









⭐️ 最近参加了由Datawhale主办、联合科大讯飞、阿里云天池发起的 AI夏令营(第三期),我参与了深度学习实践-NLP(自然语言处理)方向 😄
⭐️ 作为NLP小白,我希望能通过本次夏令营的学习实践,对NLP有初步的了解,学习大模型,动手完成NLP项目内容,同时通过社区交流学习,提升调参优化等能力
⭐️ 今天是打卡的第五天! ✊✊✊
⭐️ 按照日程安排,8月19日-22日主要学习深度学习方法,完成任务二,同时尝试跑通大模型Topline。
⭐️ 这两天我继续尝试理解预训练模型相关知识,同时提升分数,跑通深度学习方法Topline。
🚩【NLP】Datawhale-AI夏令营Day1打卡:文本特征提取
第一天学习了Python 数据分析相关的库(pandas和sklearn),文本特征提取的方法(基于TF-IDF提取和基于BOW提取,以及停用词的用法),划分数据集的方法,以及机器学习的模型,并尝试跑通了机器学习方法baseline。
🚩【NLP】Datawhale-AI夏令营Day2打卡:数据分析
第二天学习了数据探索、数据清洗、特征工程、模型训练与验证部分。
🚩【NLP】Datawhale-AI夏令营Day3打卡:Bert模型
第三天学习了Bert模型(预训练+微调范式),并尝试跑通了深度学习方法baseline。
🚩【NLP】Datawhale-AI夏令营Day4打卡:预训练+微调范式
第四天再次学习了预训练+微调范式,Transformer 和 Attention,并跑通深度学习方法baseline。
1. 学习内容
AI夏令营第三期–基于论文摘要的文本分类与关键词抽取挑战赛教程
✅ 预训练模型
✒️ 预训练模型是人工智能发展的重要里程碑。
✒️ 预训练模型(Pretrained Language Model) 指在大规模数据集上进行的无监督学习,通过学习数据中的潜在结构和规律,生成一种通用的语言表示能力。这种语言表示能力可以被用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。使用预训练模型可以使模型在特定任务上的表现更加优秀,同时减少在特定任务上训练模型所需的数据量和计算资源。
✒️ 无监督学习是指在没有任何标记数据的情况下,通过模型自身对输入数据进行分析和学习,从而发现数据中的结构、模式和规律。与有监督学习不同,无监督学习不需要人工标注数据,也不需要预先设定好任务目标,因此它可以处理大规模的数据集。
✒️ 主流的预训练模型:
- BERT(由Google团队提出)
Bidirectional Encoder Representations from Transformers,一种基于Transformer架构的预训练模型,一种双向的Transformer Encoder模型,可以对自然语言文本进行双向编码。BERT通过大规模无标记语料库的预训练,学习到通用的语言表示能力,并在各种下游任务中取得了很好的效果。
BERT主要贡献:
1️⃣ 预训练的有效性:相比设计复杂巧妙的网络结构,Bert在海量无监督数据上预训练得到的BERT语言表示+少量训练数据微调的简单网络模型的实验结果取得了很大的优势。
2️⃣ 网络深度:基于 DNN 语言模型 (NNLM,CBOW等) 获取词向量的表示已经在NLP领域获得很大成功,而 BERT 预训练网络基于 Transformer 的 Encoder,可以做得很深。
