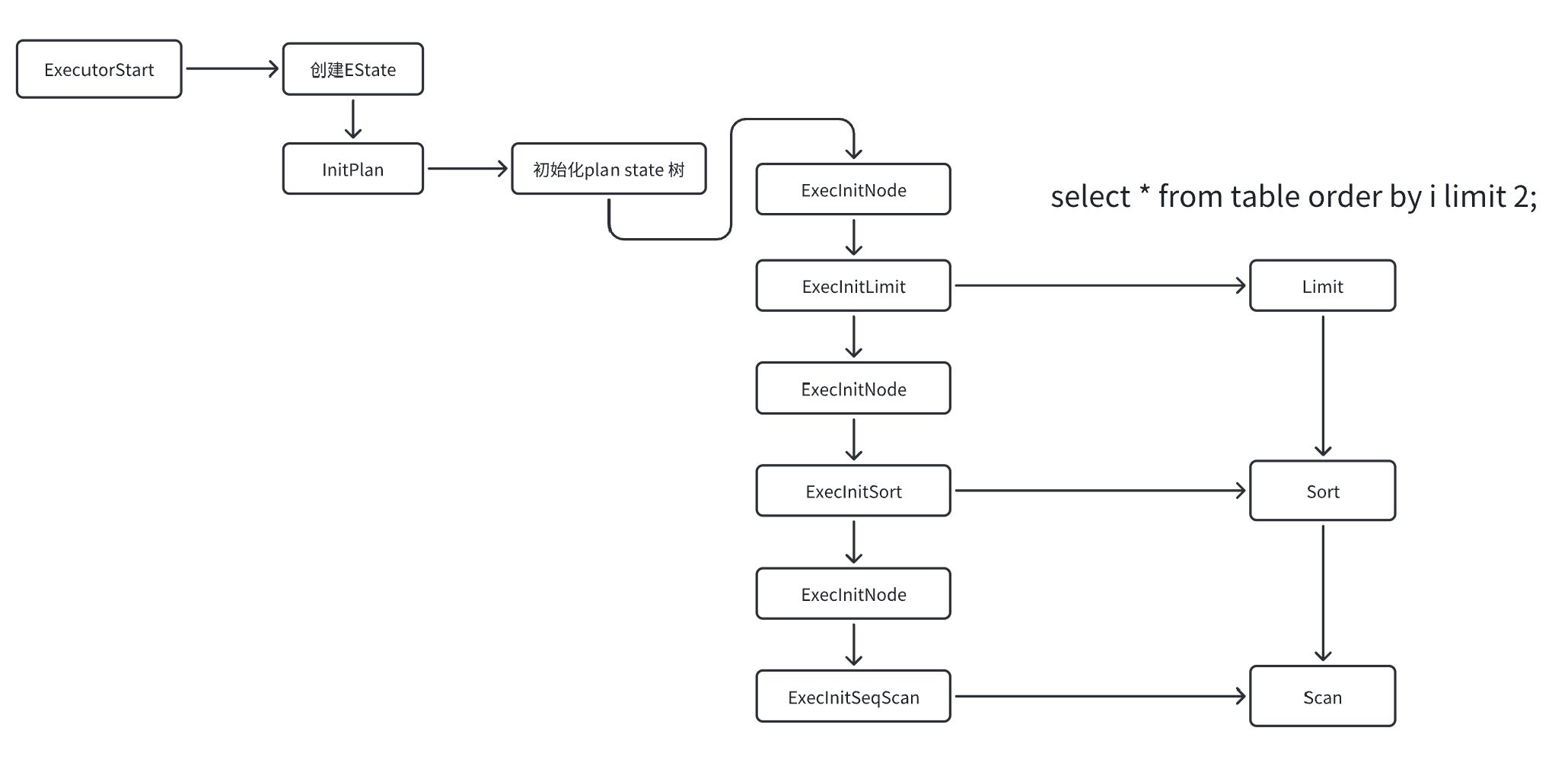 ExecutorStart主要负责初始化各个算子的状态。以SQL语句select * from table order by i limit 2;为例,ExecutorStart会首先创建一个包含所有执行所需信息的执行器状态(Estate)。随后,通过InitPlan来初始化Plan State树,为接下来的执行做好准备。在这个过程中,ExecInitNode函数发挥着关键作用,它根据节点的类型(如limit、sort或scan)进行相应的初始化操作。这个过程是层层递进的,确保每个节点或算子的信息和私有状态都被正确设置。
ExecutorStart主要负责初始化各个算子的状态。以SQL语句select * from table order by i limit 2;为例,ExecutorStart会首先创建一个包含所有执行所需信息的执行器状态(Estate)。随后,通过InitPlan来初始化Plan State树,为接下来的执行做好准备。在这个过程中,ExecInitNode函数发挥着关键作用,它根据节点的类型(如limit、sort或scan)进行相应的初始化操作。这个过程是层层递进的,确保每个节点或算子的信息和私有状态都被正确设置。
ExecutorRun:
