







线性表
1.逻辑结构
线性表是具有相同特性的数据元素的有限序列。
相同特性:把同一类归类,方便处理

例如在这个例子中,name、idnumber、height就是具有相同特性的数据。
有限:数据的量有限
序列:体现出逻辑关系,表示为谁是谁的前驱/后继。
ATTENTION:以上三个特性不仅仅适用于线性表,对于其他的数据结构依然适用。
2.存储结构
存储结构主要分为顺序结构和链式结构。
| 存储空间 | 基本代码 | |
|---|---|---|
| 顺序结构 | 存储空间连续 |  |
| 链式结构 | 不连续的存储空间 |  |
对于链式结构,进一步划分成单链表、循环单列表、双链表、循环双列表和静态链表
1、单列表
单链表存在两种状态,即有头节点和不含头节点,具体利用时主要是第一种。两种状态的区别是是否是所有的节点都含有信息。

特别地,链表节点的表示方法需要牢记:

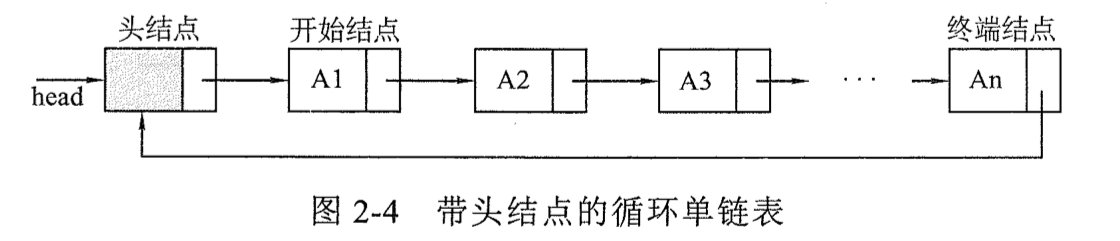
