






torch.nn.Conv2d()函数详解
参数详解:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)

torch.einsum()函数详解
没太看懂
nn.ReLU()函数
参考博客:MindSpore算子笔记--nn.ReLU_HUAWEIZHIZHE的博客-CSDN博客_relu算子
关于nn.ReLU函数_开飞机的小毛驴儿的博客-CSDN博客_nn.relu
pytorch中nn.Sequential和nn.Module区别与选择
参考博客:pytorch中nn.Sequential和nn.Module区别与选择_小小麦田mll的博客-CSDN博客
model.eval()函数
参考博客:Pytorch中model.eval()的作用分析_Codefmeister的博客-CSDN博客_model.eval()作用
python中view函数_pytorch中的view函数和max函数
参考博客:python中view函数_pytorch中的view函数和max函数_子文一点点的博客-CSDN博客
pytorch.max()的详细解释_可大侠的博客-CSDN博客_pytorch中的max
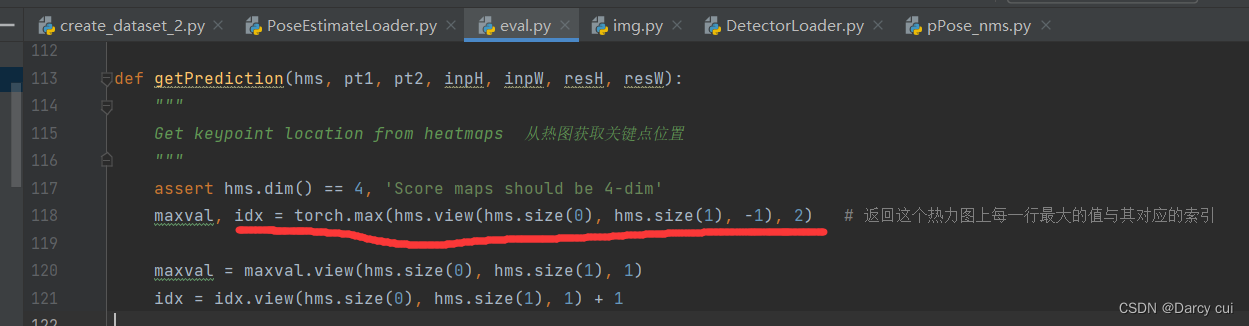
pytorch中repeat()函数理解
参考博客:pytorch中repeat()函数理解_tequila53的博客-CSDN博客_pytorch repeat
pandas.get_dummies 的用法
参考博客:pandas.get_dummies 的用法_魔术师_的博客-CSDN博客_pandas.get_dummies
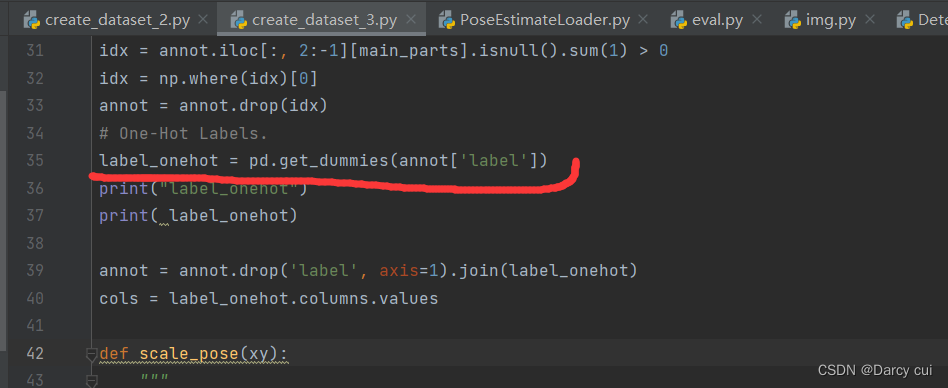
ndarray 切片
参考博客:05 ndarray 切片_库伯的博客-CSDN博客_ndarray切片
函数:seq_label_smoothing(labels, max_step=10): 理解
参考博客优化策略5 Label Smoothing Regularization_LSR原理分析_lqfarmer的博客-CSDN博客
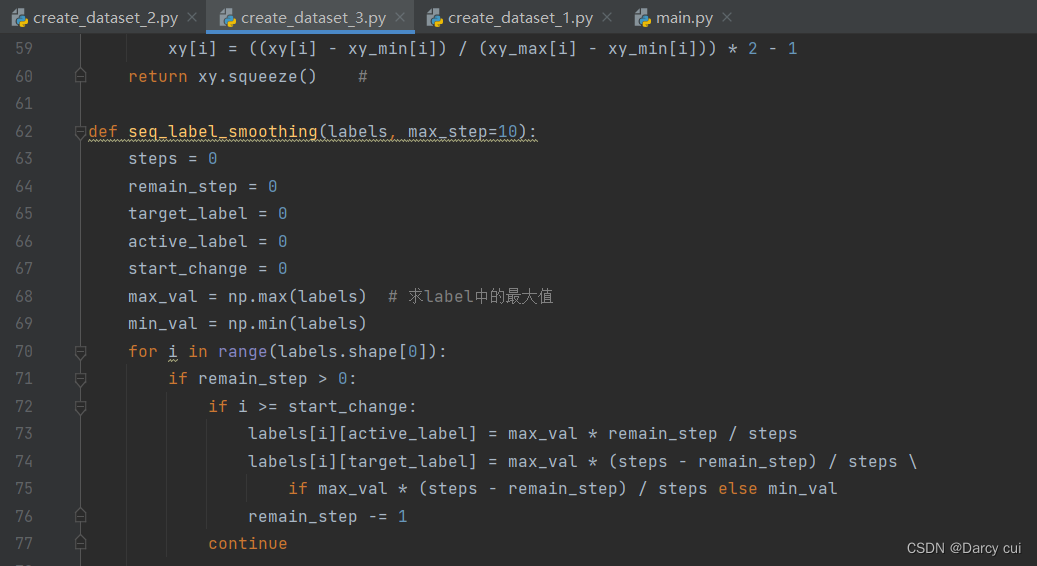
代码理解:是一种通过在输出y中添加噪声,实现对模型进行约束,降低模型过拟合(overfitting)程度的一种约束方法(regularization methed)。
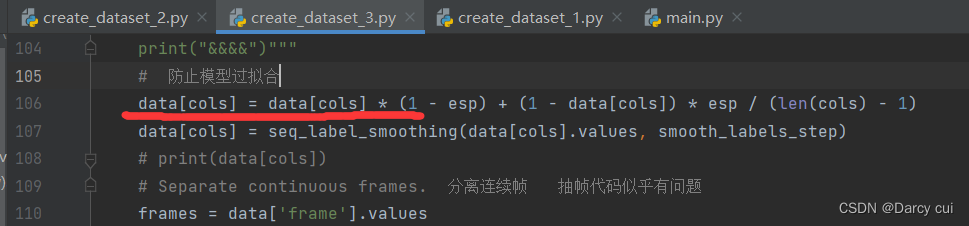
讲解:

GCN代码网络解读
def __init__(self, in_channels, out_channels, kernel_size,
t_kernel_size=1,
t_stride=1,
t_padding=0,
t_dilation=1,
bias=True):
super().__init__()
self.kernel_size = kernel_size
self.conv = nn.Conv2d(in_channels,
out_channels * kernel_size,
kernel_size=(t_kernel_size, 1),
padding=(t_padding, 0),
stride=(t_stride, 1),
dilation=(t_dilation, 1),
bias=bias)
def forward(self, x, A):
x = self.conv(x)
n, kc, t, v = x.size()
x = x.view(n, self.kernel_size, kc//self.kernel_size, t, v)
x = torch.einsum('nkctv,kvw->nctw', (x, A))
return x.contiguous()
现在,我们可以写出带有 kk 个卷积核的图卷积表达式了:
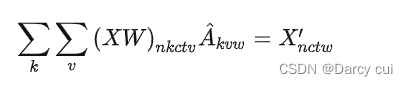
表达式可以用爱因斯坦求和约定表示nkctv,kvw->nctv。
其中
- n 表示所有视频中的人数(batch * man)
- k 表示卷积核数(使用上面的分解方法 k=3)
- c 表示关节特征数(64 ... 128)
- t 表示关键帧数(150 ... 38)
- v 和 w 表示关节数(使用 OpenPose 的话有 18 个节点)
对 v 求和代表了节点的加权平均,对 k 求和代表了不同卷积核 feature map 的加权平均。
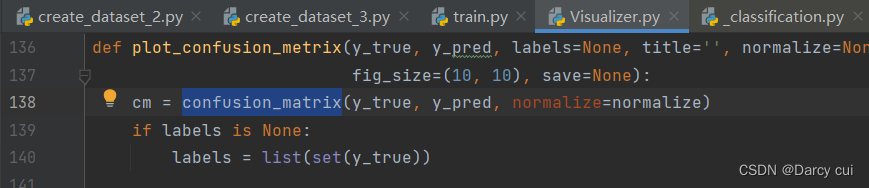
模型评估——混淆矩阵confusion_matrix
参考博客:模型评估——混淆矩阵confusion_matrix_abc123mma的博客-CSDN博客_confusion_matrix()
Sklearn的train_test_split用法
参考博客:Sklearn的train_test_split用法_fxlou的博客-CSDN博客_sklearn train_test_split

















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