初始化完成后,执行器进入运行阶段,通过ExecutorRun来实现算子的运行。此阶段类似于一个外循环,不断从下游获取数据,直到数据全部处理完毕。这个过程主要是通过调用不同的访问方法来执行的,每个访问方法都对应一个函数指针。在初始化阶段,这些函数指针已被设置好,并在运行阶段被调用。
ExecutorFinish:
为确保信息的完整性和后续分析的便利性,在ExecutorRun和ExecutorEnd之间,我们特别引入了ExecutorFinish阶段。在ExecutorFinish阶段,执行器会进行一些统计信息的收集、时间的记录以及相关的清理工作。
ExecutorEnd:
执行器ExecutorEnd阶段,负责逐层结束下游节点的执行。这个过程是通过调用每个节点的结束函数(endplan)来实现的,该函数会识别到具体的节点类型,并调用相应的结束方法。在结束过程中,执行器会销毁每个节点的状态信息,释放资源。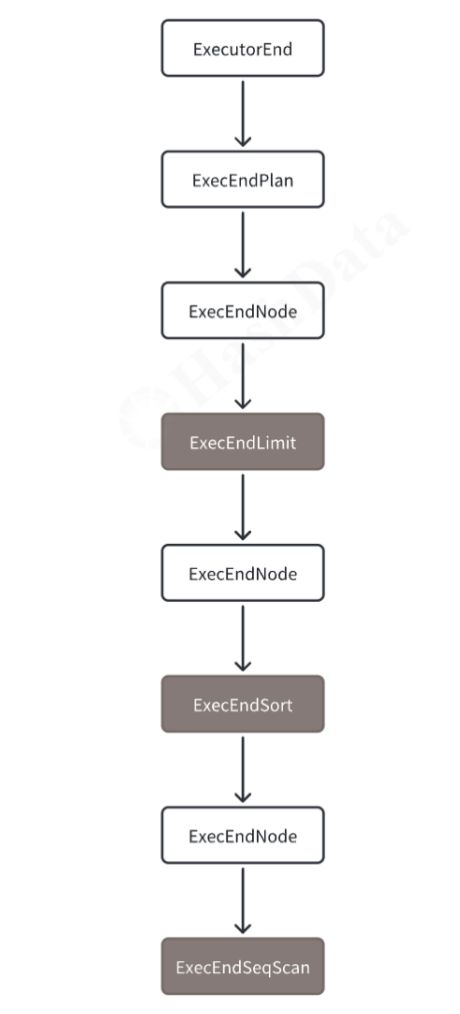
查询计划与执行器如何关联?
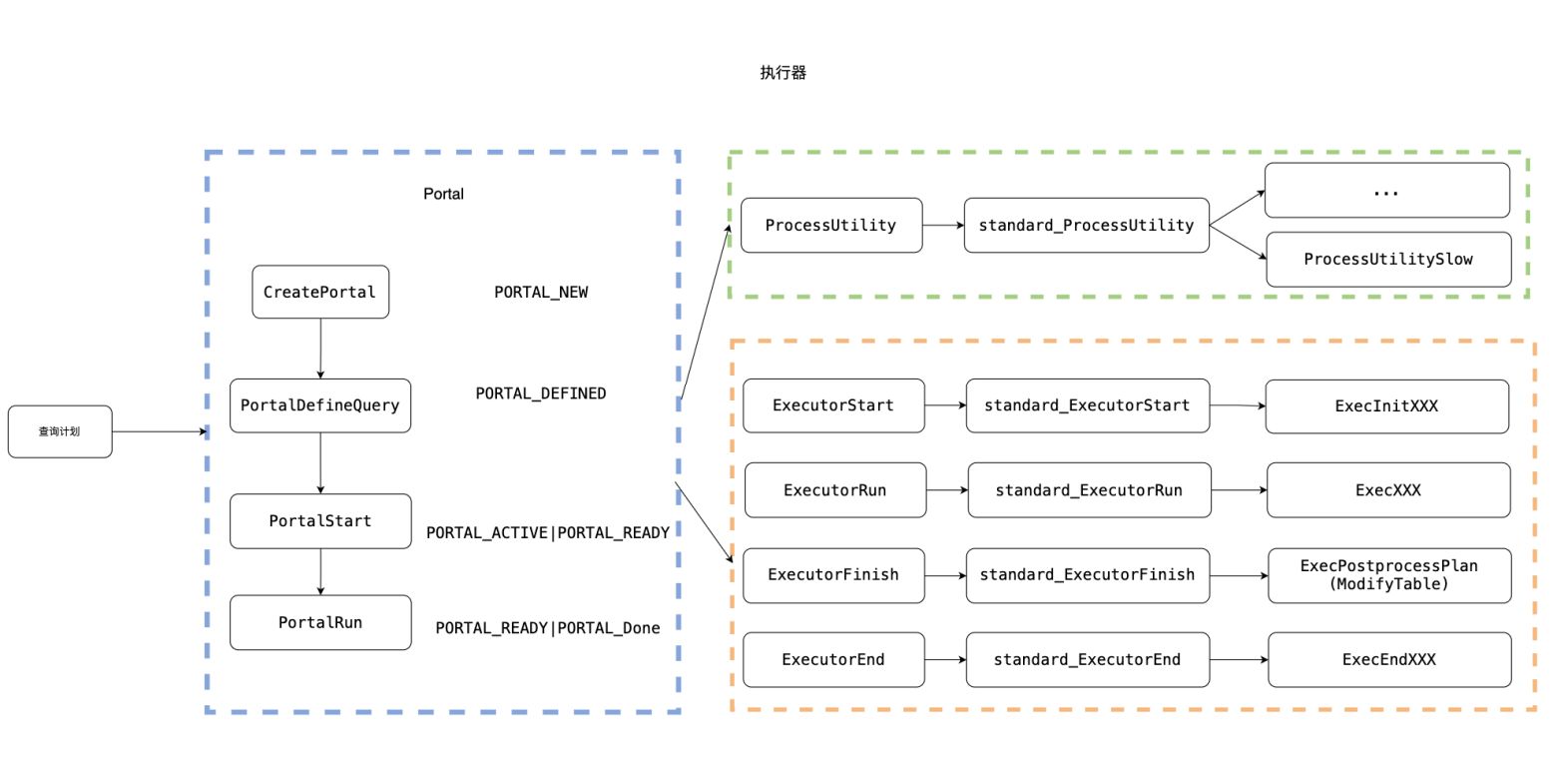 首先,我们需要明确执行器与查询计划之间的关系。传统方案中,执行器直接管理查询计划。而在新方案中,引入了一个Portal的概念。Portal实际上是一个中间层,它负责将查询计划进行转发,根据策略将其转化为对应的执行路径。