2、循环单列表
单链表最后一个指针域指向第一个节点,head->next==null为空
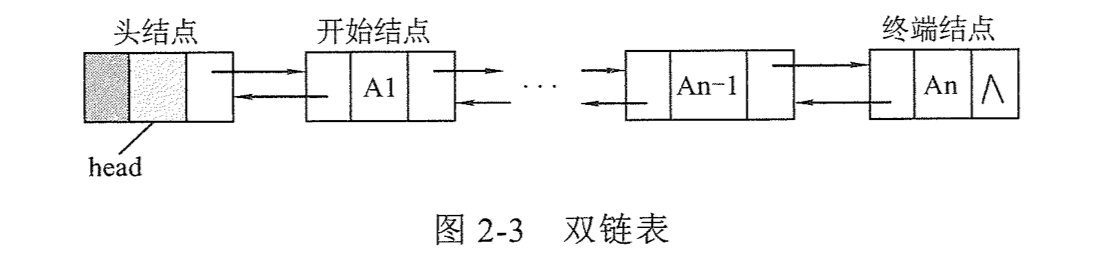
3.双链表
为了解决单链表从末尾的节点返回第一个节点困难的问题,定义了可以从最后一个节点倒序往前进行查找的双链表。
4.循环双链表
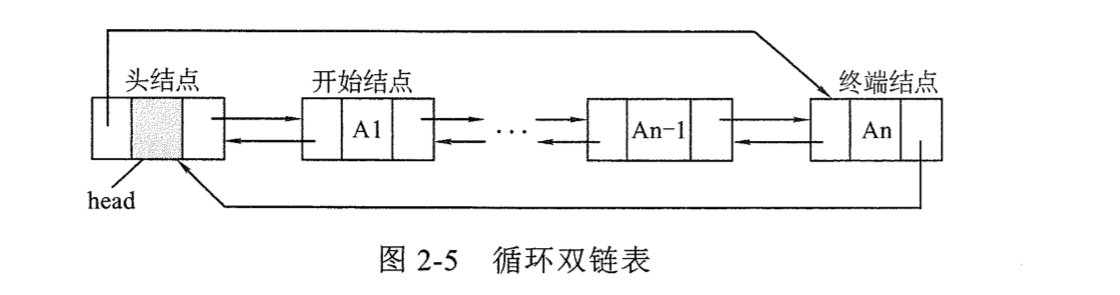
此链表判断为空的条件有4个,从其中的任何一个出发都可以判断循环双链表为空:
head->next==head;
head->prior==head;
head->next==head&&head->prior==head;
head->next==head||head->prior==head;
5.静态链表
借助于一维数组进行表示。静态的意思是指一次性分配一段连续的存储空间。
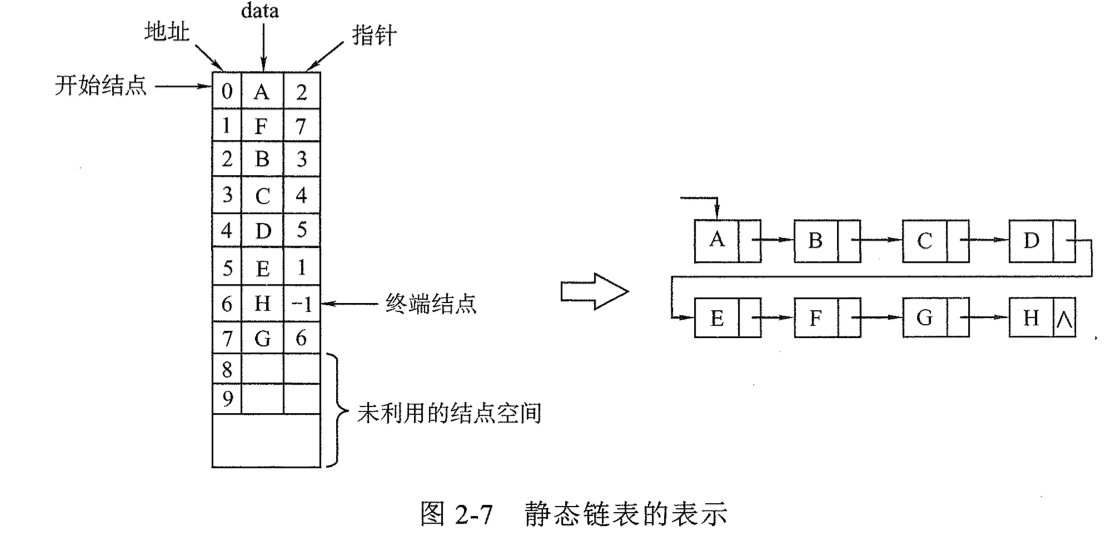

