






(技术基础决定上层建筑)
大端模式和小端模式
小端模式:低地址放低位,高地址放高位。从数据的末尾开始存储。方便字符类型转换,CPU计算运算,先算地位再算高位。

大端模式:低地址放高位,高地址放低位(符合正常人读取顺序)符号位在最高位,方便直接读取数据正负。

Const(恒定的)关键字(只读常量)
(a)定义变量
定义(局部变量或全局变量)为常量。被const修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。
第一种和第二种是常量指针;第三种是指针常量;第四种是指向常量的常指针
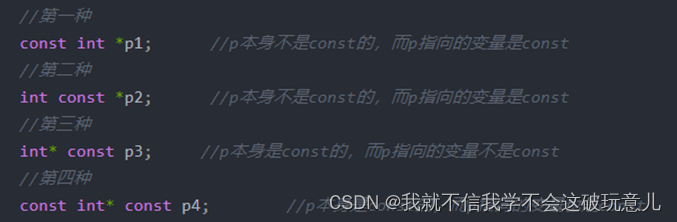
(b1)面试问题1:什么是常量(const)指针(*)?量在前面,量固定
不能通过这个指针改变变量的值,可以通过其他方式改变。
(b2)面试问题2:什么是指针(*)常量(const)? 指针在前面,指针固定
指针不能再指向其他的地址。
(b3)面试问题3:什么是指向常量的常指针?
啥都不变
static(静态的)关键字
1)用static修饰局部变量:使其变为静态存储方式(静态数据区),那么这个局部变量在函数执行完成之 后不会被释放,而是继续保留在内存中。
2)用static修饰全局变量:使其只在本文件内部有效,而其他文件不可连接或引用该变量。
3)用static修饰函数:对函数的连接方式产生影响,使得函数只在本文件内部有效,对其他文件是不可 见的(这一点在大工程中很重要很重要,避免很多麻烦,很常见)。这样的函数又叫作静态函数。使用 静态函数的好处是,不用担心与其他文件的同名函数产生干扰,另外也是对函数本身的一种保护机制。
volatile(易变的) 关键字
一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译器就不会去假设这个变量的值了。重新读取这个变量在内存中的值,而不是使用保存在寄存器里的备份。
以下几种情况都会用到volatile:
1、并行设备的硬件寄存器(如:状态寄存器)
2、一个中断服务子程序中会访问到的非自动变量
3、多线程应用中被几个任务共享的变量
extern(外部)关键字
在a文件(a.c)中引用b文件(b.c int v;)的全局变量,extern int v;在一个文件中引用另一个文件的全局变量,外部变量声明。

sizeof (数组/指针)与strlen (字符串)
strlen("\0") =? sizeof("\0")=? 两者结果与区别?
strlen("\0") =0,sizeof("\0")=2
strlen用来计算字符串的长度(在C/C++中,字符串是以"\0"作为结束符的),它从内存的某个位置(可以是字符串开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描直到碰到第一个字符串结束符\0为止,然后返回计数器值
sizeof是C语言的关键字,它以字节的形式给出了其操作数的存储大小,操作数可以是一个表达式或括在括号内的类型名,操作数的存储大小由操作数的类型决定
求sizeof
(1)数组:
数组所占存储空间的内存:sizeof(数组名)
数组的大小:sizeof(数组名)/sizeof(数据类型)
数组类型大小:sizeof *数组名(指向数组的指针)
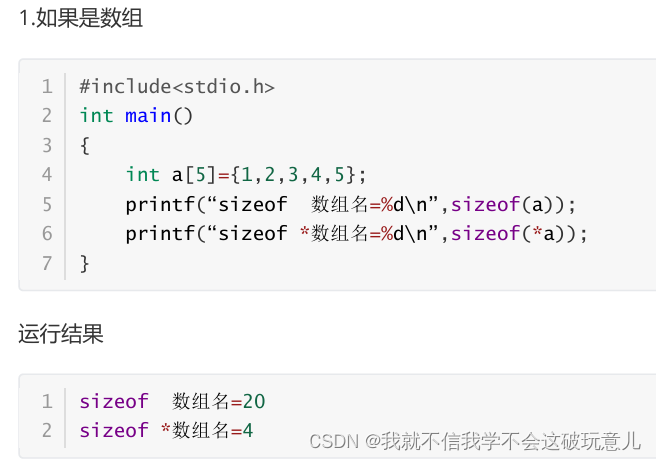
(2)指针:
在32位平台下,无论指针的类型是什么,sizeof(指针名)都是4,在64位平台下,无论指针的类型是什么,sizeof(指针名)都是8