首先,我们需要明确执行器与查询计划之间的关系。传统方案中,执行器直接管理查询计划。而在新方案中,引入了一个Portal的概念。Portal实际上是一个中间层,它负责将查询计划进行转发,根据策略将其转化为对应的执行路径。 如上图所示,Portal作为一个关键组件,它记录了与执行相关的全面信息,例如查询树、计划树和执行状态。基于名称特性,Portal分为两种类型:命名Portal和匿名Portal。当用户提交查询时,根据查询的特性和需求,执行器会选择创建命名Portal或匿名Portal。对于常规的查询语句,如简单的数据检索,执行器会生成匿名Portal来快速处理。而对于需要特殊关注或精细控制的查询,如使用const游标的复杂查询,执行器则会创建一个具有特定名称的命名Portal。此外,每个Portal还内含了丰富的信息和状态数据,如执行策略、当前状态、查询描述以及游标位置等关键信息。更为重要的是,它与查询计划链表和查询完成结构紧密关联,这些结构进一步补充了查询执行的上下文,为用户和开发者提供了更为详尽的执行细节。
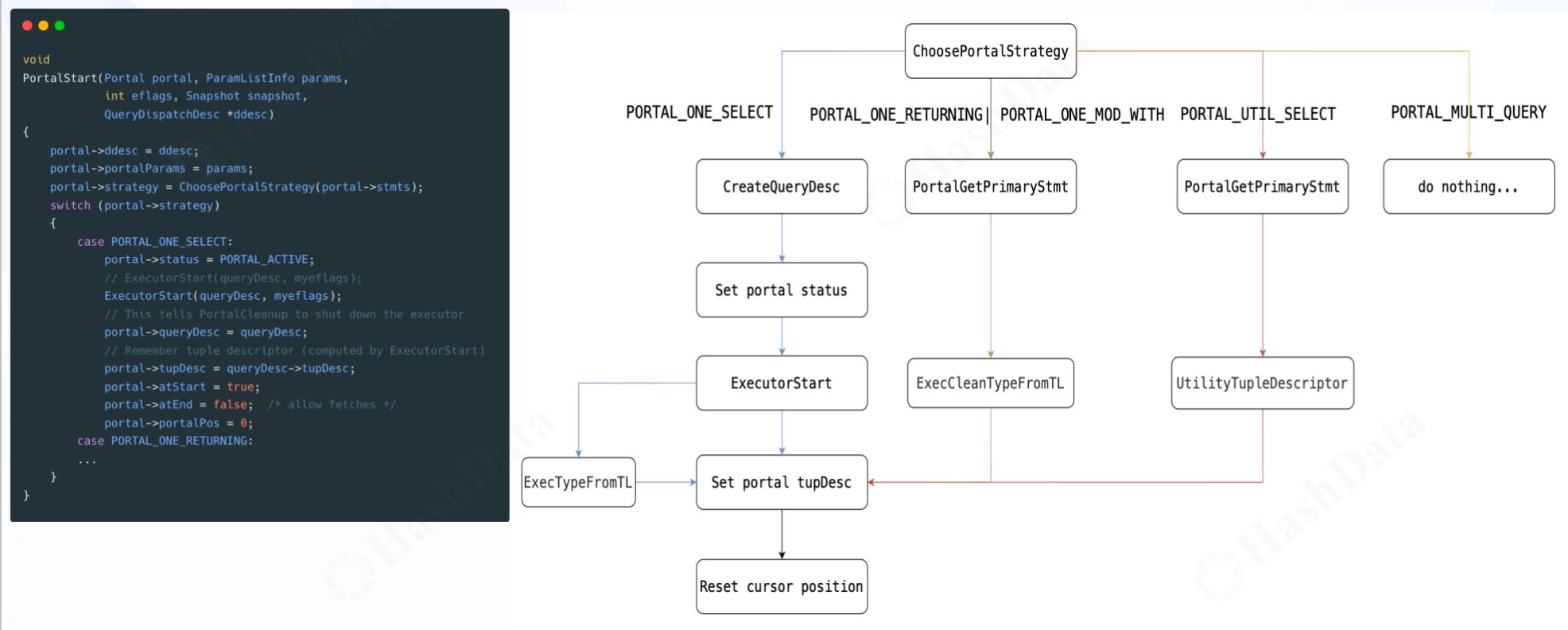
如上图所示,Portal作为一个关键组件,它记录了与执行相关的全面信息,例如查询树、计划树和执行状态。基于名称特性,Portal分为两种类型:命名Portal和匿名Portal。当用户提交查询时,根据查询的特性和需求,执行器会选择创建命名Portal或匿名Portal。对于常规的查询语句,如简单的数据检索,执行器会生成匿名Portal来快速处理。