







数据库组成:
数据库是一个组织和存储数据的系统,它由多个组件组成,这些组件共同工作以确保数据的安全、可靠和高效的存储和访问。数据库的主要组成部分包括:
数据库管理系统(DBMS): 数据库管理系统是数据库的核心组件,负责管理数据库的创建、维护、访问和控制。常见的数据库管理系统包括MySQL、Oracle、SQL Server、PostgreSQL等。
数据模型: 数据模型是描述数据在数据库中的组织方式的一种抽象表示。常见的数据模型包括层次模型、网络模型、关系模型和面向对象模型。关系模型是最常用的数据模型,它使用表、行和列来组织和表示数据。
数据库对象: 数据库对象是数据库中存储数据的基本单元。常见的数据库对象包括表、视图、索引、存储过程、触发器等。
表(Table): 表是数据库中存储数据的基本结构,它由行和列组成,每一列代表一个数据属性,每一行代表一个数据记录。
列(Column): 列是表的组成部分,每一列代表表中的一个数据属性,它定义了数据的类型、长度和约束条件。
行(Row): 行是表中的数据记录,每一行代表一个数据实体,它包含了一组相关的数据值,每个值对应表中的一个列。
索引(Index): 索引是一种数据结构,用于提高数据的检索速度。它可以加快数据库的查询操作,常见的索引类型包括单列索引、复合索引、唯一索引等。
视图(View): 视图是基于一个或多个表的查询结果集,它可以像表一样被查询,但实际上并不存储数据,而是通过查询动态生成。
存储过程(Stored Procedure): 存储过程是一组预定义的 SQL 语句集合,它们经过编译并存储在数据库中,可以被多次调用。
触发器(Trigger): 触发器是一种特殊的存储过程,它会在数据库中的特定事件发生时自动执行,常见的事件包括插入、更新和删除操作。
约束(Constraint): 约束是对表中数据进行限制和规范的规则,常见的约束类型包括主键约束、外键约束、唯一约束、检查约束等。
这些组件共同构成了数据库系统的基本架构,它们协同工作以实现数据的高效管理、存储、检索和保护。
表:
MySQL技能树学习-CSDN博客 MySQL技能树学习_mysql text长度是可变的吗-CSDN博客
视图:
概念:
视图可以由数据库中的一张表或者多张表生成,在结构上与数据表类似,但是视图本质上是一张虚拟表,视图中的数据也是由一张表或多张表中的数据组合而成。可以对视图中的数据进行增加、删除、修改、查看等操作,也可以对视图的结构进行修改。
在数据库中,视图不会保存数据,数据真正保存在数据表中。当对视图中的数据进行增加、删除和修改操作时,数据表中的数据会相应地发生变化;反之亦然。也就是说,不管是视图中的数据发生变化,还是数据表中的数据发生变化,另一方的数据也会相应地变化。
优点:
1.操作简单
将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简化了开发人员对数据库的操作。
2.数据安全
MySQL根据权限将用户对数据的访问限制在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。因此,可以根据权限将用户对数据的访问限制在某些视图上,而不必直接查询或操作数据表,这在一定程度上保障了数据表中数据的安全性。
