








数据倾斜(重要)
由于默认的分区规则,哈希值取模后可能会导致各分区的数据量相差过大,造成单个机器的负载过大,这就是数据倾斜。例如a a a b c c c d —>默认按照hash%2=区号规则分区:[aaa ccc] [b d]。
解决方案:
- 增加reduce的个数,但不能从根本上解决
- 重写分区规则
- 打散数据,把每个字母后面加上一个随机数后再取余,保证了数据均匀,但是需要再来一个机器汇总结果。
下面使用java模拟第三种方式
需求:F:\development\mrdata\skew\input\Skew.txt 文件 统计字母出现的个数
思路:
- 正常统计字母出现次数会产生数据倾斜,所以对字母处理一下:生成一个随机数拼接到字母后面 a-0/1 b-0/1 c-0/1 d-0/1 再计算他们的hash值取余,这样也可以输出到两个分区。
- 然而对于每个字母就不一定会到同一分区中了,(a-0)(a-1)会分到两个分区
- 所以需要对最终结果进一步处理,将结果汇总得到最后的结果。
package com.doit.demo.MRday05;
import com.doit.demo.Mrday03.MR_CountLetter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Random;
public class MR2_Skew1 {
static class MR2_Skew1_Mapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Random r = new Random();
int num = 0;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
num = context.getNumReduceTasks();
}
//拼接 a-0/1 - 1
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
try {
int i = r.nextInt(num);//随机数
String line = value.toString();
String[] split = line.split("\\s");
for (String s : split) {
String kStr = s + "-" + i;
k.set(kStr);
context.write(k,v);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
static class MR2_Skew1_Reducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
try {
int cnt = 0;
for (IntWritable value : values) {
cnt++;
}
v.set(cnt);
String s = key.toString();
String s1 = s.split("-")[0];
key.set(s1);
context.write(key,v);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "countLetter");
job.setMapperClass(MR2_Skew1_Mapper.class);
job.setReducerClass(MR2_Skew1_Reducer.class);
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("F:\\development\\mrdata\\skew\\input"));
FileOutputFormat.setOutputPath(job,new Path("F:\\development\\mrdata\\skew\\out"));
job.setNumReduceTasks(2);
job.waitForCompletion(true);
}
}
MR2合并两个reducetask的结果
package com.doit.demo.MRday05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Random;
public class MR2_Skew2 {
//合并最终结果 a 123 a 125
static class MR2_Skew2_Mapper extends Mapper<LongWritable, Text,Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\\s");
k.set(split[0]);
int i = Integer.parseInt(split[1]);
v.set(i);
context.write(k,v);
}
}
