






遍历集合常用foreach 删除多用迭代器
/**
* map里面没有 相关的迭代器
* 三种方式进行遍历
*
* 集合遍历使用for加强循环
*
* 删除集合使用迭代器(不要用集合本身,用迭代器删除)
*/
public class iterator {
public static void main(String[] args) {
Map<Integer, User> map = new HashMap<>();
//先插入数据
for (int i = 0; i < 10; i++) {
map.put(i, new User("zhangsan", 99));
}
//第一种方式
Set<Integer> set = map.keySet();
Iterator<Integer> iterator1 = set.iterator();
while (iterator1.hasNext()) {
Integer key = iterator1.next();
System.out.println(key);
System.out.println(map.get(key));
}
//第二种方式
{
Set<Map.Entry<Integer, User>> entries = map.entrySet();
Iterator<Map.Entry<Integer, User>> iterator2 = entries.iterator();
while (iterator2.hasNext()) {
Map.Entry<Integer, User> Entry = iterator2.next();
System.out.println(Entry.getKey());
System.out.println(Entry.getValue());
}
}
//第三种方式
for (Map.Entry<Integer, User> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
//删除方式
Set<Map.Entry<Integer, User>> entries4 = map.entrySet();
Iterator<Map.Entry<Integer, User>> iterator4 = entries4.iterator();
while (iterator4.hasNext()) {
Map.Entry<Integer, User> next = iterator4.next();
if (next.getValue().getName().equals("zhangsan")) {
iterator4.remove();
}
}
System.out.println(map);
}
}
1、Linkedhashmap
Linkedhashmap在原来的基础上维护了一个双向链表,用来维护,插入的顺序。
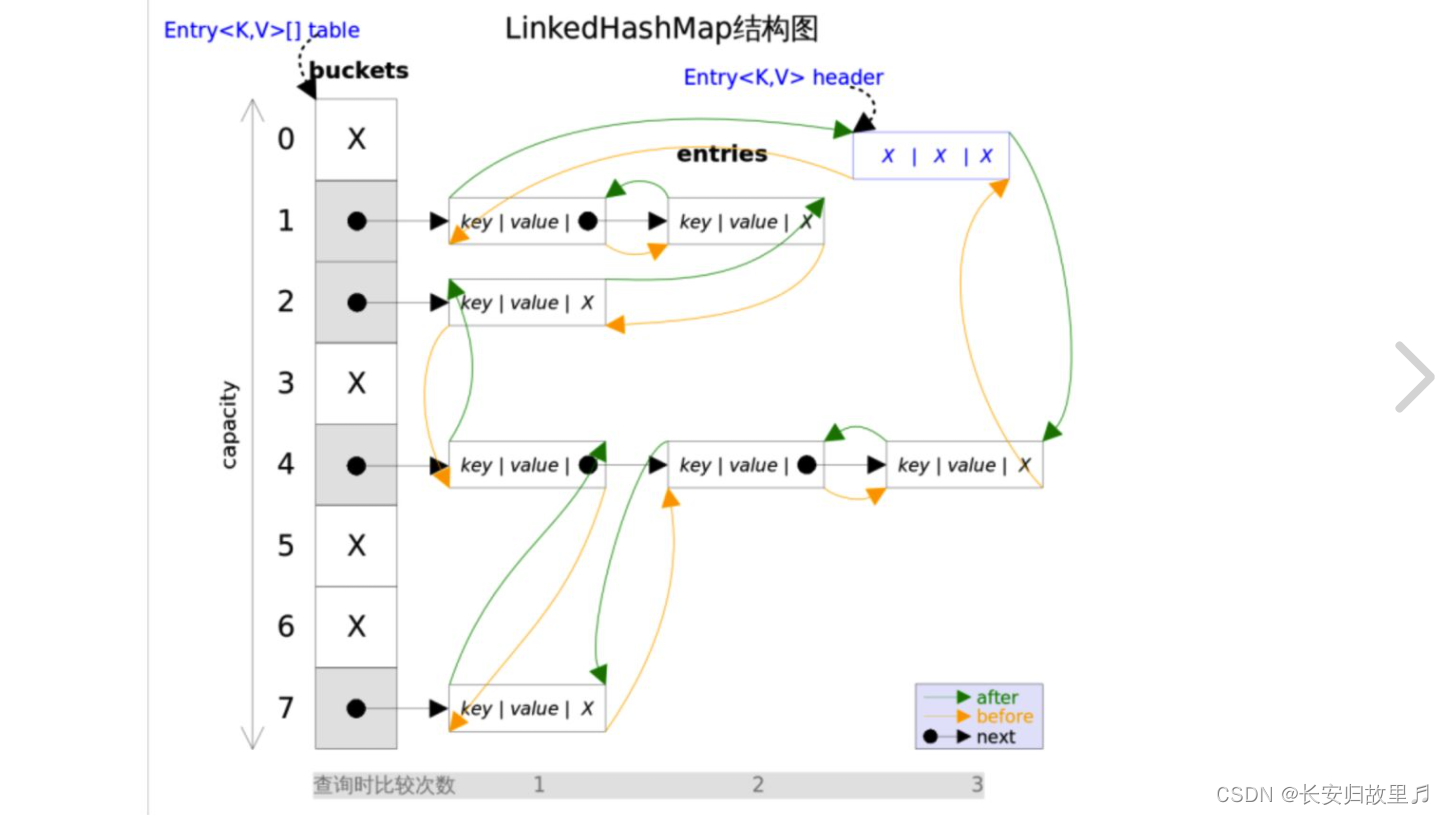
Linkedhashmap默认有序
基于Linkedhashmap的remove算法实现LRU算法
//基于LinkedHashMap的LRU算法 对不满足缓存大小的数据且不经常访问的进行自动删除
public class LRU<k,v> extends LinkedHashMap<k,v> {
public static int maxIncapicity;
public LRU(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LRU() {
super(5, 0.75f, true);
maxIncapicity=8;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size()>=maxIncapicity;
}
public static void main(String[] args) {
Map<String,Integer> objectObjectLRU = new LRU<>(3, 0.75F);
objectObjectLRU.put("a",1);
objectObjectLRU.put("s",2);
objectObjectLRU.put("d",3);
objectObjectLRU.get("d");
objectObjectLRU.put("f",4);
System.out.println(objectObjectLRU);
}
}
2、TreeMap
TreeMap底层实现是红黑树,所以天然支持排序。
两种比较器 ,其实也算是一种CompareTo

