







1.问题:model training不能多次训练?
每次修改epoch但是输出结果却没有任何变化,询问群友,发现是checkpoints没有删除
于是修改Linux只读权限,然后重新训练
2.现在一边在训练lora权重,一边试着精进bert大模型

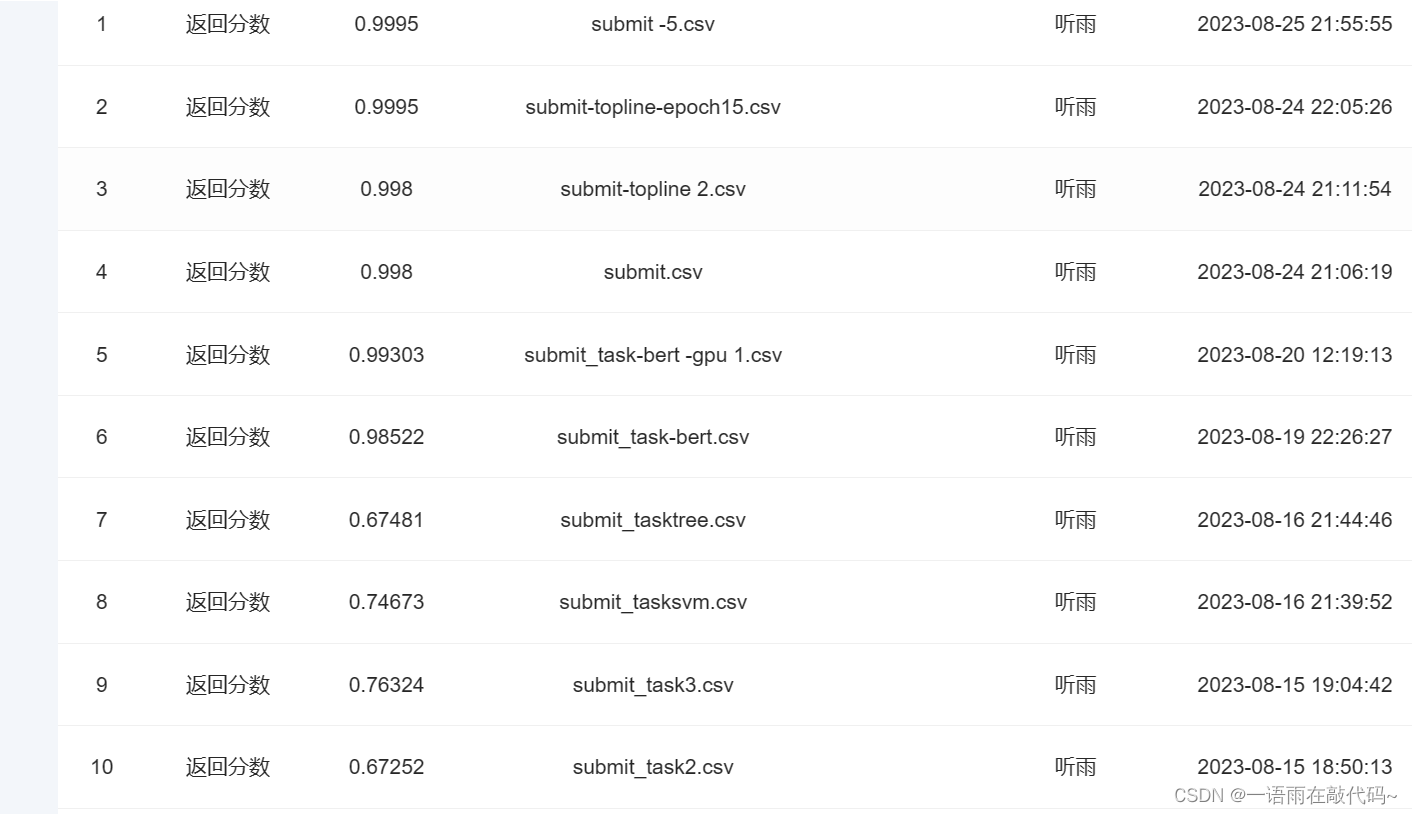
可以看得出来,不同次训练结果是有差异的,但总体来说,增加epoch结果在变好
不过很难得到这个1也是很奇怪了,所以我转战了大模型
3.大模型一开始一堆问题,torch环境不匹配,transformer不匹配,呃,是环境问题,我用的torch1.8
后来改回1.12后就没啥问题了
对了lora权重需要自己训练,我好像来不及了,这警告我们不要把事情拖到ddl,哭死
4.趁着大模型训练的时间,我来写个学习笔记吧
目标1:弄懂训练框架
5.什么是最大序列长度?有什么意义?
MAX_LENGTH = 128 # 定义最大序列长度为128
在我以前的学习中,也遇到过这个问题,那个模型限制tensor是512;我认为这里的最大序列长度是限制最大文本长度,应该是模型训练一次文本,能接受文本的最大长度,不过文本不是会被向量化吗,为什么还会受长度限制?奇怪。
Q2:什么是tokenizer?生成attention向量的过程是标准化过程吗?
众所周知,在NLP任务中,原始文本需要处理成数值型字符才能够被计算机处理,我们熟悉的one-hot编码就是一种转换方式。但这种方式有两个弊端:向量维度太高,且丢失了语义信息。后来人们发明了词向量(或称之为词嵌入,word embedding),它在一定程度了解决了one-hot的上述两个问题。
从「词向量」这个名字上就可以看出,其基本单元是词。因此,要想得到词向量,首先要对句子进行分词,所以,我们需要一个分词工具,简称之为“分词器”。在现代自然语言中,分词器的作用不再是仅仅将句子分成单词,更进一步的,它还需要将单词转化成一个唯一的编码,以便下一步在词向量矩阵中查找其对应的词向量。
分词切分,张量转换,张量填充,保存,我认为应该属于标准化流程
def get_train(model_name, model_dict):
model_index = model_dict[model_name] # 获取模型索引
train = pd.read_csv('./dataset/train.csv') # 从CSV文件中读取训练数据
train['content'] = train['title'] + train['author'] + train['abstract'] # 将标题、作者和摘要拼接为训练内容
tokenizer = AutoTokenizer.from_pretrained(model_name, max_length=MAX_LENGTH, cache_dir=f'./premodels/{model_name}_saved') # 实例化分词器对象
# 通过分词器对训练数据进行分词,并获取输入ID、注意力掩码和标记类型ID(这个可有可无)
input_ids_list, attention_mask_list, token_type_ids_list = [], [], []
y_train = [] # 存储训练数据的标签
for i in tqdm(range(len(train['content']))): # 遍历训练数据
sample = train['content'][i] # 获取样本内容
tokenized = tokenizer(sample, truncation='longest_first') # 分词处理,使用最长优先方式截断
input_ids, attention_mask = tokenized['input_ids'], tokenized['attention_mask'] # 获取输入ID和注意力掩码
input_ids, attention_mask = torch.tensor(input_ids), torch.tensor(attention_mask) # 转换为PyTorch张量
try:
token_type_ids = tokenized['token_type_ids'] # 获取标记类型ID
token_type_ids = torch.tensor(token_type_ids) # 转换为PyTorch张量
except:
token_type_ids = input_ids
input_ids_list.append(input_ids) # 将输入ID添加到列表中