静态链表常用的代码:
//定义一个静态链表
typedef struct
{
int data;
int next;
}SLNode;
SLNode SLink[maxSize];//分配一段存储空间给链表
//静态链表取值
int p=Ad0; //定义一个指针
SLink[p].data; //取p指向的节点的值,类比p->data
SLink[p].next; //取p的后继节点的值,类比p->next
//在p节点后插入节点q
SLink[q].next=SLink[p].next;
SLink[p].next=q; //类比q->next=p->next;p->next=q
关于线性表和链表的比较:
| 空间 | 时间 | |||
|---|---|---|---|---|
| 存储空间分配的方式 | 存储密度 | 存取方式 | 插入/删除时移动元素的个数 | |
| 线性表 | 一次性分配 | =1 | 随机或顺序 |  |
| 链表 | 多次分配 | <1 | 顺序 | 0,只需要修改指针 |

一般来说,设置尾指针比设置头指针要好,理由在于:如下图所示,如果设置尾指针,则可以使得最后一个节点指向头节点,时间复杂度为O(1)。如果设置头指针,则在确定最后一个尾节点时需要一个一个确定,时间复杂度为O(N)。
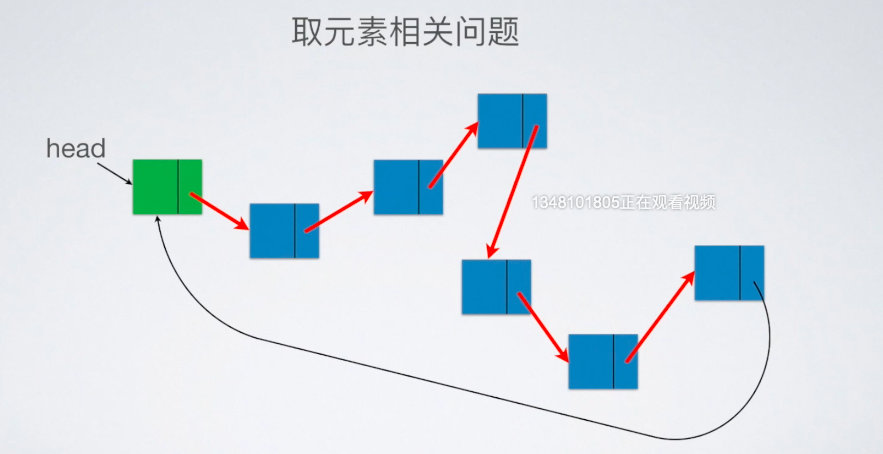
3.考点:建表
3.1 线性表的建表
int A[maxSize];
int length; //数组是顺序表的载体,length描述表长
int creatList(int A[], int &length) //int+数组本身就表示引用型
{
cin>>length; //纯c用scanf表示输入
if (length>maxSize)
return 0;
for (int i=0;i<length;i++)
cin>>A[i];
return 1;
}
3.2 链表建表
具体分为头插法和尾插法
3.2.1 尾插法

void createLinkListR[LNode *&head]
{
head=(LNode*)malloc(sizeof(LNode));
head->next = NULLL; //固定用法,用以分配一段连续的内存
LNode *p = NULL, *r = head; //定义两个指针,p用以接受新节点,r用以指向当前位置
int n;
std:: scanf("%d", &n);
{
p = (LNode*)malloc(sizeof(LNoode));
p->next = NULL;
std:: scanf("%d", &(p->data));
p->next = r->next; //此句和在中部插入没有区别
r->next = p; //让r指针总是指向p节点
}
}
3.2.2 头插法

void createLinkListH(LNode *&head)
{
head = (LNode*)malloc(sizeof(LNode));
head->next = NULL; // 固定用法:申请存储空尽
LNode *p = NULL;
int n;
std:: scanf("%d", &n);
for (int i = 0; i < n; i++)
{
p = (LNode*)malloc(sizeof(LNode));
p->next = NULL;
std:: scanf("%d", &(p->data));
p->next = head->next;
head->next = p;
}
}
举个例子:

思路如下:建立一个链表,将输入的数据和链表的数据进行比较,如果相等则为false,继续下一个元素的比对。如果不相等则开辟一块存储空间将数据存入链表,具体的代码如下:
void createLinkList(LNode, *&head);
{
head=(*LNode)malloc(sizeof(LNode));
head->next =NULL;
LNode *p;
int n;
int ch;
std::cin>>n;
{
std::cin>>ch;
p = head->next;
while(p != NULL){
if(p->data == ch)
break;
p->next = head->next;
}
if(p == NULL){
p = (*LNode)malloc(sizeof(LNode))
p->data = ch;
p->next = head->next;
head->next = p;
}
}
}
4.考点:插入和删除
4.1 链表的插入
关键在于p的后继节点不要丢
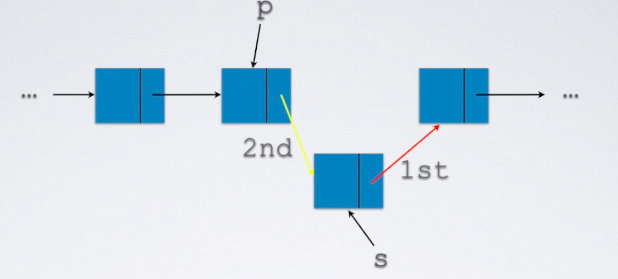
s->next=p->next;
p->next=s;
注意特殊情形:含有头节点的插入
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q1Pdfbbt-1624352119232)(…/Library/Application%20Support/typora-user-images/image-20210621200301099.png)]
4.2 链表的删除
不可以直接free(s),因为如果直接删除p节点的话,可能会弄丢s指针的信息。
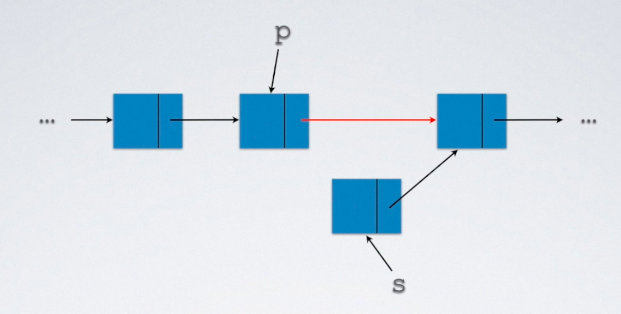
p->next=s->next;
free(s);
注意特殊情形:含有头节点的删除操作
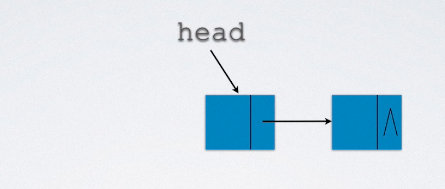
head=head->next;
ree(p);
小小的总结:
1)设置头节点的意义在于统一删除和插入的操作。
2)设置头节点时,其头指针不随操作而改变,可以减少错误。
4.3双链表节点插入
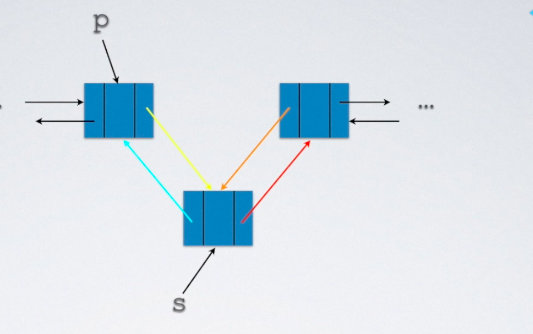
s->next=p->next;
s->prior=p;
p->next=s;
s->next->prior=s;
4.4双链表节点的删除
删除某节点时,只知道此节点的指针即可。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRfxWTS8-1624352119238)(…/Library/Application%20Support/typora-user-images/image-20210621163950577.png)]
s->prior->next=s->next;
s->next->prior=s->prior;
free(s);
4.4.1元素插入法

//创建一个顺序表
int sqList[maxSize]={1,2,3...,n};
int length = n;
//插入元素
int insertElem(int sqList[], int &length, int p, int e)
{
if(p<0 || p>length || length==maxSize)
return 0;
for(int i = length-1; i>=p; i--)
sqList[i+1]=sqList[i];
sqList[p]=e;
++length;
return 1;
}
4.4.2元素删除法

int deletElem(int sqList[], int &length, int p, int &e)
{
if(p<0 || p>length-1)
return 0;
e=sqList[p];
for(i=p; i<length-1; i++)
sqList[i]=sqList[i+1];
--length;
return 1;
}
5.考点:表逆置
5.5.1 顺序表逆置
主要思想:定义两个指针分别指向头尾,将头尾两侧的数据与一个多余的暂存数互换位置,循环往复往中间靠拢。当数据总数为奇数个时,i=j结束循环。当数据总数为偶数个时,ij互相跨越结束循环,也就是i<j的情况下完成逆置操作。
总之,当i<j时一定可以完成循环,故奇数偶数可以归结为同一段代码表示。

for(int i = left, j = right; i<j; ++j, --j)
{
temp=a[i];
a[i]=a[j];
a[j]=temp;
}
5.5.2 链表逆置
主要的思想是将头节点的指针重新指向,再将头节点的内容指向末尾的位置。此处相当于删除节点中不含free语句的语法+在末尾插入节点的语法。

while (p->next != q)
{
t = p->next;
p->next = t->next;
t->next = q->next;
q->next = t;
}
举个例子:

void reverse(int a[], int left, int right, int k){
int temp;
for(i = left , j = right; i < left+k && i<j; ++i,--j)
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}