static class MR2_Skew2_Reducer extends Reducer<Text,IntWritable,Text,IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable value : values) {
int i = value.get();
sum+=i;
}
v.set(sum);
context.write(key,v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "countLetter");
job.setMapperClass(MR2_Skew2_Mapper.class);
job.setReducerClass(MR2_Skew2_Reducer.class);
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("F:\\development\\mrdata\\skew\\out"));
FileOutputFormat.setOutputPath(job,new Path("F:\\development\\mrdata\\skew\\out1"));
job.setNumReduceTasks(1);
job.waitForCompletion(true);
}
}
MR内部处理细节(重要)
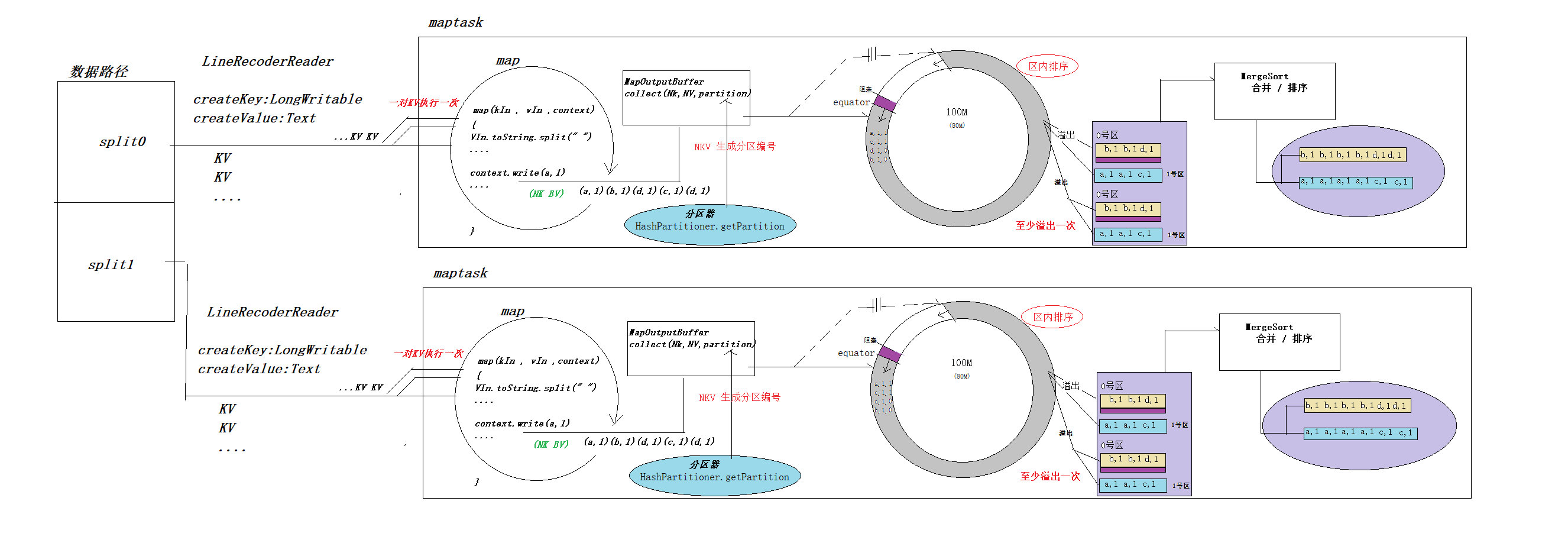
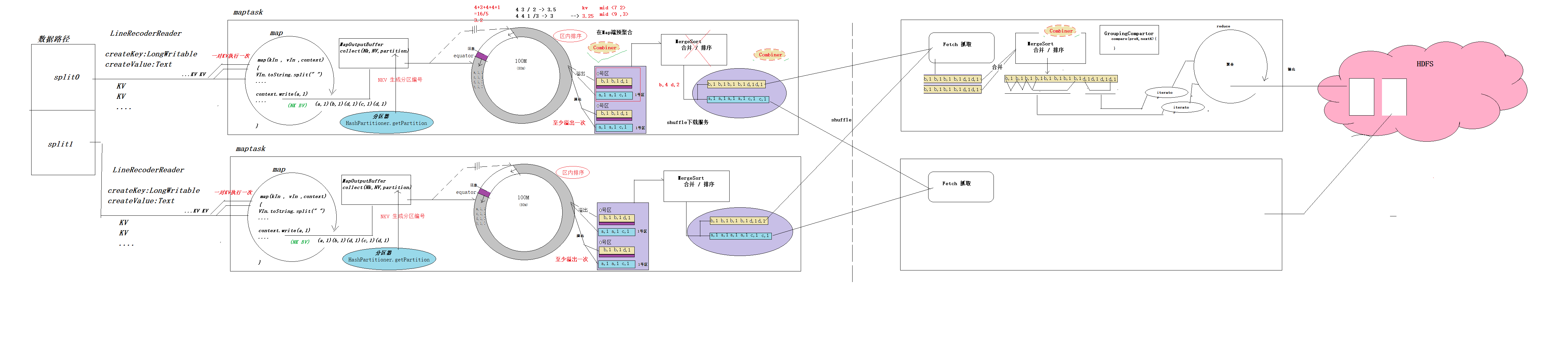
- 调用LineRecorderReader类的creatKey和creatValue方法,根据文件的数量和大小切片,生成kin和kout ,也就是偏移量和一行的数据
- 每一对kin和vin交给mapper类执行,map输出kout和vout,再经过分区器为每对kv调用内部的分区方法加上分区号。
- 将每一对kout vout partion以及元数据信息存入到环形数组
- 存储到数组的数据量过大,超过给定的阈值80M的时候,就会将此时的80M数据分区,排序,溢出到本地磁盘
- 同时还有20%的空间,此时就会继续添加数据到环形数组
- 当maptask任务执行完成后,调用MergeSort方法,把同一个区的数据加载到内存归并排序
- 将合并完的数据发到某台nodemanaager机器上,此时他就可以向reduce提供服务了,map阶段结束
- 当maptask全部落地到nodemanager以后,reduce调用Fatch开始抓取对应区的数据到reduce端的机器
- 拿到数据后,将数据合并,排序,然后调用GroupingCompartor根据key分组生成迭代器
- 调用自己的逻辑
- 将最终结果输出到分布式文件管理系统
分布式缓存

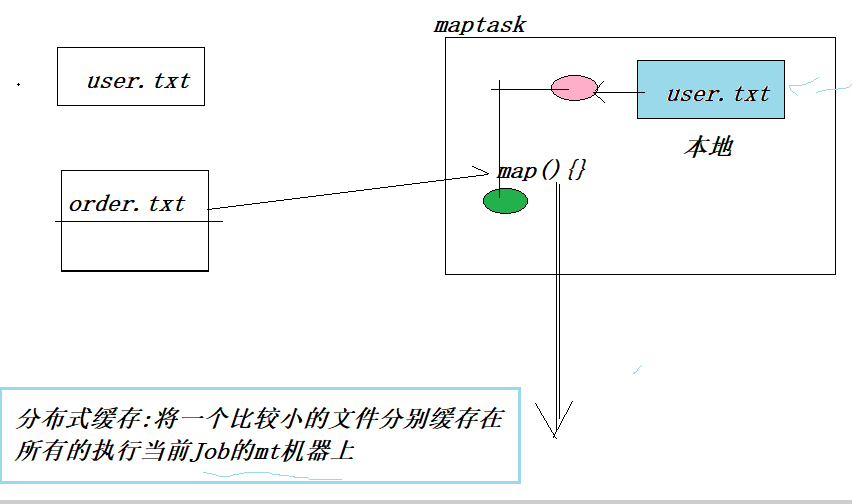
由于reduce操作效率并不高,对于一些很小的数据,如果可以交给map来处理就尽量不要交给reduce,所以设置了一个分布式缓冲区
下面用join的 案例来详细实现以下。
需求:读取order和user的信息,实现join,根据uid来连接。思路:
- 这里的用户信息很少,所以我们可以将它放到分布式缓冲区中,使用map直接得到最终结果
- mapper类的setup方法读取缓冲的信息(user文件)初步处理数据,将uid-userinfo存入到map集合
- map方法进一步处理,读取order文件,获取uid,和setup处理后的map中的uid匹配,连接对应的信息,最后输出结果。
package com.doit.demo.MRday05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
/*
实现join 不使用reduce
*/
public class MR1_JoinSide {
static class JoinSideMapper extends Mapper<LongWritable, Text,Text, NullWritable>{
//将userid-userinfo存入到map集合
Map<String,String> map = new HashMap<>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//读取缓存区文件
BufferedReader br = new BufferedReader(new FileReader("user.txt"));
String line = null;
while ((line=br.readLine())!=null){
String[] arr = line.split(",");
String uid = arr[0];
map.put(uid,line);
}
}
//处理maptask ->order