而对于需要特殊关注或精细控制的查询,如使用const游标的复杂查询,执行器则会创建一个具有特定名称的命名Portal。此外,每个Portal还内含了丰富的信息和状态数据,如执行策略、当前状态、查询描述以及游标位置等关键信息。更为重要的是,它与查询计划链表和查询完成结构紧密关联,这些结构进一步补充了查询执行的上下文,为用户和开发者提供了更为详尽的执行细节。 Portal的选择策略是依据SQL语句的类型和需求而定的。如上图所示,不同类型的SQL语句对应的处理策略。与执行器“三部曲”类似,Portal也有自己的“三部曲”:PortalStart、PortalRun和PortalDrop。
Portal的选择策略是依据SQL语句的类型和需求而定的。如上图所示,不同类型的SQL语句对应的处理策略。与执行器“三部曲”类似,Portal也有自己的“三部曲”:PortalStart、PortalRun和PortalDrop。
- PortalStart:初始化Portal参数(例如:填充tupDesc、初始化游标),设置执行器路径策略。
- PortalRun:根据SQL的语句类型选择不同的执行器路径,获取元组数据。
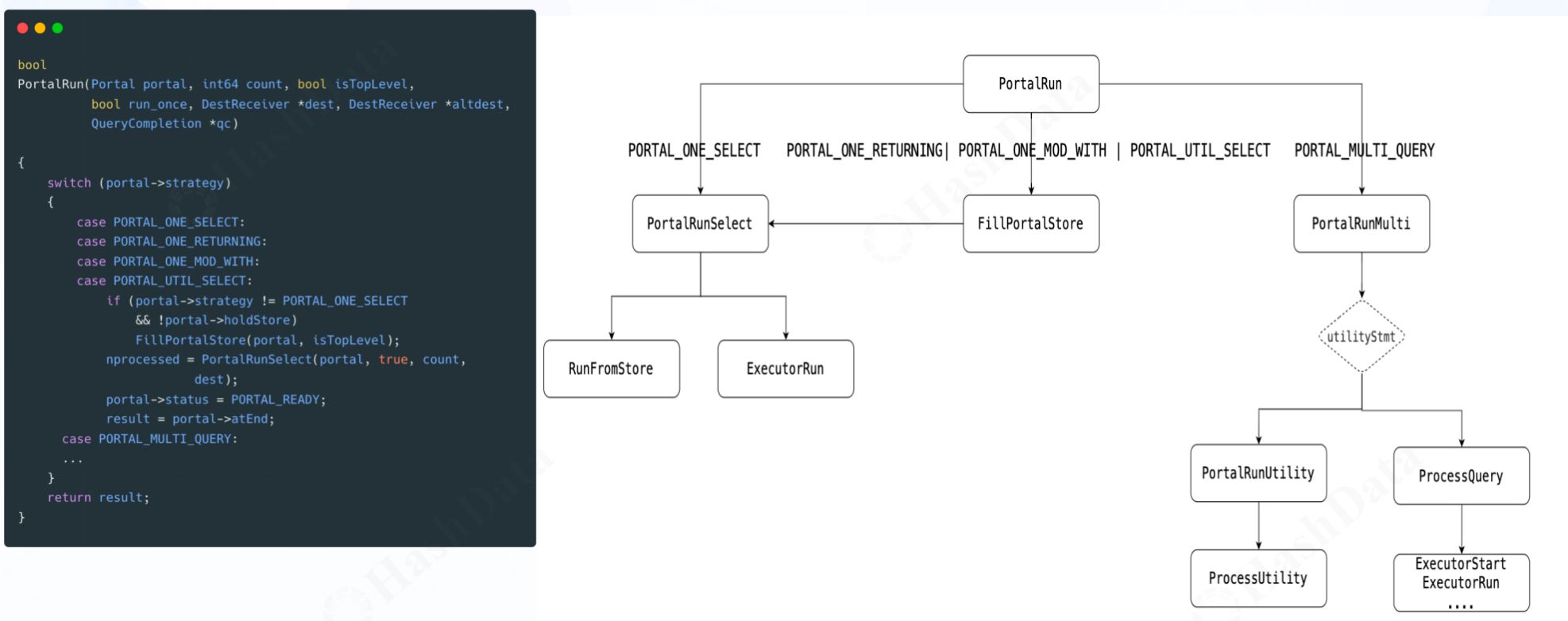
- PortalDrop:释放Portal的所有资源,终止执行器操作。

执行器与存储层如何关联?
