






一、案例介绍
使用Requests和lxml库来爬取美食菜谱网站上的菜谱信息,并将这些数据存储为CSV文件。
二、网站分析
下面是要抓取的网页美食天下。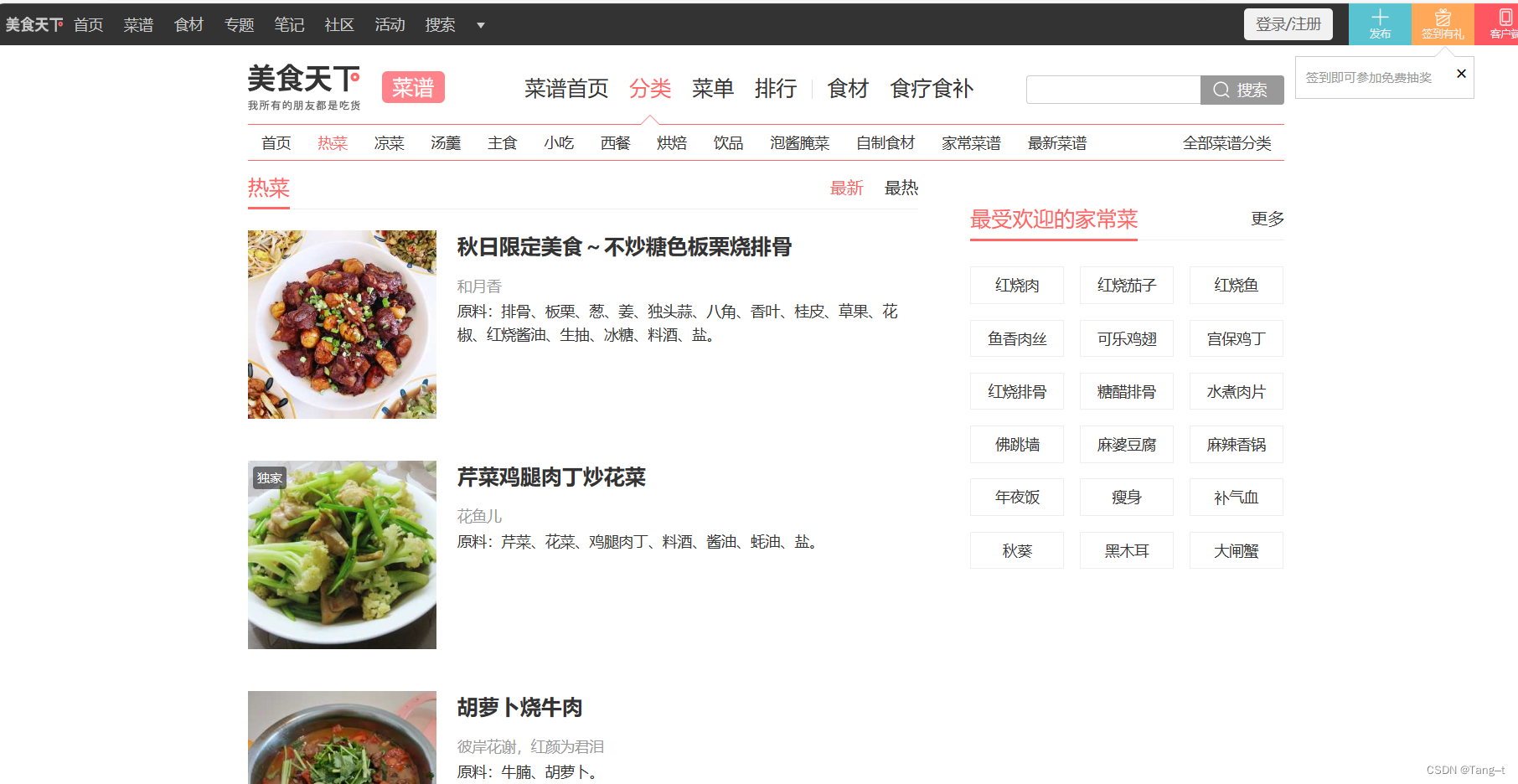
抓取五页,通过观察网页的链接的规律来写循环,使用page 表示当前页数。
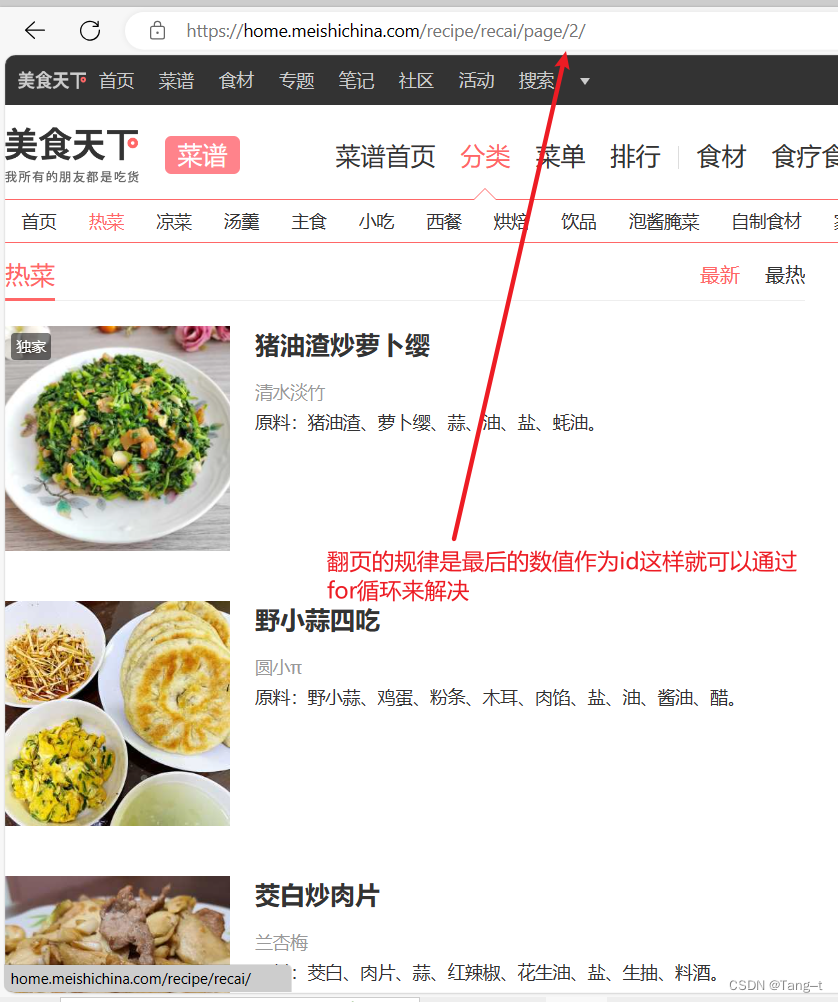
下面点进一种菜,这里涉及到第二个循环,要在每一页循环点击每一个菜品,依次找到菜品名称, 食材用料, 做法所在的位置,首先观察菜名,使用xpth方法锁定a标签里的href即可。

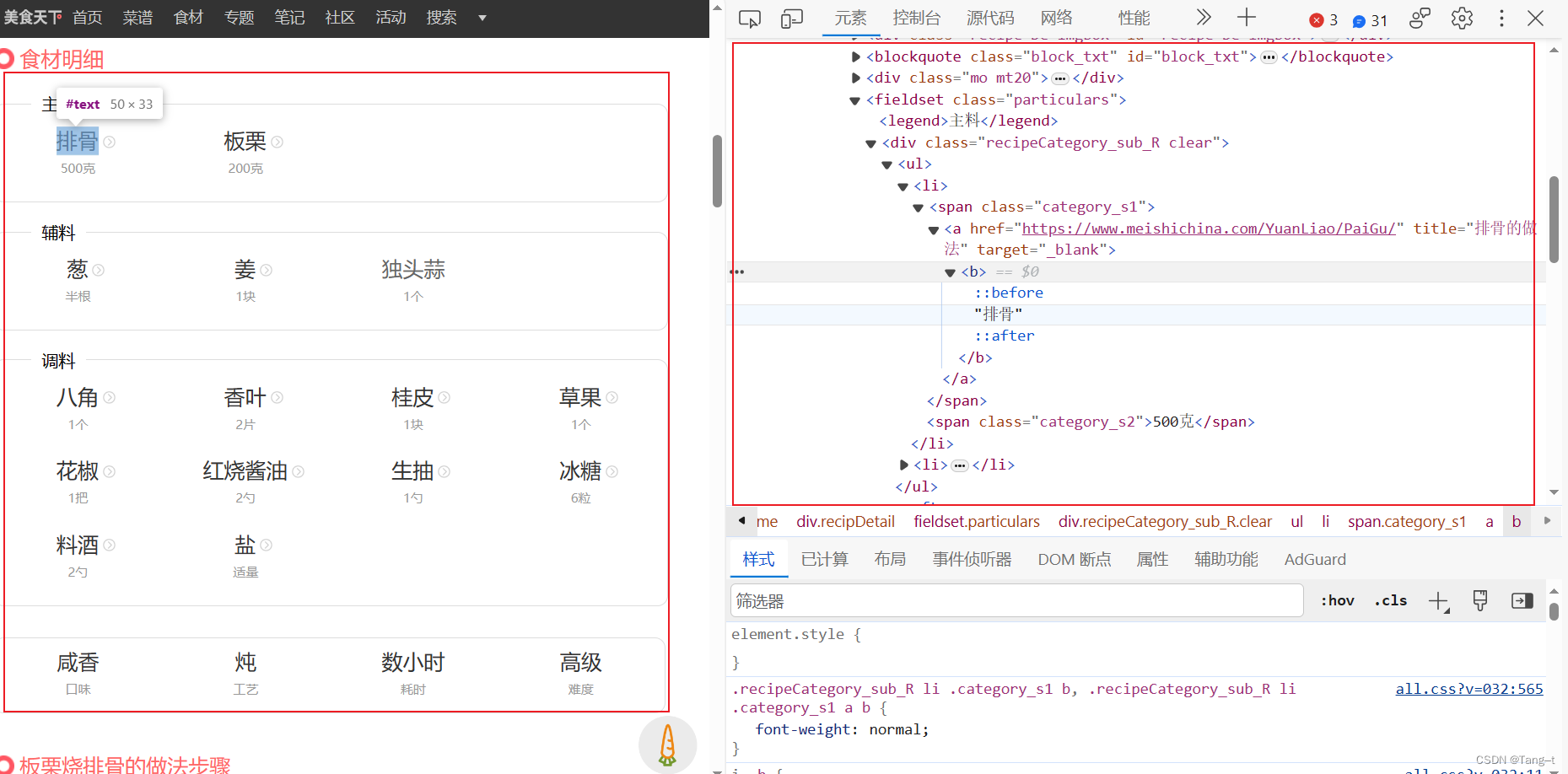
食材原料,先获取所有的食材明细放在列表中,再使用逗号隔开。
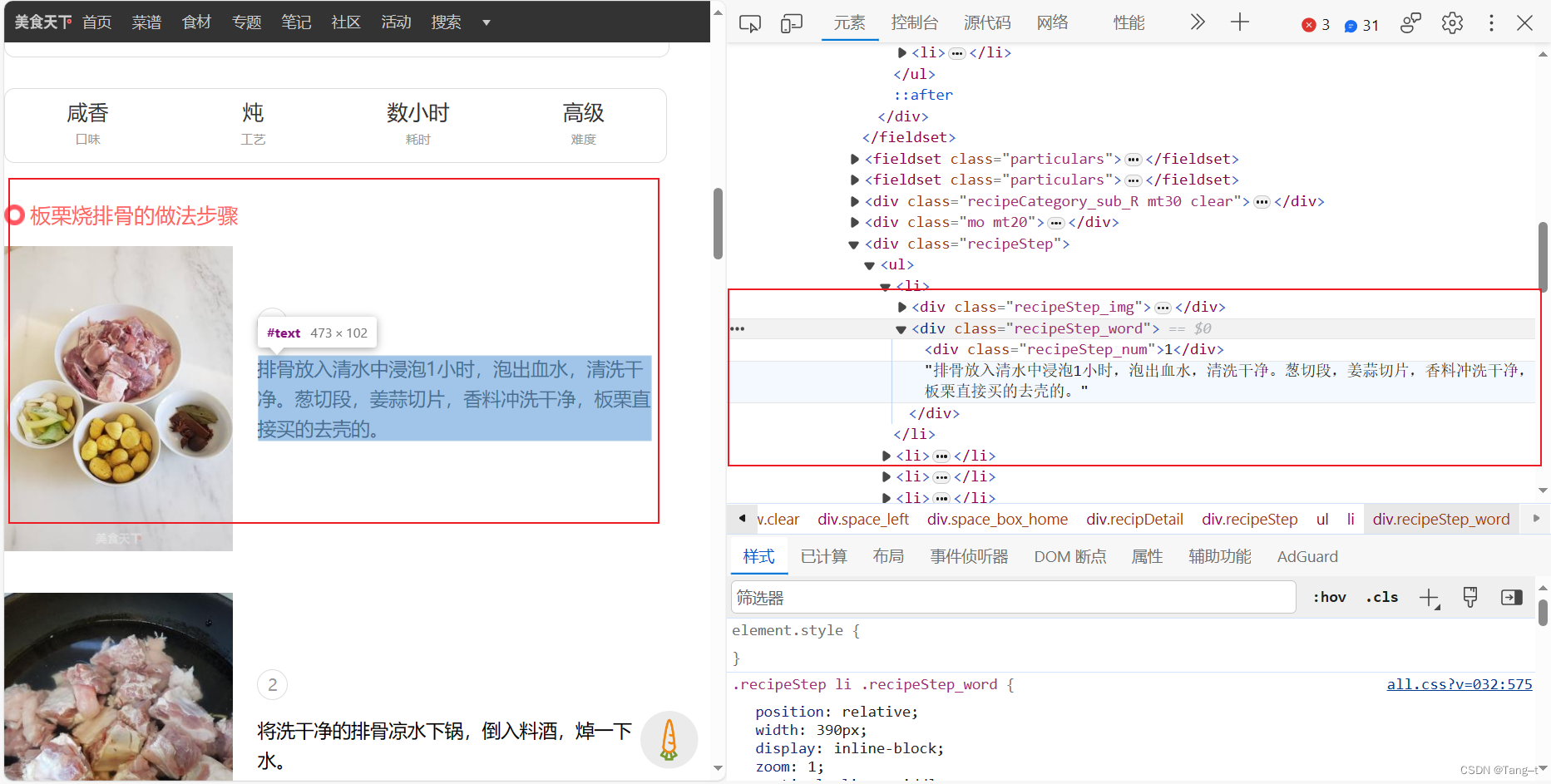
做法使用XPath表达式提取做法步骤,再去除空白。
三、代码实现
