







lib文件和dll文件的作用
(1)lib是编译时需要的,dll是运行时需要的。
如果要完成源代码的编译,有lib就够了。
如果也使动态连接的程序运行起来,有dll就够了。
在开发和调试阶段,当然最好都有。
(2)一般的动态库程序有lib文件和dll文件。lib文件是必须在编译期就连接到应用程序中的,而dll文件是运行期才会被调用的。如果有dll文件,那么对应的lib文件一般是一些索引信息,具体的实现在dll文件中。如果只有lib文件,那么这个lib文件是静态编译出来的,索引和实现都在其中。
静态编译的lib文件优点: 给用户安装时就不需要再挂动态库了。但也有缺点,就是导致应用程序比较大,而且失去了动态库的灵活性,在版本升级时,同时要发布新的应用程序才行。
(3)在动态库的情况下,有两个文件,一个是引入库(.LIB)文件,一个是DLL文件,引入库文件.LIB包含被DLL导出的函数的名称和位置,DLL包含实际的函数和数据,应用程序使用LIB文件链接到所需要使用的DLL文件,LIB中的函数和数据并不复制到可执行文件中,因此在应用程序的可执行文件中,存放的不是被调用的函数代码,而是DLL中所要调用的函数的内存地址,这样当一个或多个应用程序运行是再把程序代码和被调用的函数代码链接起来,从而节省了内存资源。从上面的说明可以看出,DLL和.LIB文件必须随应用程序一起发行,否则应用程序将会产生错误。
(4)也可以只有lib文件,这样的话,库中的库中的函数和数据也都要写入lib文件中,同时也会在链接阶段合并到exe中,这样做的坏处是使exe很大,就是去了“库”的意义了,因此不建议这么做。
dll和lib的优缺点
1 静态链接库lib的优点
(1) 代码装载速度快,执行速度略比动态链接库快;
(2) 只需保证在开发者的计算机中有正确的.LIB文件,在以二进制形式发布程序时不需考虑在用户的计算机上.LIB文件是否存在及版本问题,可避免DLL地狱等问题。
2 动态链接库dll的优点
(1) 更加节省内存并减少页面交换;