关于执行器与存储层的关联,其中一个重要的方面是通过表Table AccessMethod与scan/modifyTable算子相联系。在PostgreSQL 14版本中,引入了一个名为TableAmRoutine的结构体。TableAmRoutine包含多种回调接口函数指针。对于那些想要实现自定义AM的开发者,只需将自己的接口钩子与这些函数指针相连接,便能实现一个新的存储引擎。在算子层面,比如我们提到的scan算子,它会与相应的扫描接口对接,调用这些接口来获取数据。而对于ModifyTable相关的算子,它会调用与写操作相关的接口。
表达式与投影
除了上面所提到的三个关联关系之外,如果要写一个执行器算子,还有重要的一点,就是表达式投影。在SQL语句中,除了SELECT、FROM、WHERE、GROUP BY等关键字之外的部分,都可以被认为是某种表达式,例如:a列,a + 1,a * b等等。下表列出了常见的表达式及其示例。 从表达式的实现原理来看,它涉及两个核心要素:表达式的上下文(ExprContext)和表达式的私有状态(ExprState)。ExprContext记录下每次表达式评估所需要的tuple,可能来自scan、outer、inner。而ExprState 是表达式求值的顶级节点,它包含:
从表达式的实现原理来看,它涉及两个核心要素:表达式的上下文(ExprContext)和表达式的私有状态(ExprState)。ExprContext记录下每次表达式评估所需要的tuple,可能来自scan、outer、inner。而ExprState 是表达式求值的顶级节点,它包含: 以一个经典的SQL为例,我们可以将其拆解:SELECT (a > 12 OR (a + b > 30)) and a < b from table;
以一个经典的SQL为例,我们可以将其拆解:SELECT (a > 12 OR (a + b > 30)) and a < b from table;
这个表达式可以分解为两部分,通过逻辑AND操作符连接:左侧是a > 12或(a + b > 30)的条件判断,右侧是a < b,这两部分形成一个决策树,如下图所示。 在内核层面实现时,每个节点会初始化一个对应的操作,称之为ExprEvalOp(EEOP)。决策树中的每个节点都与一个特定的EEOP相关联。例如,AND操作映射到EEOP_BOOL_AND_STEP,它表示逻辑“与”的评估步骤;OR操作,映射到EEOP_BOOL_OR_STEP。此外,还有EEOP_FUNCEXPR_STRICT,表示严格的函数表达式评估。这些EEOP根据节点的类型和需要执行的操作而有所不同。ExprEvalStep用于存储每一步评估的结果。例如,计算A + 12或A > 12的结果会被存储在Step信息中。Steps数组允许在评估过程中进行条件跳跃,例如在AND表达式中,当左侧条件满足时,可以跳过右侧条件的评估(如果逻辑允许)。此外,不同类型的表达式元素会映射为不同的EEOP。例如,如果算子是表扫描,则取出的列对应EEOP_SCAN_VAR。这些EEOP的选择取决于下游算子的类型和需要执行的具体操作。在决策树的执行过程中,我们可能会遇到不同的步骤类型,如FIRST STEP、STEP和LAST STEP。它们分别表示评估过程中的起始步骤、中间步骤和最终步骤。除此之外,还有一些关键函数和节点类型,帮助我们更好地理解表达式的执行过程:
在内核层面实现时,每个节点会初始化一个对应的操作,称之为ExprEvalOp(EEOP)。决策树中的每个节点都与一个特定的EEOP相关联。例如,AND操作映射到EEOP_BOOL_AND_STEP,它表示逻辑“与”的评估步骤;OR操作,映射到EEOP_BOOL_OR_STEP。此外,还有EEOP_FUNCEXPR_STRICT,表示严格的函数表达式评估。这些EEOP根据节点的类型和需要执行的操作而有所不同。ExprEvalStep用于存储每一步评估的结果。例如,计算A + 12或A > 12的结果会被存储在Step信息中。Steps数组允许在评估过程中进行条件跳跃,例如在AND表达式中,当左侧条件满足时,可以跳过右侧条件的评估(如果逻辑允许)。此外,不同类型的表达式元素会映射为不同的EEOP。例如,如果算子是表扫描,则取出的列对应EEOP_SCAN_VAR。这些EEOP的选择取决于下游算子的类型和需要执行的具体操作。在决策树的执行过程中,我们可能会遇到不同的步骤类型,如FIRST STEP、STEP和LAST STEP。它们分别表示评估过程中的起始步骤、中间步骤和最终步骤。除此之外,还有一些关键函数和节点类型,帮助我们更好地理解表达式的执行过程: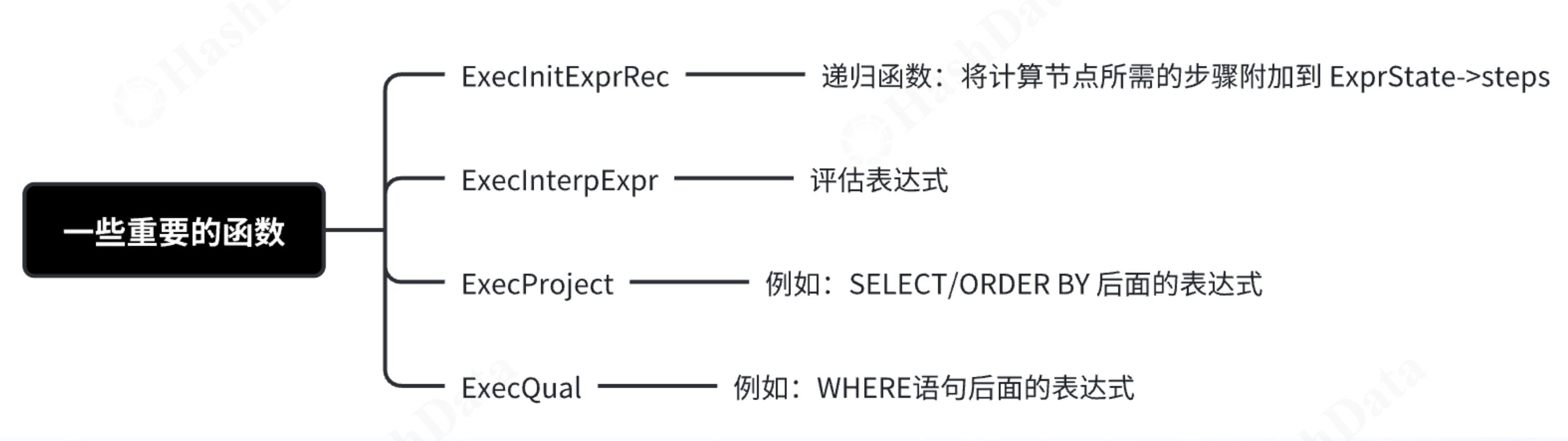
03如何写一个执行器算子?