代码
import requests
from lxml import etree
import csv
import time
# 设置请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# 存储数据的列表
data = []
# 大循环,爬取前三页
for page in range(1, 4):
url = f"https://home.meishichina.com/recipe/recai/page/{page}/"
response = requests.get(url, headers=headers)
time.sleep(1)
html = etree.HTML(response.content)
# 获取每个菜品的链接
recipe_links = html.xpath('//div[@class="detail"]/h2/a/@href')
# 小循环,进入菜品链接,提取信息
for link in recipe_links:
recipe_response = requests.get(link, headers=headers)
time.sleep(1)
recipe_html = etree.HTML(recipe_response.content)
# 提取菜品名
recipe_name = recipe_html.xpath('//h1[@class="recipe_De_title"]/a/text()')[0]
# 提取食材用料
ingredients = recipe_html.xpath('//fieldset[@class="particulars"]//a/b/text()')
ingredient_name = '、'.join(ingredients)
# 提取做法
steps = recipe_html.xpath('//div[@class="recipeStep_word"]/text()')
cooking_steps = [step.strip() for step in steps if step.strip()]
# 添加数据到列表
data.append({
"菜品名称": recipe_name,
"食材用料": ingredient_name,
"做法": cooking_steps
})
# 将数据存储到CSV文件
with open("recipes.csv", "w", encoding="utf-8-sig", newline="") as file:
writer = csv.DictWriter(file, fieldnames=["菜品名称", "食材用料", "做法"])
writer.writeheader()
writer.writerows(data)抓取结果

















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