3.数据独立
视图创建完成后,视图的结构就被确定了,当数据表的结构发生变化时不会影响视图的结构。当数据表的字段名称发生变化时,只需要简单地修改视图的查询语句即可,而不会影响用户对数据的查询操作。
4.适应灵活多变的需求
当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。
5.能够分解复杂的查询逻辑
数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
语法:
创建:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] [DEFINER = user] [SQL SECURITY { DEFINER | INVOKER }] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION]·CREATE:新建视图。
·REPLACE:替换已经存在的视图。
·ALGORITHM:标识视图使用的算法。
·{UNDEFINED | MERGE | TEMPTABLE}:视图使用的算法。其中,UNDEFINED表示MySQL会自动选择算法;MERGE表示将引用视图的语句与视图定义进行合并;TEMPTABLE表示将视图的结果放置到临时表中,接下来使用临时表执行相应的SQL语句。
·DEFINER:定义视图的用户。
·SQL SECURITY:安全级别。DEFINER表示只有创建视图的用户才能访问视图;INVOKER表示具有相应权限的用户能够访问视图。
·view_name:创建的视图名称。
·column_list:视图中包含的字段名称列表。
·select_statement:SELECT语句。
·[WITH [CASCADED | LOCAL] CHECK OPTION]:保证在视图的权限范围内更新视图。
查看:
- SHOW TABLE语句同时显示出了当前数据库中数据表的名称和视图的名称
- DESCRIBE/DESC view_name
- SHOW TABLE STATUS LIKE ‘view_name’
- SHOW CREATE VIEW 'view_name'
- SELECT * FROM information_schema.view
视图的信息存储到information_schema数据库下的views数据表中
更新:
结构:
- CREATE OR REPLACE VIEW
- ALTER
数据:
直接修改:
- 向视图中插入数据 INSERT INTO view_category(id, t_category) VALUES (5, '水果')
- 更新视图中的数据 UPDATE view_category SET t_category = '图书' WHERE id = 5
- 删除视图数据 DELETE FROM view_category WHERE id = 5
间接修改:(更新数据库表中的数据)
删除:

案例:
单表:


多表:
 存储过程和函数:
存储过程和函数:
存储过程和函数不仅能够简化开发人员开发应用程序的工作量,而且对于存储过程和函数中SQL语句的变动,无须修改上层应用程序的代码,这也大大简化了后期对于应用程序维护的复杂度。