思路1:前k个元素组合成一个块,整体挪到数组的最后;
思路2:将前k个元素逆置一次,再将前k个元素和后k个元素逆置一次,两次逆置可以保证结果为原序排列。
此处天勤采用思路2.虽然在一定程度上时间复杂度提高,但是同样是O(n)的复杂度,在要求不是很苛刻的情况下无伤大雅。
void moveToHead(int a[i], int n, int k)
{
reverse(a, 0, k-1, k);
reverse(a, 0, n-1, k);
}
最后给出了一道真题:

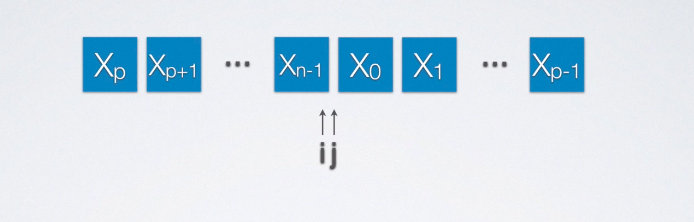
这道题主要的思路是先将0~p-1位置上的数逆置,再将p~n-1位置上的数逆置,最后将整个表逆置,由此得到结果
void reverse(int a[],int left, int right, int k)
{
int temp;
for(int i = left, j = right;i<left+k&&i<j; ++i,--j)
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
void moveP(int a[], int n, int p)
{
reverse(a, 0, p-1, p);
reverse(a, p, n-1, p);
reverse(a, 0, n-1, n);
}
在求解第三问的时候回顾时间空间复杂度的知识点:并列的时间复杂度=max时间复杂度的数量级。故复杂度是O(n).
6.考点:取最值
主要考察在线性表中取最置,此考点容易和其他考点相结合进行考察。
取最小值和最大值的思路一致,即先用一个指针a标记一个值,然后用指针b进行扫描,边扫描边比较,当扫描到一个值比指针a所标记的值要小的时候,将指针a指向这个目前为止的最小值,如此循环往复。
int max = a[0];
int maxIdx = 0;
for(int i = 0; i<n; i++)
{
if (max < a [i])
{
max = a[i];
maxIdx = i;
}
}
int min = a[0];
int minIdx = 0;
for(int i = 0; i<n; i++)
{
if (min > a[i])
{
min = a[i];
minIdx = i;
}
}
链表中取最大值最小值同理,只是将顺序表中的数组转换为指针。
LNode *p, *q;
int max = head->next->data;
q = p = head->next;
while( p != NULL)
{
if(max < p->data)
{
max = p->data;
q = p;
}
p = p->next; //相当于此处省略else
}
接下来是例子:

这道题要注意的是伪代码
{llink, data, rlink}
的定义:
对比于标准的结构体
typedef struct DLNode
{
int data;
struct DLNode *llink;
struct DLNode *rlink;
} DLNode;
由此可见,出题者已经将链表的结构体信息给出来了。
void maxFirst(DLNode *head)
{
DLNode *p = head->rlink, *q=p;
int max = p->data;
//以上是定义一个链表。
//接下来是找最值。注意单链表和双链表在代码上没有什么区别,
while (p != NULL)
{
if (max < p->data)
{
max = p->data;
q=p;
}
p = p->rlink;
}
//接下来是“删除”操作,此操作和删除的操作类似,只是没有free的过程。
DLNode *l = q->llink, *r = q->rlink;
l->rlink = r;
if (r != NULL)
r->llink=l;
//最后是是重新插入的操作:
q->llink = head;
q->rlink = head->rlink;
head->rlink = q;
q->rlink->llink = q;
}
另一道真题是:
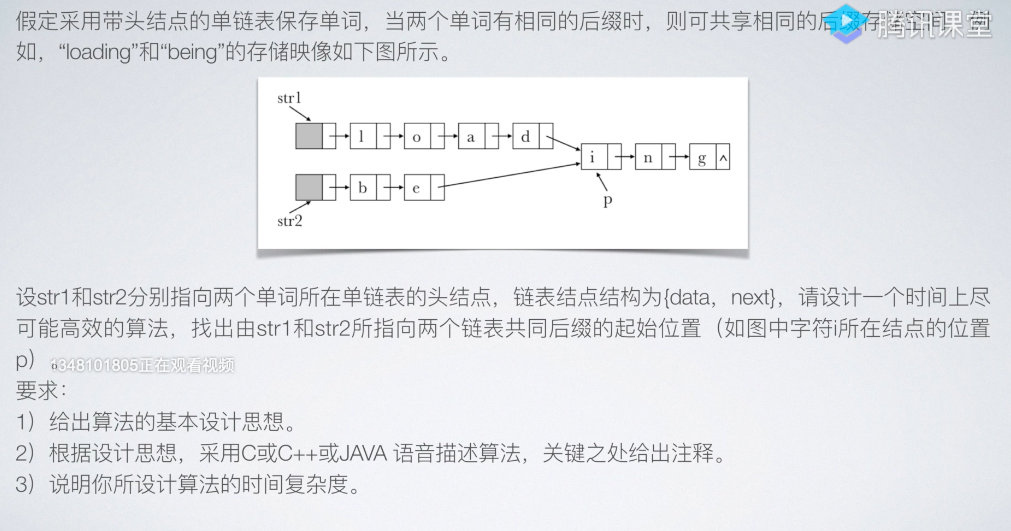
找出这道题的规律:发现如果找到共享节点前n步的那个节点,那么接下来再继续一起走n步可以保证所得到的节点有重复的部分。
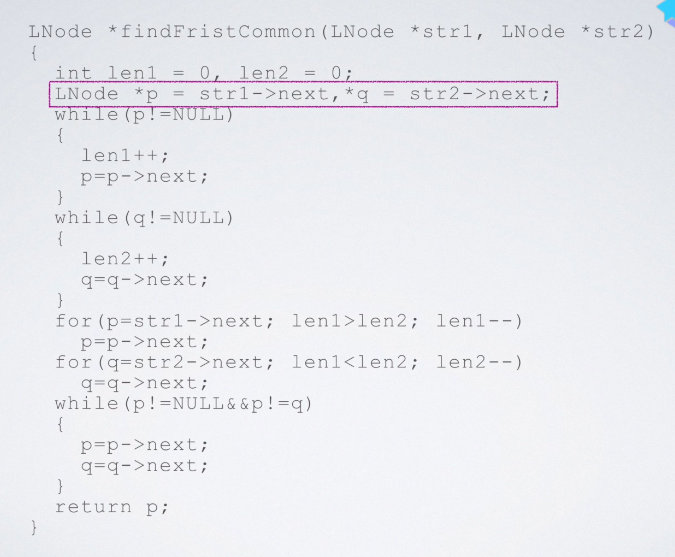
具体的代码是:
LNode *findFirstCommon(LNode *str1, LNode *str2)
{
int len1 = 0, len2 = 0;
LNode *p = str1->next, *q = str2->next;
while( p != NULL)
{
len1++'
p=p->next;
}
while( q != NULL)
{
len2++'
p=p->next;
}
for(p=str1->next; len1>len2; len--)
p=p->next;
for(q=str2->next; len1<len2; len2--)
q=q->next;
while(p!=NULL&&p!=q)
{
p=p->next;
q=q->next;
}
return p;
}
7.考点:划分
这一考点主要是将线性表进行划分。
7.1 划分的依据就是枢轴的值,第一个值作为枢轴