假设有一个数据库需求,需要添加一个数据检查的功能,会检查其输入的数据,并对数据进行验证,如果发现数据不符合条件,则会抛出错误或者警告。例如如下plan:-> AssertAssert Cond: (i = 1)-> Seq Scan我们如何为数据库新增一个AssertOp算子呢?(不考虑优化器,只考虑执行器)第1步:创建文件并支持编译在数据库的executor目录中创建对应的.c和.h文件。修改makefile,将新创建的算子文件名添加到编译列表中。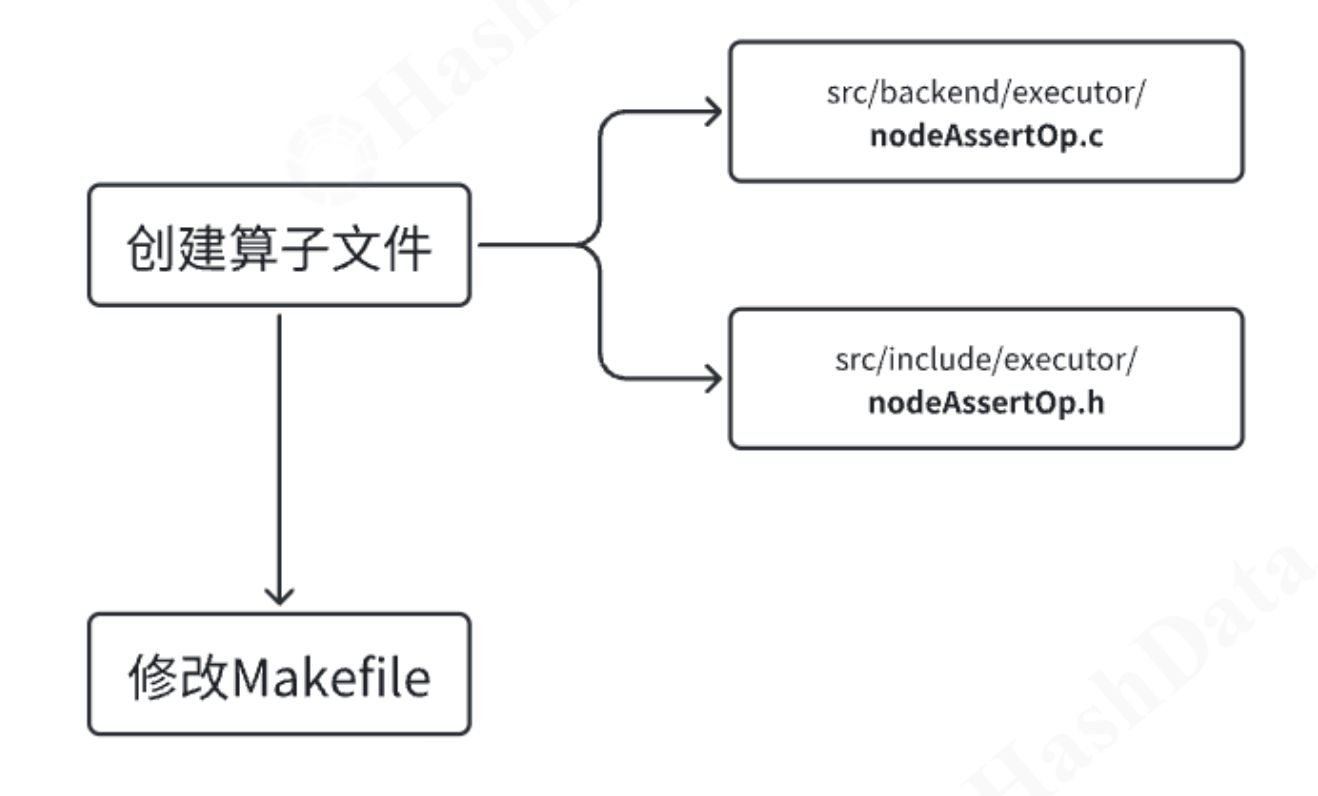 第2步:搭建框架在算子的.c文件中添加算子state,例如创建一个名为AssertOpState的结构体。实现执行器算子的关键接口,如ExecutorRun对应的ExecAssertOp函数。注意,这个接口在内部使用,并不对外暴露。
第2步:搭建框架在算子的.c文件中添加算子state,例如创建一个名为AssertOpState的结构体。实现执行器算子的关键接口,如ExecutorRun对应的ExecAssertOp函数。