3️⃣ 双向语言模型:在 BERT 之前,ELMo 和 GPT 的主要局限在于标准语言模型是单向的,GPT 使用 Transformer 的 Decoder 结构,只考虑了上文的信息。ELMo 从左往右的语言模型和从右往左的语言模型其实是独立开来训练的,共享embedding,将两个方向的 LSTM 拼接并不能真正表示上下文,其本质仍是单向的,且多层 LSTM难训练。
4️⃣ 预训练模型包含多种知识:BERT不但包含上下文知识,还包含句子顺序关系知识。 - RoBERTa (由Facebook团队提出)
Robustly Optimized BERT Pretraining Approach,RoBERTa使用了更大的语料库、更长的训练时间和更多的数据增强方法,从而在各种下游任务中取得了更好的表现。 - ALBERT(由Google团队提出)
A Lite BERT,一种轻量级的预训练模型,与BERT相比具有更高的效率和更小的内存占用。ALBERT通过将BERT中的一些参数压缩或裁剪来达到减小模型大小的目的,从而在各种移动设备和云端环境中得到了广泛应用。 - GPT(由OpenAI团队提出)
Generative Pre-trained Transformer,一种基于Transformer架构的预训练模型,它可以根据输入的上下文生成自然语言文本。GPT通过大规模无标记语料库的预训练,学习到通用的语言生成能力,并在各种下游任务中取得了很好的效果。 - XLNet(由Carnegie Mellon和Google团队提出)
Extended Longitudinal Sequence Model,一种基于LSTM和Transformer相结合的预训练模型,它BERT等预训练模型进行了改进,可以在处理长序列时避免梯度消失或爆炸的问题。XLNet通过双重编码的方式同时学习上下文信息和字面意义,从而在各种自然语言处理任务中表现出色。 - T5(由Google团队提出)
Text-to-Text Transfer Transformer,一种基于Transformer架构的语言模型,旨在通过使用大量数据对模型进行训练,从而能够处理各种文本到文本的自然语言处理任务,如语言转换、摘要生成、问题回答等。T5采用了一个无监督的训练方式,该方式可以从非常庞大的原始文本中提取出有用的信息。T5利用了集成学习的技术,使得模型能够适应多种不同的NLP任务。此外,T5以优化最优推理时间的方式进行训练,从而可以在处理长文本时保持稳定和高效的性能。
✒️ 预训练模型的优势和挑战
优势:
1.更好的泛化能力:预训练模型可以在大规模的数据集上进行训练,从而学习到更通用的语言模式和规律。这使得预训练模型在各种自然语言处理任务中都能够表现出色。
2.更高效的训练:预训练模型通常使用无监督或半监督的学习方法,这比有监督的学习方法更加高效。同时,预训练模型可以利用大规模的数据进行训练,从而减少了对人工标记的需求。
3.可迁移性:预训练模型可以在不同的任务中进行迁移学习,这意味着我们可以将已经预训练好的模型应用到新的任务中,而无需重新训练。
挑战:
1.数据质量问题:预训练模型需要大量的数据来进行训练,但是这些数据的质量往往参差不齐。如果数据质量较差,那么预训练模型的表现也会受到影响。