概念:
存储过程和存储函数都是一系列SQL语句的集合,这些SQL语句被封装到一起组成一个存储过程或者存储函数保存到数据库中。应用程序调用存储过程只需要通过CALL关键字并指定存储过程的名称和参数即可;同样,应用程序调用存储函数只需要通过SELECT关键字并指定存储函数的名称和参数即可。
返回值(存储函数有,存储过程没有)
参数类型可以是IN(存储函数仅)、OUT和INOUT(存储过程都)
应用场景(复杂业务):
如果将用户下单时系统包含的这些行为单独编写每条SQL语句,之后根据SQL语句执行的先后顺序和结果条件,依次执行其他SQL语句,不仅增加了开发应用程序的业务逻辑复杂性,而且在每个需要处理订单逻辑的地方都需要编写这些SQL语句,SQL语句的变动也会导致应用程序中业务逻辑的变动,这无疑增加了系统后期维护与升级的复杂度。
此时,可以编写存储过程和函数,按照特定的执行顺序和结果条件,将相应的SQL语句封装成特定的业务逻辑,应用程序只需要调用编写的存储过程和函数进行相应的处理,而无须关注SQL语句实现的细节。同时,在后期应用程序的维护过程中修改了存储过程和函数内部的SQL语句,无须修改上层应用程序的业务逻辑。
优点:
1.具有良好的封装性
存储过程和函数将一系列的SQL语句进行封装,经过编译后保存到MySQL数据库中,可以供应用程序反复调用,而无须关注SQL逻辑的实现细节。
2.应用程序与SQL逻辑分离
存储过程和函数中的SQL语句发生变动时,在一定程度上无须修改上层应用程序的业务逻辑,大大简化了应用程序开发和维护的复杂度。
3.让SQL具备处理能力
存储过程和函数支持流程控制处理,能够增强SQL语句的灵活性,而且使用流程控制能够完成复杂的逻辑判断和相关的运算处理。
语法:
创建存储过程:
·CREATE PROCEDURE:创建存储过程必须使用的关键字;
·sp_name:创建存储过程时指定的存储过程名称;
·proc_parameter:创建存储过程时指定的参数列表,参数列表可以省略;
- [ IN | OUT | INOUT ] param_name type
·characteristic:创建存储过程时指定的对存储过程的约束;
·LANGUAGE SQL:存储过程的SQL执行体部分(存储过程语法格式中的routine_body部分)是由SQL语句组成的。
·[NOT] DETERMINISTIC:执行当前存储过程后,得出的结果数据是否确定。其中,DETERMINISTIC表示执行当前存储过程后得出的结果数据是确定的,即对于当前存储过程来说,每次输入相同的数据时,都会得到相同的输出结果。NOT DETERMINISTIC表示执行当前存储过程后,得出的结果数据是不确定的,即对于当前存储过程来说,每次输入相同的数据时,得出的输出结果可能不同。如果没有设置执行值,则MySQL默认为NOT DETERMINISTIC。