attention_mask_list.append(attention_mask) # 将注意力掩码添加到列表中
token_type_ids_list.append(token_type_ids) # 将标记类型ID添加到列表中
y_train.append(train['label'][i]) # 将训练数据的标签添加到列表中
# 保存
input_ids_tensor = pad_sequence(input_ids_list, batch_first=True, padding_value=0) # 对输入ID进行填充,保证向量中各序列维度的大小一样,生成张量
attention_mask_tensor = pad_sequence(attention_mask_list, batch_first=True, padding_value=0) # 对注意力掩码进行填充,保证向量中各序列维度的大小一样,生成张量
token_type_ids_tensor = pad_sequence(token_type_ids_list, batch_first=True, padding_value=0) # 对标记类型ID进行填充,保证向量中各序列维度的大小一样,生成张量
x_train = torch.stack([input_ids_tensor, attention_mask_tensor, token_type_ids_tensor], dim=1) # 将输入张量堆叠为一个张量
x_train = x_train.numpy() # 转换为NumPy数组
np.save(f'./models_input_files/x_train{model_index}.npy', x_train) # 保存训练数据
y_train = np.array(y_train) # 将标签列表转换为NumPy数组
np.save(f'./models_input_files/y_train{model_index}.npy', y_train) # 保存标签数据
Q3:认识超参数
seed = 42 # 随机种子
batch_size = 16 # 批处理大小
set_epoch = 5 # 训练轮数
early_stop = 5 # 提前停止epoch数
learning_rate = 1e-5 # 学习率
weight_decay = 2e-6 # 权重衰减,L2正则化
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 选择设备,GPU或CPU
gpu_num = 1 # GPU个数
use_BCE = False # 是否使用BCE损失函数
models = ['xlm-roberta-base', 'roberta-base', 'bert-base-uncased',
'microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext', 'dmis-lab/biobert-base-cased-v1.2', 'marieke93/MiniLM-evidence-types',
'microsoft/MiniLM-L12-H384-uncased','cambridgeltl/SapBERT-from-PubMedBERT-fulltext', 'microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract',
'microsoft/BiomedNLP-PubMedBERT-large-uncased-abstract'] # 模型名称列表
model_index = 2 # 根据上面选择使用的模型,这里填对应的模型索引
model_name = models[model_index-1] # 使用的模型名称
continue_train = False # 是否继续训练
show_val = False # 是否显示验证过程
写在最后
其实可以看得出来,从一开始的几行代码到现在的浩大工程,这里面的东西不是一朝一夕能学会的,我在这里挣扎和迷失了很久,由于缺乏有效的学习路径。要感谢datawhale给了我一个重新认识我这一路学习过程的机会,又重新跟随实现了解决方法的不断升级,虽然到现在我还是不能独立使用和构建一个大模型,但是我对于它的知识已经丰富了许多,相信在将来的日子里我能学到更多,不要急躁和焦虑。山水一程,感谢相遇。















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