2.计算资源消耗:预训练模型需要大量的计算资源来进行训练,特别是在生成式任务中。这使得预训练模型的应用范围受到了一定的限制。
3.可解释性问题:预训练模型通常是黑盒模型,难以解释其内部的决策过程。这使得我们难以理解预训练模型的预测结果,并难以对其进行优化和改进。
✅ Baseline方法:预训练微调
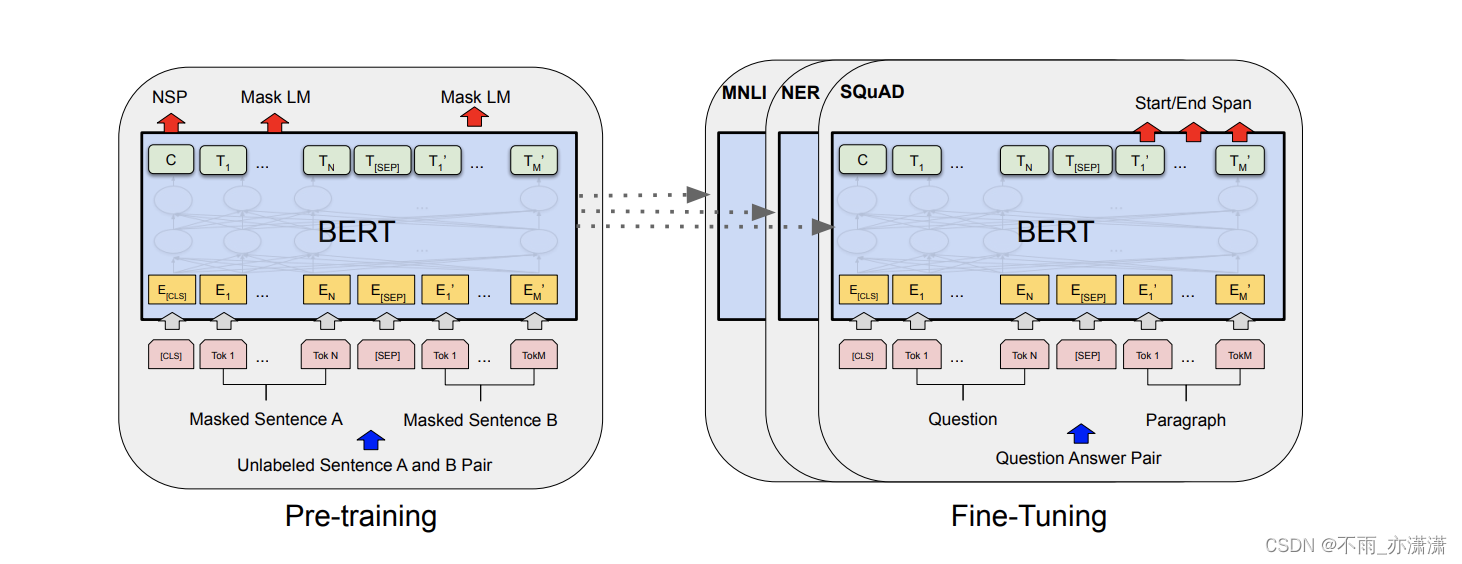
✅ Topline方法:预训练微调+特征融合+后处理
Topline 所使用到的预训练模型为Bert的改进版——Roberta-base。
它与Bert的区别在于:
① Roberta在预训练的阶段中没有对下一句话进行预测(NSP)
② 采用了动态掩码
③ 使用字符级和词级别表征的混合文本编码
与常规的预训练模型接分类器不同,对网络结构进行了更进一步的改进,具体细节如下:
在模型结构上使用了以下两个特征:
①特征1:MeanPooling(768维) -> fc(128维)
②特征2:Last_hidden (768维) -> fc(128维)
其中,特征1指的是将Roberta所输出的全部序列分词的表征向量先进行一个平均池化再接一个全连接层(fc,Fully Connected Layer);特征2指的是将Roberta的pooled_output接一个全连接层(fc,Fully Connected Layer)。(pooled_output = [CLS]的表征向量接入一个全连接层,再输入至Tanh激活函数)
然后,将这两个特征进行加权并相加即可输进分类器进行训练。(在代码中,仅是将它们进行等权相加。后续当然也可以尝试分配不同的权重,看能否获得更好的性能)(Dropout层其实并不是一个必要项,可加可不加~)
最后,将训练好的模型用于推理测试集,并根据标签数目的反馈,对预测阈值进行调整。(后处理)
2. 实践项目
同之前博客介绍的,仍然是任务一,文本分类任务。
【NLP】Datawhale-AI夏令营Day3打卡:Bert模型
3. 实践代码
在代码部分中,主要分为四个模块:
- 数据处理
- 模型训练
- 模型评估
- 测试集推理
完整Topline源码获取可以联系Datawhale官方或者群内助教 💭
4. 遇到的问题和解决方法
问题:
TypeError: ‘RobertaTokenizer’ object is not callable
在本地直接python xx.py跑会遇到这个问题,网上说需要安装transformer大于3.0.0的版本,我试了一下好像还是不行,但是我在Jupter Notebook的虚拟环境下运行没有遇到这个问题(都安装了最新版pytorch)
5. 实践成绩
8.20 Roberta-base模型Topline返回分数:1
8.19凌晨 bert模型Baseline返回分数:0.89562(batch_size=1, epochs = 10)
8.19 bert模型Baselin返回分数:0.99452 (batch_size=8, epochs = 10)
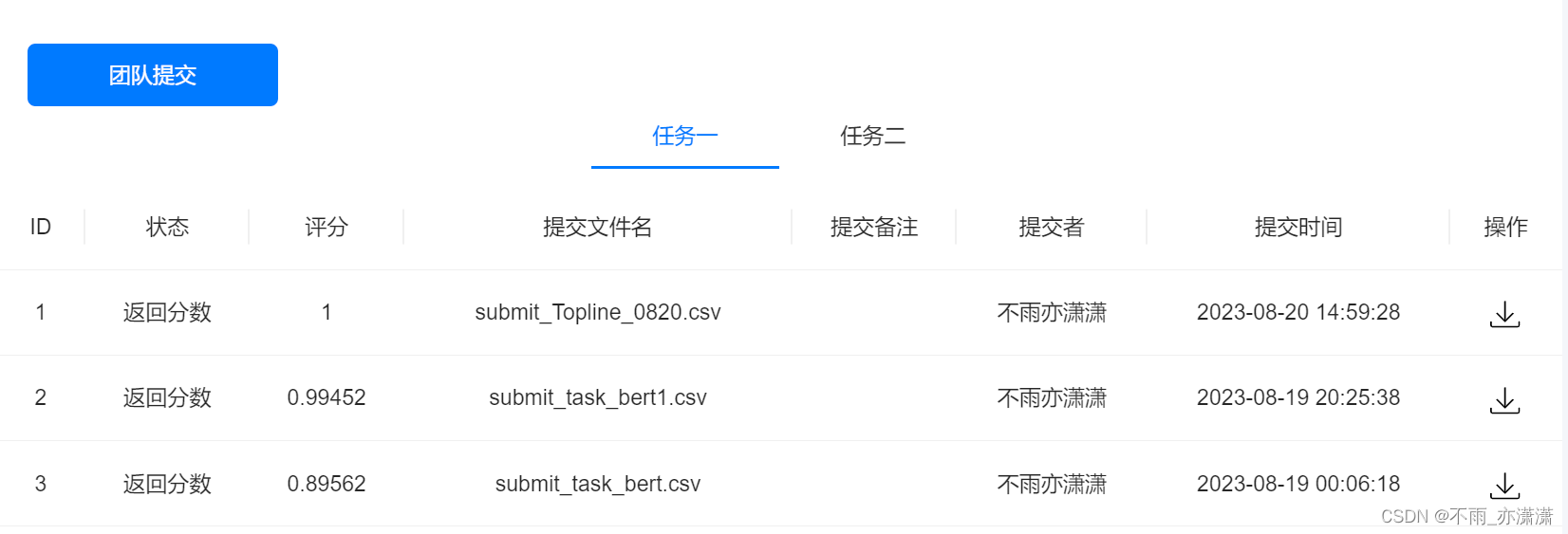
Topline 真的很强大,跑了一次就上1了

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