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(" ");
String oid = split[0];
String uid = split[1];
String userInfo = map.getOrDefault(uid,null);
String concat = oid+","+userInfo;
k.set(concat);
context.write(k,NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "joinSide");
//添加分布式缓存
job.addCacheFile(new URI("F:/development/mrdata/join/input1/user.txt"));
}
}
combiner
为了避免reducer的介入,尽可能到再map中输出最后的结果,引入了combiner类
还是统计单词个数的案例。这次不想向其他机器分发reduce任务,于是引入了combiner,实现在本地调用处理map结果的类,直接输出。
package com.doit.demo.MRday05;
import com.doit.demo.Mrday03.MR_CountLetter;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MR3_Wc {
static class WcMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
IntWritable v = new IntWritable(1);
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\\s+");
for (String s : split) {
k.set(s);
context.write(k,v);
}
}
}
//此时的reduce再map本机中被调用
static class WcReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int cnt = 0;
for (IntWritable value : values) {
cnt++;
}
v.set(cnt);
context.write(key,v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "countWord");
//只需要设置mapper和输出
job.setMapperClass(WcMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置combiner用来归并map的结果
job.setCombinerClass(WcReducer.class);
FileInputFormat.setInputPaths(job,new Path("d:\\word.txt"));
FileOutputFormat.setOutputPath(job,new Path("d:\\wordcount2222"));
job.setNumReduceTasks(1);
job.waitForCompletion(true);
}
}
序列化输出
以往的reduce端输出只是将文件原样输出:
falfaldfsjdlf
fsadhfsd
fsdadf
然后map端读取数据只会一行一行的读,读出来偏移量-每行的数据
其实我们可以自己设置输入和输出的格式:义序列化的形式输出
job.setOutputFormatClass(SequenceFileOutputFormat.class);//设置输出的格式
job.setIntputFormatClass(SequenceFileIntputFormat.class);//设置输入的格式
下面以求共同好友的案例来说明
需求:
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
求上面所有人的共同好友
思路:
- 使用两个MR程序
- MR1的map读取每行按照:分开,后面的每一个好友作为kout,前面的人p作为vout,得到 [b-a] [b-e] [c-a] [c-b]…
- MR1的reduce:对每一个key的values遍历,得到p将它存入到
list中 - 两层循环遍历list,拼接kout:a和e的共同好友是: 对应的vout:key。
- 由于最后的结果并不是想要得到的最终结果,于是将reduce的最终结果输出改变成序列化的形式输出。
package com.doit.demo.MRday05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/*
A:B,C,D,F,E,O
B:A,C,E,K
求所有人的共同好友
*/
public class MR4_Friends {
//b-a c-a ..