·{CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA}:存储过程中的子程序使用SQL语句的约束限制。其中,CONTAINS SQL表示当前存储过程的子程序包含SQL语句,但是并不包含读写数据的SQL语句;NO SQL表示当前存储过程的子程序中不包含任何SQL语句;READS SQL DATA表示当前存储过程的子程序中包含读数据的SQL语句;MODIFIES SQL DATA表示当前存储过程的子程序中包含写数据的SQL语句。如果没有设置相关的值,则MySQL默认指定值为CONTAINS SQL。
·SQL SECURITY {DEFINER | INVOKER}:执行当前存储过程的权限,即指明哪些用户能够执行当前存储过程。DEFINER表示只有当前存储过程的创建者或者定义者才能执行当前存储过程;INVOKER表示拥有当前存储过程的访问权限的用户能够执行当前存储过程。如果没有设置相关的值,则MySQL默认指定值为DEFINER。
·COMMENT 'string':表示当前存储过程的注释信息,解释说明当前存储过程的含义。
·routine_body:存储过程的SQL执行体,使用BEGIN…END来封装存储过程需要执行的SQL语句。


案例
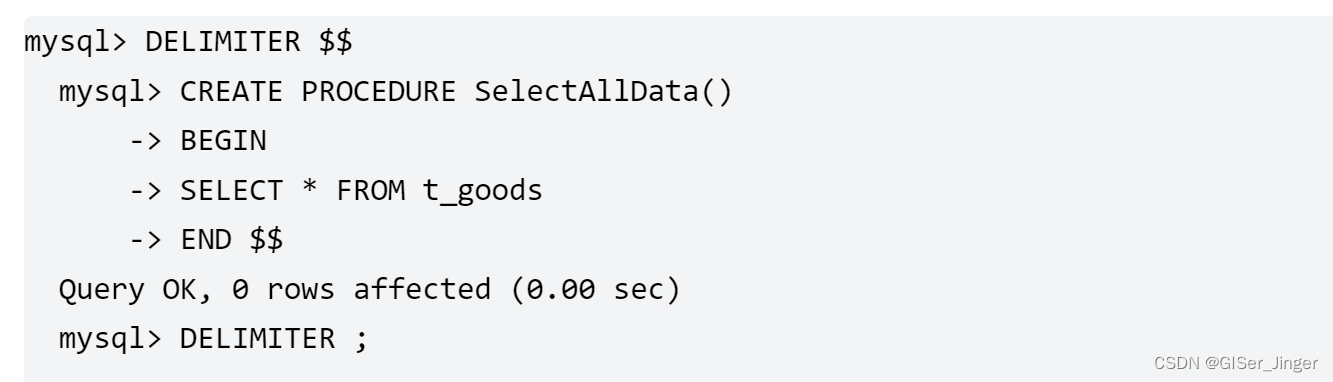
当用MySQL的命令行创建存储过程时,首先需要使用“DELIMITER $$”语句将MySQL数据库的语句结束符设置为“$$”。因为MySQL数据库默认的语句结束符为分号(;),如果不设置MySQL数据库的语句结束符,则存储过程中的SQL语句的结束符会与MySQL数据库默认的语句结束符相冲突。在创建存储过程的结尾使用“END $$”来结束存储过程。当整个存储过程创建完毕后,再使用“DELIMITER ;”语句将MySQL数据库的语句结束符恢复成默认的分号(;)。用MySQL命令行创建存储过程时,也可以使用DELIMITER语句指定其他符号为语句结束符,而不一定是“$$”符号。
索引和约束:
触发器:
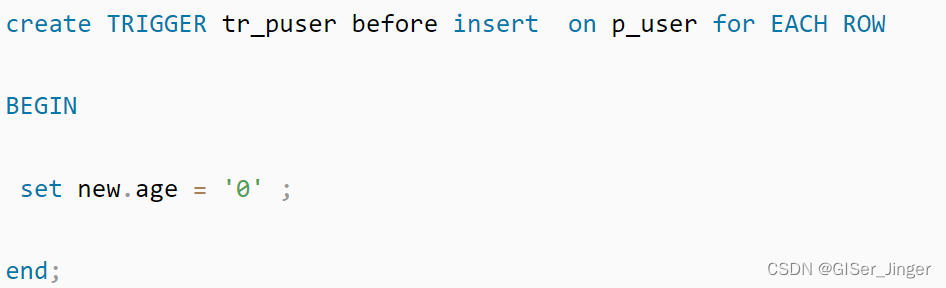
概念:
事先为某张表绑定好一段代码。当表中的某些内容发生改变的时候(增删改),系统自动触发代码执行。 即,触发器是基于(依赖于)表的。所有的触发器(针对数据库服务器而不是数据库)都会保存到数据库information_schema的triggers表中
类型:
三种类型:增删改–insert,delete和update(触发事件)
两种类型:前后–before 和 after(触发时间)
语法:
创建:
查看:
- show triggers;
- show create trigger 触发器名字;
删除:
drop trigger [数据库.]trigger_name;
局部变量:
声明:DECLARE var_name[,…] type [DEFAULT value]
赋值:SET var_name = expr


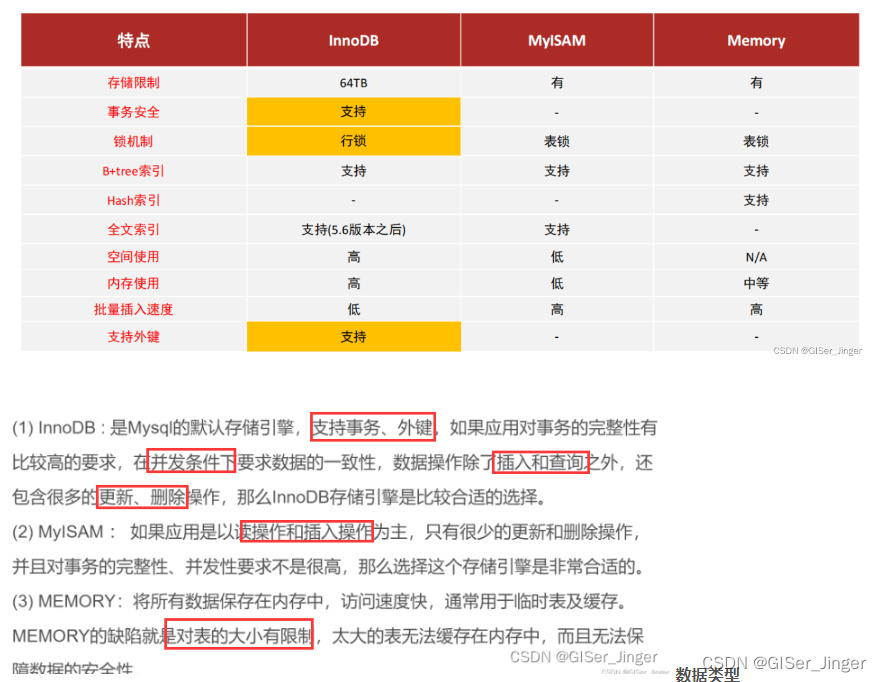
存储引擎:
存储引擎在MySQL底层以组件的形式提供,不同的存储引擎提供的存储机制、索引的存放方式和锁粒度等不同。
查看:SHOW ENGINES















 5552
5552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









