







由于需求要实现Denclue算法,在网上查阅了算法的大量资料,我居然发现竟然没有什么人可以把Denclue算法讲明白,要么就是泛泛而谈几行简单的阐述,对于新手来说细节才是最重要的。而对于KDE核密度估计更是如此,在实现算法的初期由于对核密度公式不够理解代入了错误的参数导致Denclue算法最核心的密度无法计算或者计算失误。
好了回归聚类算法,在机器学习中,聚类算法有很多入门的自然便是K-means算法(K均值算法)。下面详细说一下K-means算法的计算步骤。
- 首先在给定的数据集中随机选取三个质心。
- 计算每一个点到三个质心的距离,然后选取距离最近的质心关联,形成一个簇
- 将已经形成的一个簇里面的所有点进行求均值,通常对于二维数据来说就是对x和y进行求 平均值然后形成新的质心。
- 不断重复2和3步骤,直到收敛
tips:除了第一轮的质心是实际存在的点,后面的质心实际上都是不存在的,也就是说第一轮计算平均值是挖掉质心(n-1)个点,而后面的步骤是包含了n个点。
虽然算法发展到现在已经有了很多的优化方法,包括Cnopy,kemans++,二分kmeans等等非常多的方法,但是不管怎么优化始终有一个问题就是参数取值,所有的优化方法都是对kmeans第一轮如何取质心进行优化,在大数据环境下(分布式机器学习)一个好的开始可以比原方法更快,快几倍甚至十几倍。但是仍然无法避免这个问题。当然最致命的问题便是K-means在识别某些分布上确实有很大的问题和k的取值,下面举例说明。
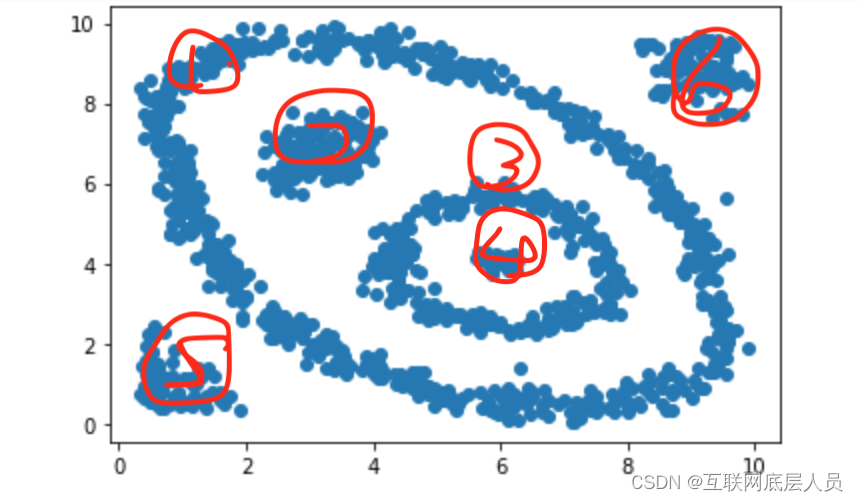
在如上这个分布里,我相信大家自然可以看出来哪些是一个簇的,我在上面用数字标出来了,假设我们在这里使用k-means算法,用上帝视角来看,我们就将k设为6个簇,当然实际生产环节中,k也是我们需要取值的由此看来我们的限制很大,回到算法中我们很轻易就会想到根据x和y的平均值我们可以想象1号位的大圆将被分成好几份,而2号位,4号位,5号位和6号位是正态分布的可以轻松的聚类,1号位和3号类就会被切割成好几份。
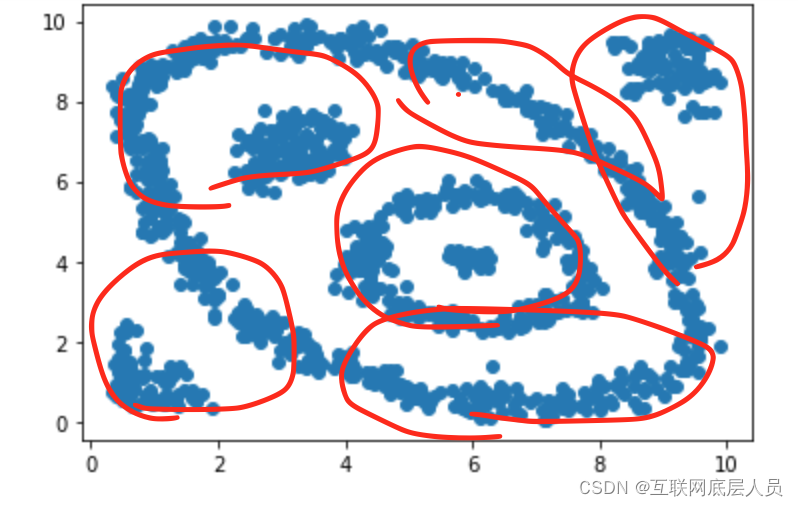
最后应该会变成这样。而实际用Denclue算法聚类的效果图为下。
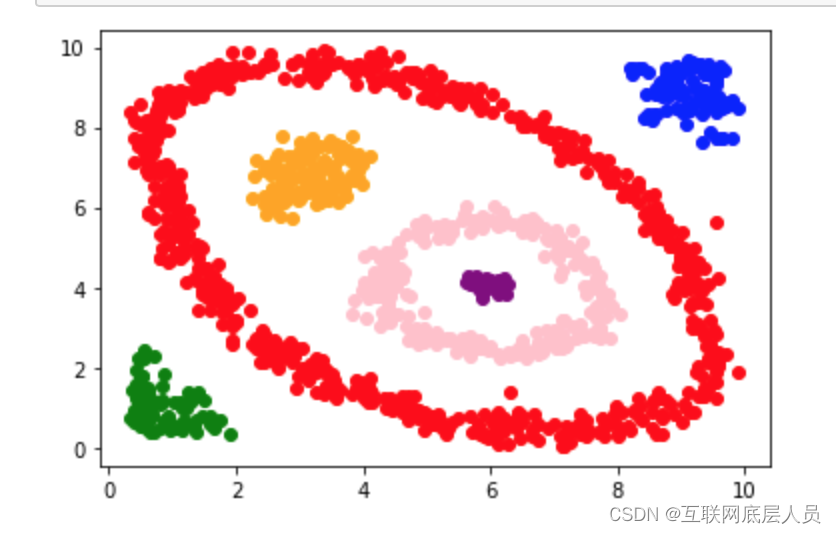
言归正传,Denclue算法。
核心思想是每一个空间数据点通过影响函数事先对空间产生影响,影响值可以叠加,从而
在空间形成一曲面,曲面的局部极大值点为一聚类吸引子,该吸引子的吸引域形成一类。需要几个点来解释一下上面这段思想。
- 影响函数:这里指的是KDE核密度估计
- 核密度估计(KDE):