public class TreeMapTest {
//TreeMap默认字典序
//LinkedHashMap添加排序
public static void main(String[] args) {
Map<Integer,String> treeMap =new TreeMap<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
treeMap.put(4,"123");
treeMap.put(2,"123");
treeMap.put(1,"123");
treeMap.put(6,"123");
System.out.println(treeMap);
}
}
public class User implements Comparable<User>{
private String name;
private Integer age;
public User() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(User o) {
return this.age-o.age;
}
}
线程安全的
对于线程安全性来讲 list set map任何一个来讲要想删除符合类型的节点
必须遍历,但是自身的remove只是单纯的删除,不能跳转到下一个符合类型的节点。这里以ArrayList源码为例
public E remove(int index) {
rangeCheck(index);
//这里只让游标移动并未按照预期值跳转
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
可用itreator进行删除符合类型的节点
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
//在这里进行了预期值与实际值的转换
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
所以迭代器可以进行元素的删除
但是对于多线程来讲可能拿到的与条件不符
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
两个线程安全古老类list<------>Vector HashMap<------> HashTable
不常用以后会有源码分析
list 1.5倍扩容,list有 CopyOnWriteList自定义或者二倍加锁,map有ConcurrentHashMap
对ConcurrentHashMap分析
ConcurrentHashMapJDK1.8线程抢哈希槽 用自旋锁快速选定失败滚蛋
加重锁对链表进行线程争抢的保护
// 如果没有hash表,就创建一个
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 给f赋值就是hash表中的元素
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 这里也是线程安全的
// 如果没有就使用cas的方式添加
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 看这是关键,这加了锁,f是什么啊?
// f是头节点
synchronized (f) {
............
...........
..........
}
ConcurrentHashMapJDK1.7采用头插导致 扩容时双向链表一直循环Copy cpu内存消耗过大,所以采用了分段锁
调用整体ConcurrentHashMap.put方法根据k值选择对应的Segment.put的方法,它自己调用ReentrantLock 一直尝试自旋锁,最终还是加锁
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 不定的重新抢锁,抢锁的过程当中完成很多初始化的工作
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
// 第一次再次抢锁时顺便初始化了entry
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
// 发现重复的key就不用初识化entry了
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
// 如果超过最大的抢锁的次数直接调用lock
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
ConcurrentHashMapJDK1.8采用尾插 不会再扩容的时候导致链表循环
















 1494
1494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