typedef和define有什么区别?
(a)原理不同
#define是C语言中定义的语法,它是预处理指令,定义的时候不做检查。typedef是关键字,它在编译时处理,所以 typedef具有类型检查的功能。
(b)功能不同
typedef用来定义类型的别名 。#define不只是可以为类型取别名,还可以定义常量、变量。
(c)作用域不同
define定义过的变量可以全局使用,但是typedef只能局部使用。
指针
1.指针的定义
- 什么是指针?如何声明一个指针?
指针是一个变量,其值为另一个变量的内存地址。声明一个指针需要指定指针所指向变量的类型,并使用星号 * 符号来表示指针。
- 什么是指针的解引用操作符 * 和取地址操作符 &?它们的作用是什么?
指针的解引用操作符 * 用于访问指针所指向的内存地址中存储的值。取地址操作符 & 用于获取变量的内存地址。它返回变量在内存中的位置,这个位置可以被赋给指针。
- 什么是空指针?如何表示和检查空指针?
空指针是指不指向任何有效内存地址的指针,NULL。判断指针是否为NULL就能检查。
- 什么是野指针?它们会导致什么问题?
(1)野指针是指向不可用内存的指针,当指针被创建,指针不可能自动指向NULL,这时,默认值是随机的,此时的指针成为野指针
(2)当指针被free或delete释放掉时,如果没有把指针设置为NULL,则会产生野指针,因为释放掉的仅仅是指针指向的内存,并没有把指针本身释放掉
(3)第三个造成野指针的原因是指针操作超越了变量的作用范围
- 什么是指针的大小?在不同体系结构下,指针的大小有何不同?
指针的大小是指指针变量本身所占用的内存空间大小,在32位操作系统中,指针大小为4字节,在64位操作系统中,指针大小为8字节。
int* p 和 char* p 分别声明了两种不同类型的指针变量,分别指向整型和字符型数据。
int* p中的指针p每次增加一个单元时,将会移动sizeof(int)4个字节,因为指向整型数据。char* p中的指针p每次增加一个单元时,将会移动sizeof(char)1个字节,因为指向字符型数据。通常情况下,sizeof(char)恒等于1。- char *p=a; sizeof (p) =4;//32位系统下,指针大小为4 sizeof(*p)=1;//char指针大小为1
2.指针和数组:
- 指针和数组之间有什么关系?
数组名就是指向数组首元素的指针,可以通过指针传递数组给函数,指针可以指向数组、可以通过指针访问数组元素。
- 如何使用指针访问数组元素?指针和数组下标有什么区别?
可以通过 ptr + i 来访问数组的第 i 个元素,其中 ptr 是指向数组的指针。
- 如何将数组作为函数参数传递?为什么通常使用指针而不是数组来传递数组?
传递数组本身和传递数组的指针。通过传递数组的地址或者数组的首元素地址,可以在函数内部直接操作原始数组的内容,而不需要进行数组的复制。
- 什么是指向数组的指针?如何声明和使用它们?
指向数组的指针是指向数组首元素的指针。int (*ptr)[5]; // 声明一个指向整型数组的指针
指针数组:指针的数组 :int *p[4]。一个数组里面存了四个指针。中断向量表就是指针数组,数组中的元素为不同中断函数的指针。
数组指针:指向数组的指针:int (*p)[4]。 指针指向一个大小为4的数组,当p++移动的是四位。
3.指针和函数:
- 如何在函数中使用指针?为什么会选择使用指针而不是传值?
在函数中使用指针可以让函数直接修改传递给它的变量的值,而不是仅仅修改传值的副本。
 项目中多用于函数传值。
项目中多用于函数传值。
- 什么是指向函数的指针?它们有什么用处?
