






1.数组与树
将数组变成二叉树的结构,能够使得查询速度变得更快( O(n)→O()
在插入过程中,由于要保持树的平衡,因此要通过左旋或右旋来调整插入后树的结构,图示如下:

2.Map
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
Map结构可以简单理解为数学中的函数,即y=f(x):K为自变量不能重复,可以通过散列函数获得结果V,即V=hash(K)。简单来说,map建立了关键字和目标值或地址的一种直接映射关系。Map的查找速度很快,根据接收到的K值能够直接搜索到V值,不需要遍历所有数据;而通过数组结构来查找数据时候,需要遍历所有数据才能找到目标值,最坏情况下整个数组都要查一遍。因此,相比数组查找的时间O(n),map查找的时间O(1)无疑是更快的。
应该注意到,任何设计出来的散列函数都不可能绝对地避免冲突。举例来说,如果设置的散列函数为V=K%7,因此如果K值依次为1,8,15,则获得的V值相同则会储存至同一块地方,为了避免同义词冲突,将会以数组或链表的结构存放。在后续查询时,根据K值搜索仍然会搜索到1区间后,仍然会像数组搜索一样在查找数据,则无疑会使得查询速度下降。
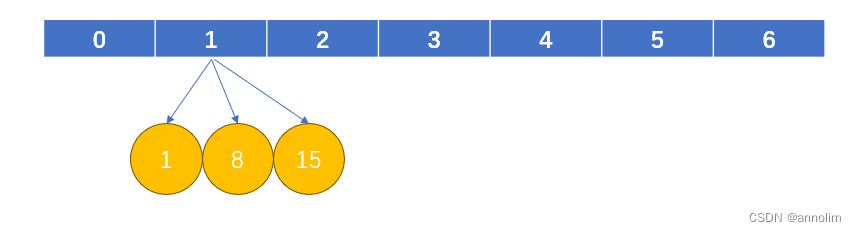
因此,若想使得map查询速度恢复,可以使用的方法为重新确立更优良合理的散列函数,或者在重复区域以树的结构存储等。
3.遍历一个数组查到我们想要的数据,通过用map和直接for循环查找是不一样的。如果我们想要通过遍历一个未知数组和我们已知数据的重复元素,使用map则只需要遍历一遍未知数组,为O(n)的时间复杂度;而若使用for循环,则遍历时则需要遍历一遍未知数组和遍历一遍已知数组,为的时间复杂度。随着数据量增加,后者的时间成本花费越大,这显然是我们不想看到的。因此,为了更快的效率,map的查找方式无疑是更好的。
除了查找优势以外,map在插入和删除方面很快速,但是在查找数组中最值这一方面就很逊色。在寻找最大值最小值时候仍然需要遍历所有数据才能获得所求值,花费的时间和for循环相同,因此在求最值方面map的优势便消失了。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









