一、创建hive数据
1.创建数据库
0: jdbc:hive2://192.168.171.151:10000> create database l0409;
No rows affected (0.162 seconds)
2.创建表
0: jdbc:hive2://192.168.171.151:10000> use l0409;//进入数据库l0409
No rows affected (0.066 seconds)
0: jdbc:hive2://192.168.17.151:10000> create table emp
. . . . . . . . . . . . . . . . . . > (empno int,ename string,job string)
. . . . . . . . . . . . . . . . . . > row format delimited fields
. . . . . . . . . . . . . . . . . . > terminated by ',';
No rows affected (0.204 seconds)
3.创建数据
[root@hadoop dool]# vim emp.txt
7369,SMITH,CLERK
7499,ALLEN,SALESMAN
7521,WARD,SALESMAN
4.导入数据
0: jdbc:hive2://192.168.171.151:10000> load data local inpath "/usr/word/dool/emp.txt"
. . . . . . . . . . . . . . . . . . > into table emp;
No rows affected (0.609 seconds)
二、创建emp实体类
package ch1;
//体现封装思想
//创建emp对应的实体类
public class Emp {
private int empno;
private String ename;
private String job;
public Emp(){}
public Emp(int empno, String ename, String job) {
this.empno = empno;
this.ename = ename;
this.job = job;
}
@Override
public String toString() {
return "Emp{" +
"empno=" + empno +
", ename='" + ename + '\'' +
", job='" + job + '\'' +
'}';
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
}
三、JDBC操作
1. 加载JDBC驱动,获取连接
package ch1;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
//Java调用Hive
public class HiveDemo {
public static void main(String[] args) {
getConnection();
}
//获取连接
public static Connection getConnection(){
//第一步 加载驱动
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//第二步 获取连接
try {
DriverManager.getConnection("jdbc:hive2://192.168.171.151:10000","root","123456");
//输出连接
System.out.println("连接成功");
} catch (SQLException e) {
e.printStackTrace();
System.out.println("连接失败");
}
return null;
}
}
2.查询
//写一个查询emp表的方法
public List<Emp> queryAllEmps(){
//获取连接
Connection connection = getConnection();
String sql = "SELECT empno,ename,job FROM emp";
//新建一个List
ArrayList<Emp> emps = new ArrayList<>();
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
preparedStatement = connection.prepareStatement(sql);
resultSet = preparedStatement.executeQuery();
while (resultSet.next()){
int empno = resultSet.getInt("empno");
String ename = resultSet.getString("ename");
String job = resultSet.getString("job");
Emp emp = new Emp(empno, ename, job);
emps.add(emp);
System.out.println("查询成功");
}
} catch (SQLException e) {
e.printStackTrace();
System.out.println("查询失败");
}finally {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
return emps;
}
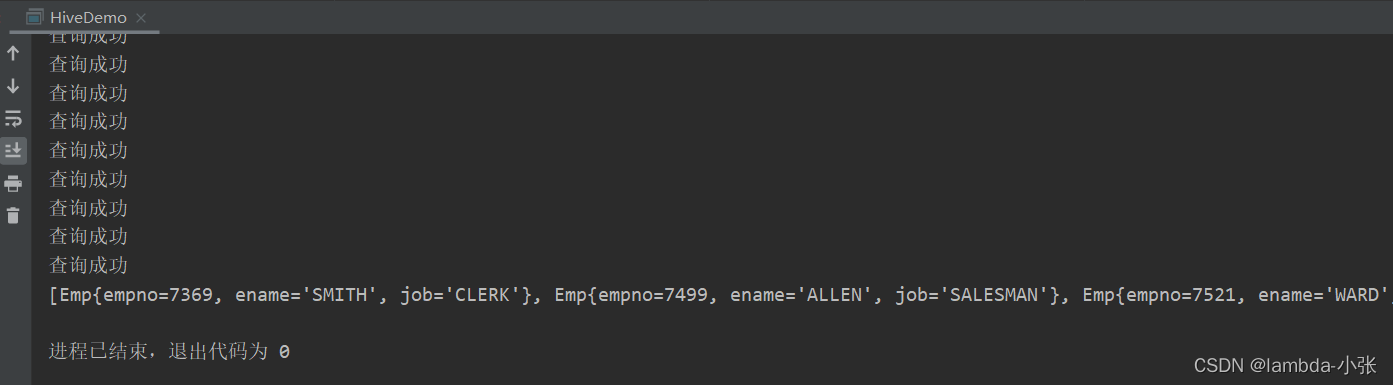
3.运行结果
























 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