指向函数的指针是指向函数的内存地址的指针。return_type (*ptr_name)(param_list); 其中,return_type 是函数的返回类型,ptr_name 是指针变量的名称,param_list 是函数的参数列表。
- 什么是函数指针数组?如何声明和使用它们?
函数指针数组是一个数组,其元素都是指向函数的指针。换句话说,函数指针数组存储了多个函数的地址,使得程序能够动态地选择要调用的函数。
内存
分配内存的方式?
(1)静态存储区,分配全局变量和静态变量;
(2)栈空间,存放函数内的局部变量
(3)堆空间,new开辟的空间
堆(heap)和栈(stack)的区别?
栈是操作系统自动分配和释放的,操作速度快,但是栈空间有限。
堆是手动分配释放,操作速度慢,但空间区域比较灵活且大。
堆栈溢出的原因?
(递归层次深、动态申请内存未释放、数组越界、指针非法访问)
答:①递归函数调用层次太深,栈中需要保存每次递归调用的局部变量,当递归调用层次太深,会导致栈溢出;
②动态申请的变量保存在堆中,需要在调用结束后手动释放,否则也会导致堆溢出;
③数组下标越界;
④指针访问非法的内存地址。
内存泄漏
什么是内存泄漏?
申请一块内存,用完之后没有释放掉。
内存溢出
内存溢出是指程序在申请内存时,没有足够的内存空间供其使用,或者超出了系统能给的内存限制,导致程序无法正常运行
new/delete与malloc/free的区别是什么?
(1)new 能够自动计算需要分配的内存空间,而malloc需要手工计算字节数
(2) new与delete带具体类型的指针,malloc与free返回void类型的指针
(3)new 将调用构造函数,而malloc不能;delete将调用析构函数,而free不能
(4)malloc/free 需要库文件<stdlib.h>支持,而new/delete不需要库文件支持
# include< filename. h>和#include" filename. h"有什么区别?
对于 include< filename. h>,编译器先从标准库路径开始搜索filename.h,使得系统文件调用较快而 对于# include“ filename.h”,编译器先从用户的工作路径开始搜索filename.h,然后去寻找系统路径,使得自定义文件较快
C语言中 struct与 union的区别是什么?
struct(结构体)与 union(联合体)是C语言中两种不同的数据结构,两者都是常见的复合结构,区别主要表现在以下两个方面:
(1)结构体与联合体虽然都是由多个不同的数据类型成员组成的,但不同之处在于联合体中所有成员共用一块地址空间,即联合体只存放了一个被选中的成员,而结构体中所有成员占用空间是累加的, 其所有成员都存在,不同成员会存放在不同的地址在计算一个结构型变量的总长度时,其内存空间大小等于所有成员长度之和(需要考虑字节对齐),而在联合体中,所有成员不能同时占用内存空间,它们不能同时存在,所以一个联合型变量的长度等于其最长的成员的长度
(2)对于联合体的不同成员赋值,将会对它的其他成员重写,原来成员的值就不存在了,而对结构体的不同成员赋值是互不影响的
链表有几种类型
(1)单链表:在每个结点中除了包含数据域外,还包含一个指针域,用以指向其后继结点。
(2)双向链表:双链表就是在单链表结点上增添了一个指针域,指向当前结点的前驱。
(3)循环单链表:只要将单链表的最后一个指针域(空指针)指向链表中第一个结点即可。
(4)循环双向链表:循环双链表的构造源自双链表,即将终端节点的next指针指向链表中第一个结点,将链表中第一个结点的prior指针指向终端结点。















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