- 吸引子:也就是K-means算法中的质心
tips:在查阅了大量资料时,我发现大家对核密度公式本身就存在极大曲解,首先h不是一个定值,也不是多个定值,而是一个向量,对于每一个特征值会有特定的窗宽存在,而窗宽如何取当然取决于数据集本身。下一期会对核密度估计来详细的解说,这里还是继续将Denclue算法说完。
下面来说一下Denclue算法的详细步骤:
1.首先还是使用核密度估计推导这个点的密度值,这一步需要参照核密度估计公式,是每一个点和剩下的所有点(特征值)进行推算,参照上面的公式。
2.使用爬山法(梯度上升法),寻找出局部密度最大值参照下图的公式
而梯度公式为下图(在这里我们就可以想象,假设某两个点是一个簇的,那么经过梯度上升法那么它们经过爬山法之后点的距离会更加近,就如同一个山坡,不管是同一坡还是对立坡,经过梯度上升法之后,两点的欧氏距离就会变得更加近,当然假设两个点不属于同一个簇,那么它们会背对背而行,经过给定次数的梯度上升法之后,我们将两点距离的大小求出来若小于收敛速度我们则认为它们是一个簇)而爬山法计算出来的点实则是不存在的,所以关联为一个簇的实际上还是原来的数据点,请不要搞混淆了,由于第一步我们计算出过所有点的密度值,在每一个簇中密度最大的点就是这个簇的质心。
3.经过爬山法确定后的簇是非常多的,如同上图两个同心圆一共有27个簇,在经过爬山法确定簇是远远不够的,这一部也是区分聚类效果好坏的关键一步就是合并簇,我们需要找到两个簇之间的点,也就是每一个簇里面密度最小的点,当然两个山峰的山脚下并不是相连的,假如是相连的,那么那一个点到底是属于哪一个簇我们无法确定。所以我们需要找到两个簇之间距离足够小的点,且那两个点的密度值都大于我们给定的阈值,那么我们将两个簇合并。

在上图我们看到D和E两个簇之间的点事大于密度阈值的(也就是说两个簇之间的点还是有很多点的),所以可以合并为一个簇,而A和B因为之间的点事小于阈值的,这说明两个簇之间的点很少。
4.第四步
就是画图了,因为一开始计算过密度值,假设在爬山法中由于没有与其他的点合并成一个簇,那么此点的密度值就一定是小于阈值的,我们只需要判断密度大小,然后依次画图就可以了,当然那些噪声点一般是一个点为一个簇,在上一步判断中,就可以轻易的排除掉。
下一篇博客会详细介绍如何使用核密度估计公式来计算密度,学生党创作,感谢各位大佬观看,如有错误,请指出。

















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