左移j并且同时进行判断
if (array[j] < temp)
{
array[i] = array[j];
++i;
}
右移i并且进行判断
if(array[i] >= temp)
{
array[j] = array[i];
--j;
}
当i=j的时候结束判断。
总体的代码如下:
void partition(int arr[], int n)
{
int temp;
int i = 0, j = n-1;
temp = arr[i];
while(i<j)
{
//i进行左移
while(i<j && arr[j]>=temp) //须保证每一步走完i始终<j
--j;
if(i<j)
{
arr[i] = arr[j];
++i;
}
//j进行右移
while(i<j && arr[i] <temp)
++i;
if(i<j)
{
arr[j] = arr[i];
--j;
}
}
arr[i] = temp;
}
7.2 划分的依据不是枢轴的值

最终的结果总结为:


从上图的例子中可以看出,枢轴的值决定了最终的划分的范围。
void partition(int arr[], int n, int comp) //和枢轴作为中心线的区别在于多了一个comp的参数
{
int temp;
int i = 0, j = n-1;
temp = arr[i];
while(i<j)
{
//i进行左移
while(i<j && arr[j]>=comp) //须保证每一步走完i始终<j,此处比较值改变为comp
--j;
if(i<j)
{
arr[i] = arr[j];
++i;
}
//j进行右移
while(i<j && arr[i] <comp) //此处比较值改变为comp
++i;
if(i<j)
{
arr[j] = arr[i];
--j;
}
}
arr[i] = temp;
}
7.3 以数组中任意一个数作为枢轴
思想大致和7.1与7.2没有什么区别,但是需要将要成为枢轴的值放在数组的第一位。
void partition(int arr[], int n, int k) //将作为枢轴的值设置尾参数k
{
int temp;
int i = 0, j = n-1;
temp = arr[i];
//以下是此问题中特有的代码段
//本质是将需要作为枢轴的值与数组的第一个值进行替换,进而后面的代码与上述两个问题完全相同。
temp = arr[0];
arr[0] = arr[k];
arr[k] = temp;
while(i<j)
{
//i进行左移
while(i<j && arr[j]>=comp) //须保证每一步走完i始终<j,此处比较值改变为comp
--j;
if(i<j)
{
arr[i] = arr[j];
++i;
}
//j进行右移
while(i<j && arr[i] <comp) //此处比较值改变为comp
++i;
if(i<j)
{
arr[j] = arr[i];
--j;
}
}
arr[i] = temp;
}
8.考点:归并
8.1 线性表归并
将两个较短的有序线性表变成较长的线性表。在线性表中只考虑两路归并。
本质就是两路相比较,然后选择最小的值放入归并完成的线性表中,按照从小到大的顺序进行归并。
具体的代码如下:

void mergearray(int a[], int m, int b[], int n, int c[])
{
int i = 0, j = 0;
int k = 0; //指示线性表的尾部
while (k<m &&j<n)
{
if(a[i] < b[j])
c[k++] = a[i++]; //相当于c[k] = a[i];k++;i++
else
c[k++] = b[j++];
}
while (i<m)
c[k++] = a[i++];
while (j<n)
c[k++] = b[j++]
}
8.2 链表归并
链表和线性表不一样的是在归并过程中不需要新建一个新的链表作为存放链表。在其中某个链表后续的数值大小已经排好序的时候,可以整个将其指向正在排序的链表。
具体的代码如下:
void mergeR(LNode *A,LNode *B,LNode *C)
{
LNode*p = A->next;
LNode*q = B->next;
C=A;
C->next = NULL;
free(B);
while(p != NULL && q != NULL)
{
if(p->data <= q->data)
{
s = p;
p = p->next;
s->next = C->next;
C->next = s;
}
else{
s = q;
q = q->next;
s->next = C->next;
C->next = s;
}
}
while(p != NULL)
{
s = p;
p = p->next;
s->next = C->next;
C->next = s;
}
while(q != NULL)
{
s = q;
q = q->next;
s->next = C->next;
C->next = s;
}
}
9.习题

最少的次数的可能性为:前一段的最大值比后一段的最小值要小,因而最少只要对比n次,选A

void reverse(LNode *L)
{
LNode *p = L->next, *q;
L->next = NULL;
while (p != NULL)
{
q=p->next;
p->next=L->next;
L->next = p;
p=q;
}
}

















 1290
1290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