注意,这个接口在内部使用,并不对外暴露。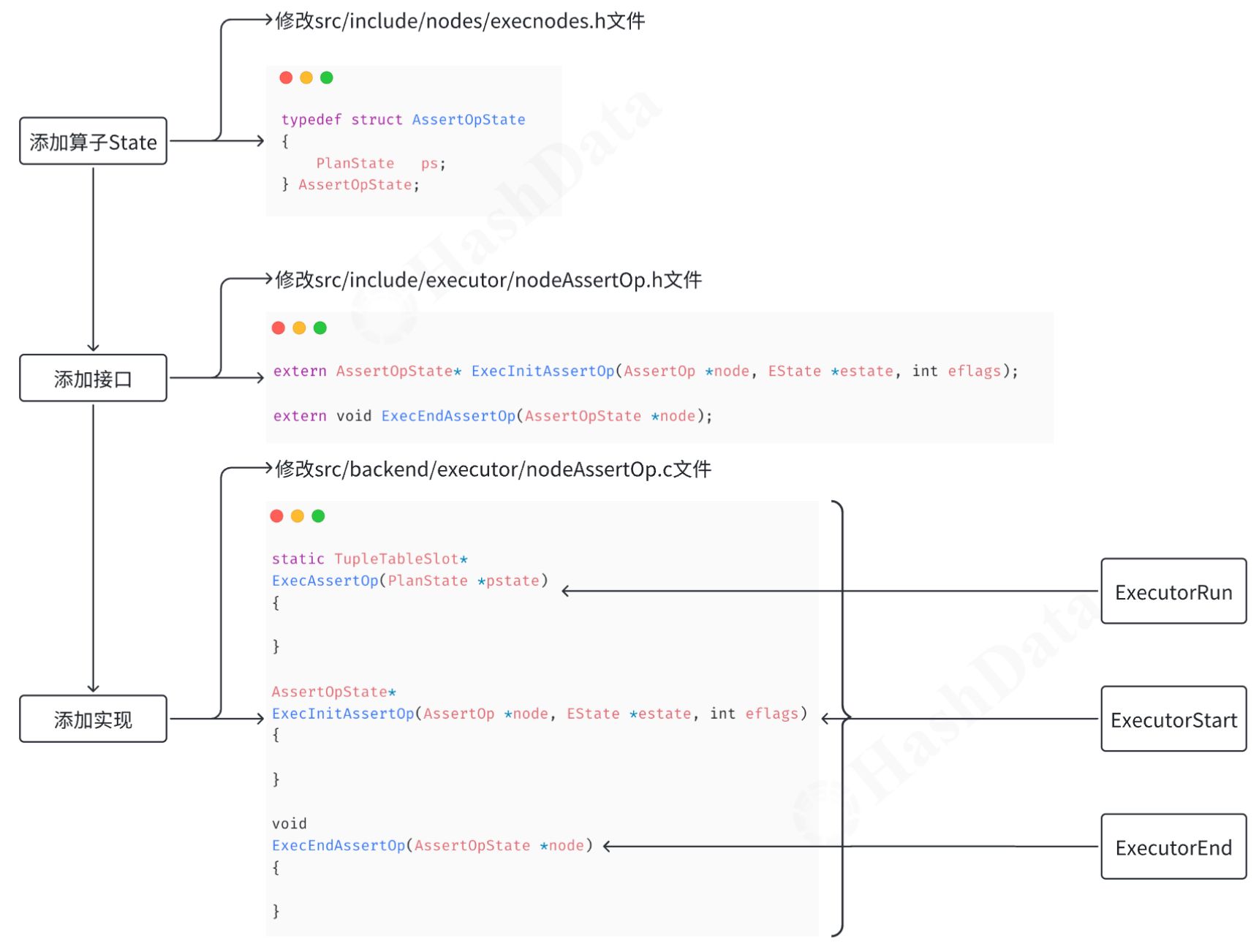 第3步:算子初始化在初始化阶段,绑定执行的核心事件和节点。初始化AssertOpState,分配必要的内存。初始化结果元组插槽(result tuple slot)以存储算子的计算结果。创建projectinfo以评估表达式,并初始化相关的qual list。
第3步:算子初始化在初始化阶段,绑定执行的核心事件和节点。初始化AssertOpState,分配必要的内存。初始化结果元组插槽(result tuple slot)以存储算子的计算结果。创建projectinfo以评估表达式,并初始化相关的qual list。 第4步:算子执行在执行阶段,从下游获取数据(soft)。基于获取的数据进行计算或验证。执行必要的投影(project)操作。
第4步:算子执行在执行阶段,从下游获取数据(soft)。基于获取的数据进行计算或验证。执行必要的投影(project)操作。