//a-b c-b e-b
//b-e
//b-[aec]
//遍历集合k->a和e的共同好友:v->b
static class FriendMapper extends Mapper<LongWritable, Text,Text,Text>{
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(":");
String vStr = split[0];
String s = split[1];
String[] keys = s.split(",");
for (String i : keys) {
k.set(i);
v.set(vStr);
context.write(k,v);
}
}
}
static class FriendReducer extends Reducer<Text,Text,Text,Text>{
Text k = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
List<String> list = new ArrayList<>();
//c将人存储到集合
for (Text p : values) {
String s = p.toString();
list.add(s);
}
for (int i = 0; i < list.size()-1; i++) {
for (int j = i+1; j < list.size(); j++) {
String pre = list.get(i);
String after = list.get(j);
String kStr = pre + "和" + after + "的共同好友是:";
k.set(kStr);
context.write(k,key);
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 1 创建一个Job
Job job = Job.getInstance(conf,MR4_Friends.class.getSimpleName());
// 2 设置mapper类
job.setMapperClass(FriendMapper.class);
// 3 设置reduce类
job.setReducerClass(FriendReducer.class);
// 4 设置map端和reduce端输出类型
// 指定map端的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// //指定最终结果的数据类型
// job.setOutputKeyClass(Text.class);
// job.setOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(1);
// 设置reduce的个数
// job.setNumReduceTasks(1);
//5 输入路径
job.setOutputFormatClass(SequenceFileOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("F:\\development\\mrdata\\friends\\input"));
// 6 输出路径
FileOutputFormat.setOutputPath(job, new Path("F:\\development\\mrdata\\friends\\out"));
//7 job提交 等待程序执行完毕
boolean b = job.waitForCompletion(true);
}
}
上面得到序列化后的结果:
a和e的共同好友是:--->b
a和e的共同好友是:--->d
接下来只需要将上面的相同k对应的v汇总就好了
- map读取,读取序列化后的数据,所以读取类型和上面MR1的reduce输出的kout-vout数据类型一致
- 直接写入即可,实现了相同的key-[好友列表]
- reduce端对每个key,遍历对应的values拼接对应的好友列表。
- 输出结果
package com.doit.demo.MRday05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/*
A:B,C,D,F,E,O
B:A,C,E,K
求所有人的共同好友
*/
public class MR4_Friends2 {
//b-a c-a ..
//a-b c-b e-b
//b-e
//b-[aec]
//遍历集合k->a和e的共同好友:v->b
static class FriendMapper extends Mapper<Text, Text,Text,Text>{
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
context.write(key,value);
}
}
static class FriendReducer extends Reducer<Text,Text,Text,Text>{
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for (Text value : values) {
sb.append(value).append(",");
}
String s = sb.toString();
String vStr = s.substring(0, s.lastIndexOf(","));
v.set(vStr);
context.write(key,v);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 1 创建一个Job
Job job = Job.getInstance(conf,MR4_Friends2.class.getSimpleName());
// 2 设置mapper类
job.setMapperClass(FriendMapper.class);
// 3 设置reduce类
job.setReducerClass(FriendReducer.class);
// 4 设置map端和reduce端输出类型
// 指定map端的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// //指定最终结果的数据类型
// job.setOutputKeyClass(Text.class);
// job.setOutputValueClass(IntWritable.class);
// job.setNumReduceTasks(1);
// 设置reduce的个数
// job.setNumReduceTasks(1);
//5 输入路径
job.setInputFormatClass(SequenceFileInputFormat.class);
FileInputFormat.setInputPaths(job, new Path("F:\\development\\mrdata\\friends\\out"));
// 6 输出路径
FileOutputFormat.setOutputPath(job, new Path("F:\\development\\mrdata\\friends\\out2"));
//7 job提交 等待程序执行完毕
boolean b = job.waitForCompletion(true);
}
}
来源:doit















 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









