







 本文深入探讨核密度估计的基本原理及应用。重点介绍了核密度估计的数学表达式,并解析了一维和高维情况下的核密度估计过程。阐述了核函数的作用及其在机器学习中的重要性。
本文深入探讨核密度估计的基本原理及应用。重点介绍了核密度估计的数学表达式,并解析了一维和高维情况下的核密度估计过程。阐述了核函数的作用及其在机器学习中的重要性。
首先,既然是要来论述核密度估计,那么首先就先上公式。
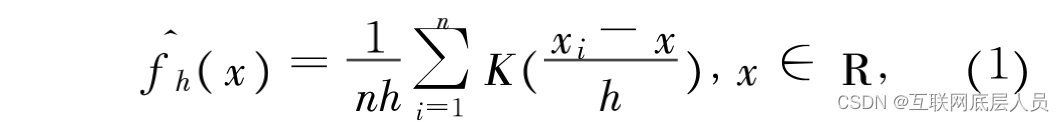
其实这条公式无非讲的就是密度函数 f ( x)的核密度估计,关于这条公式是如何推出来的这里就不做详细的介绍了,但是首先需要明确的一点那就是这只是一条一维公式,很多文章在介绍核密度公式的时候,并没有搞清楚,在机器学习中做各种核密度估计的时候,很多人就是直接代点相减,这样就大错特错了。
好了回到定义,什么是核密度估计呢?这里姑且将xi称为观测点,x称为样本点,网上确实有大量的说法,但是在我看来,核密度估计的想法就是空间中的每一个数据点都会通过密度函数对某一空间造成影响,所以这里可以看到是将每一个点代入与所有的点进行作差而求出来的总和。
简而言之,每一个数据点都会对空间造成影响,而这个空间是由这个数据集构成,当样本点与观测点越近,观测点对附近样本点的影响越大,同样越远则影响越小。
或者换一种说法来说,在一个总体的样本空间中,当你观测到某一点时,那么该点附近的某个区间的影响力也会越大。
在机器学习中,会有大量运用到核密度估计的地方,所以我这里先将高维的核密度公式贴上来。

然后我们来解释一下各个参数的意义。
- K(t)指的是核函数,目前为止常用的核函数特别多,当然如果在做机器学习之前能够事先知道样本的分布的话,选取合适的核函数,会拟合的更加好
- h窗宽
- x这里并不是指样本,而是指某一个x观测点,x1-xd指的是维度,也就是样本的特征值
tips:对于核函数来说,高维的核函数,是需要连乘,得到高维的核
h窗宽,是一个矩阵,实际中,我们需要根据每一维度的值而取窗宽,但是在大量的案例中,大部分都是取同窗宽,也让我一开始疏忽了窗宽的取值。
至此,我想大家应该都明白了,在计算高维核密度估计时,我们首先要做的就是先连乘求出高维的核函数,然后将每一维度的特征值进行估计连乘,就这样将每一个点对观测点的影响值算出来,然后进行求和,计算复杂度还是比较高的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









