







算法篇
knn算法
算法原理:1、计算测试集和训练集所有样本的相似度(距离);2、按照距离递增排序;3、选择与测试样本最近的k个训练集样本、4、对选出的k个样本的标签进行求众数或平均(分类算法求众数、回归算法求均值)
算法的特点:1、时间复杂度高(暴力搜索);2、k值不同、结果不同;
代码原理实现
import numpy as np
# 以预测电影类型作为例子,标签为离散型,所以用分类算法
# 获取训练集样本特征
train_X = train_data[["搞笑镜头", "拥抱镜头", "打斗镜头"]]
# 获取训练集标签
train_y = train_data['电影类型']
# 测试集样本
test_X = ['25', '42', '12']
# 计算相似度
dis = np.sqrt(np.sum((test_X - train_X)**2, axis=1))
# 增加一列距离列
train_data['距离'] = dis
# 对距离排序
train_data.sort_values(by='距离', inplace=True)
# 获取k=5并求众数
print('电影类型:', train_data['距离'].head(5).mode()[0])
使用sklearn实现
# 导包
from sklearn.neighbors import KNeighborsClassifier
# 实例化knn
# n_neighbors相当于k
knn = KNeighborsClassifiter(n_neighbors=5)
# 拟合
knn.fit(train_X, train_y)
# 预测
y_pred = knn.predict(test_X)
# 获取准确率(test_y为真实测试集标签)
print('准去率:', knn.score(test_X, test_y))
knn算法优化
在实例化算法时,有几个需要注意的参数:
knn = KNeighborsClassifier()
def __init__(self, n_neighbors=5,weights='uniform',algorithm='auto', leaf_size=30,p=2, metric='minkowski', metric_params=None,n_jobs=None,**kwargs):
"""
参数n_neighbors----------> k
参数weights权重:distance and uniform
训练样本中各类样本的数量不均衡时使用distance
一般认为超过4:1时为不均衡
参数algorithm:{'auto', 'ball_tree', 'kd_tree', 'brute'}
默认自动选择,球树,k维树,暴力搜索
"""
kd树
这是一种优化knn算法的计算方式
基本原理:
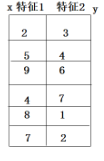
1、对于一个只有两个特征x和y的训练集,比较两列的特征的方差,方差最大的作为第一个考虑对象,将其从小到大排列,选出中位数(注意:此处的中位数必须是一个固定的值,也就是说当有两个中位数时,不需要求他们的均值,只需要任选一个),选出中位数所在的(x,y)作为根节点(比如方差最大的是x列,根节点的子节点将考虑y列的中位数,子节点的子节点再考虑x,以此类推)

2、将小于中位数的(x,y)作为根节点的左子节点,将大于中位数的(x,y)作为根节点的右子节点,再对两个子节点的y值进行排序和求中位数,比中位数小的放左边,比中位数大的放右边,直到每个子节点只剩一个叶子节点时停止
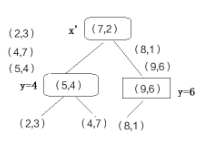
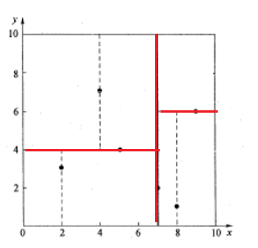
注:红线为中位数
搜索方法:
1、比如给定一组特征(2.1,3.1),由于我们上面的kd树的根节点是先根据x判断的,所以先判断2.1和7的大小,很显然比7小放到根节点的左边
2、根节点的子节点是根据y来判断的,所以比较3.1和4的大小,比4小放到左边
3、进行回溯,先从路径中取出(2,3)点作为最近邻点,计算到查询点的距离,dis=0.1414。再回溯到父节点(5,4),以(2.1,3.1)为圆心,dis为半径画圆,发现并不与y=4相交,也就是说没有大于四与(2.1,3.1)更临近,所以(5,4)的右子树就不再考虑
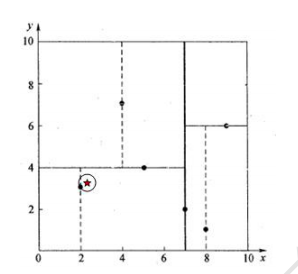
4、继续向上回溯到根节点,同理以(2.1,3.1)为圆心,dis为半径画圆,更不会与x=7相交,所以不考虑(7,2)的右子树
5、得出结论,与(2.1,3.1)最近邻的点是(2,3)
在此kd树中只进行了三次运算,如果使用暴力搜索则会进行六次运算,相对于暴力搜索快一点
寻找最优k值的方法
交叉验证
利用嵌套循环探究k值和knn中的参数weights的最佳匹配
for k in [1, 15]:
for w in ['distance', 'uniform']:
网格搜索
网格搜索的基础就是交叉验证,是通过sklearn的方法来实现的
from sklearn.model_selection import GridSearchCV
# 实例化
# 有两个重要参数
# 1、算法名称, 比如knn
# 2、param_grid={"n_neighbors":[3,5], "weights":['uniform', 'distance']}
grid = GridSearchCV(knn, param_grid={"n_neighbors":[3,5], "weights":['uniform', 'distance']})
# 拟合
grid.fit(x_train, y_train)
print('最好的参数:', grid.best_params_)
print('最好的得分:', grid.best_score_)















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