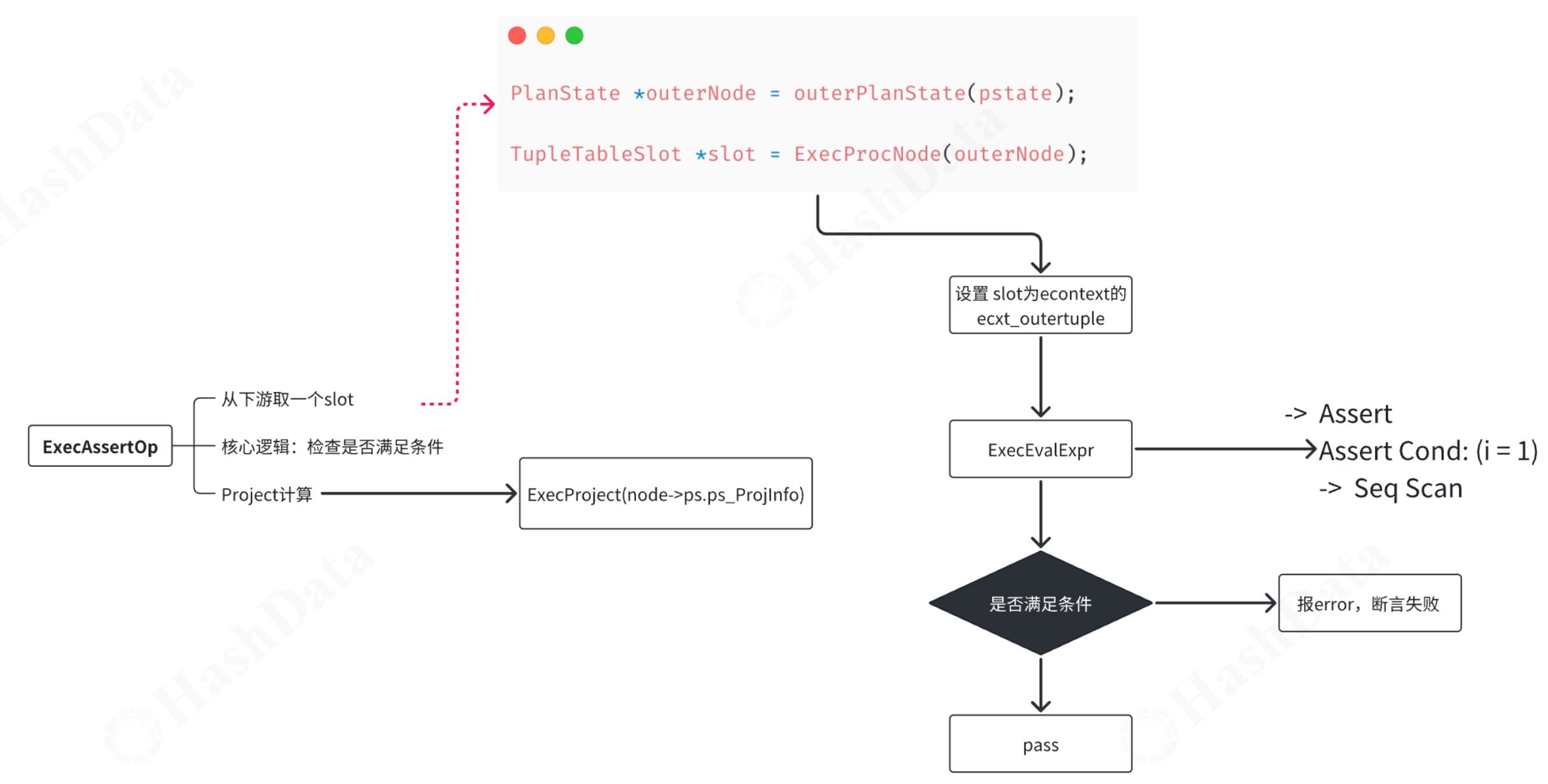 第5步:算子清理实现算子的清理工作,在ExecEnd时调用相应的清理函数。释放分配的资源,并结束下游算子的执行。
第5步:算子清理实现算子的清理工作,在ExecEnd时调用相应的清理函数。释放分配的资源,并结束下游算子的执行。 第6步:注册到各自上游通过init和end函数调用wrapper,并将算子注册到上游的switch case中。
第6步:注册到各自上游通过init和end函数调用wrapper,并将算子注册到上游的switch case中。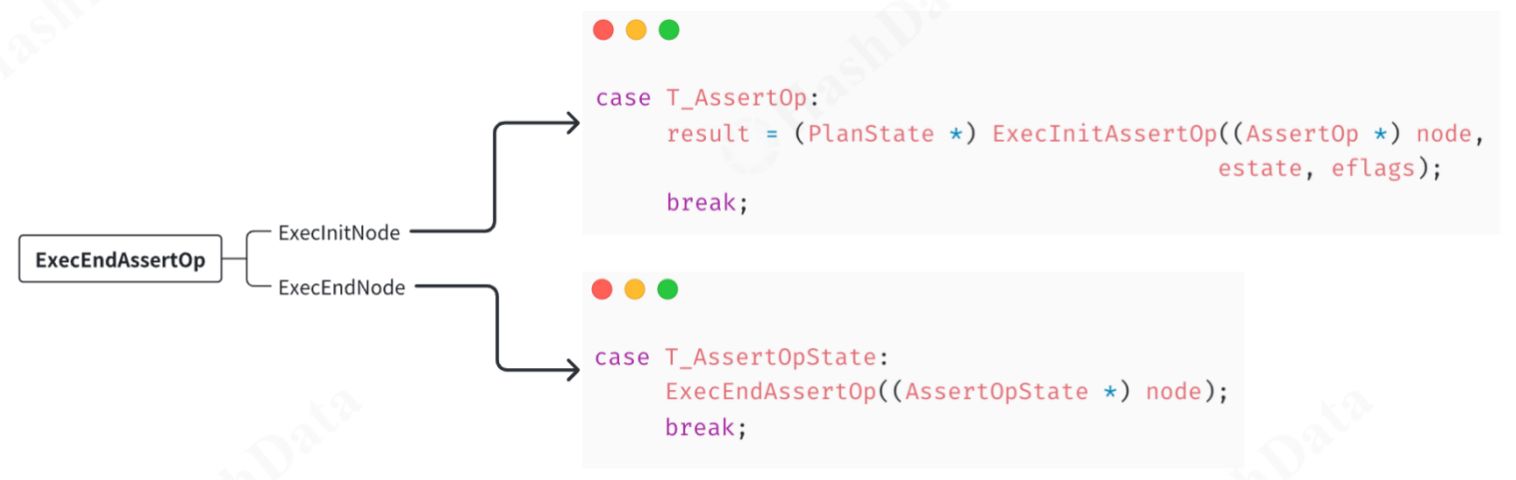 以上就是编写一个执行器算子的流程。
以上就是编写一个执行器算子的流程。
本次分享,我们为大家讲解了执行器处理模型,执行器流程,并现场演示了如何编写一个执行算子,希望能帮助开发者朋友们更好地理解数据库执行器。















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