(2) DLL文件与EXE文件独立,只要输出接口不变(即名称、参数、返回值类型和调用约定不变),更换DLL文件不会对EXE文件造成任何影响,因而极大地提高了可维护性和可扩展性;
(3) 不同编程语言编写的程序只要按照函数调用约定就可以调用同一个DLL函数;
(4)适用于大规模的软件开发,使开发过程独立、耦合度小,便于不同开发者和开发组织之间进行开发和测试。
使用动态链接代替静态链接优点:DLL 节省内存,减少交换操作,节省磁盘空间,更易于升级,提供售后支持,提供扩展 MFC 库类的机制,支持多语言程序,并使国际版本的创建轻松完成。
VS2019 编译YOLOv5的dll和lib
一、生成dllmain.cpp ,framework.h,pch.h 文件(也可以复制别人的)
使用VS2019创建一个新的 dll 动态链接库项目
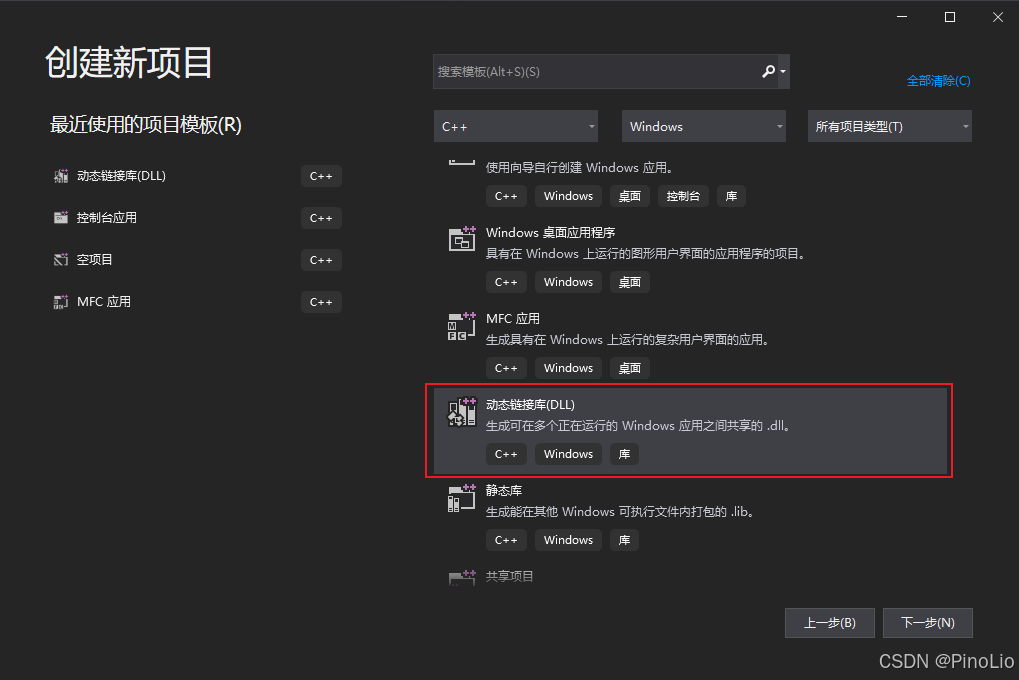
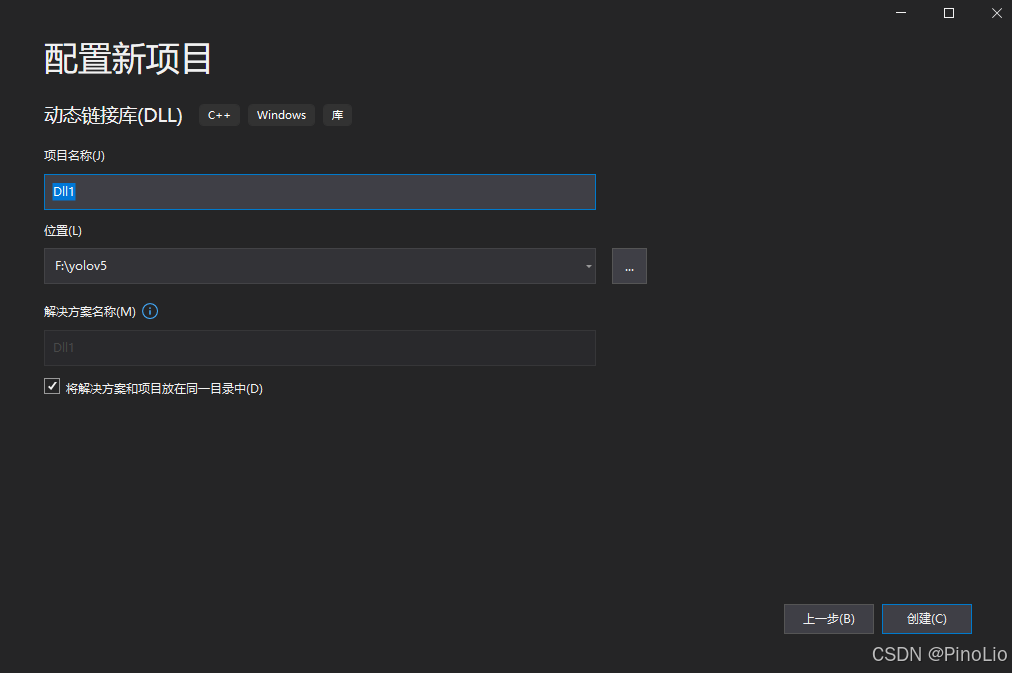
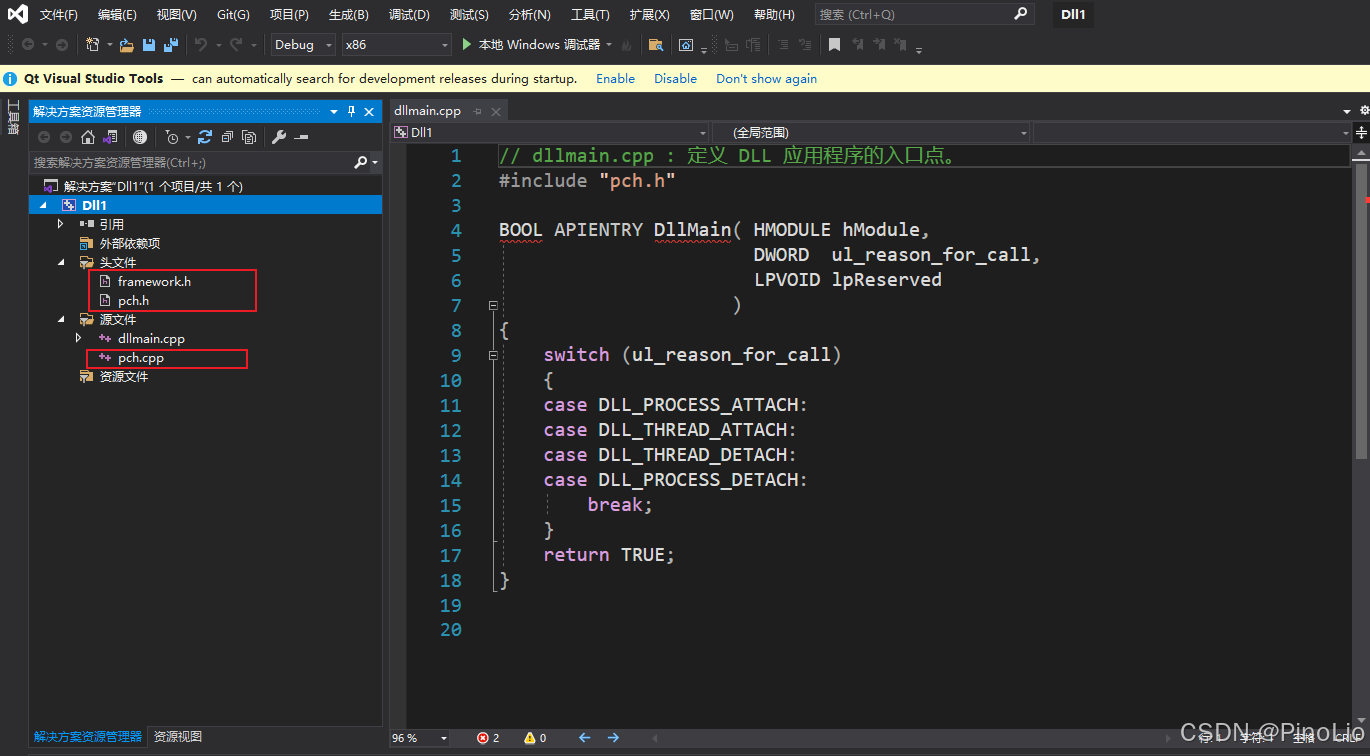
创建完成后得到dllmain.cpp,framework.h,pch.h文件。
二、YOLOv5的lib和dll文件生成
YOLOv5的地址下载链接
1、将如下文件拷贝到新的文件夹中
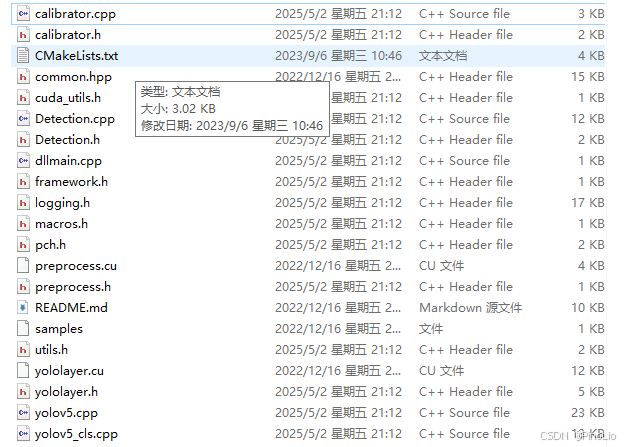
其中需要Detection.cpp和Detection.h文件,如下:
// Detection.cpp
#include "pch.h"
#pragma once
#include "Detection.h"
using namespace std;
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
static Logger gLogger;
static int get_width(int x, float gw, int divisor = 8) {
//return math.ceil(x / divisor) * divisor
if (int(x * gw) % divisor == 0) {
return int(x * gw);
}
return (int(x * gw / divisor) + 1) * divisor;
}
static int get_depth(int x, float gd) {
if (x == 1) {
return 1;
}
else {
return round(x * gd) > 1 ? round(x * gd) : 1;
}
}
ICudaEngine* build_engine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
INetworkDefinition* network = builder->createNetworkV2(0U);
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
assert(data);
std::map<std::string, Weights> weightMap = loadWeights(wts_name);
/* ------ yolov5 backbone------ */
auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");
auto bottleneck_CSP2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");
auto conv3 = convBlock(network, weightMap, *bottleneck_CSP2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");
auto bottleneck_csp4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");
auto conv5 = convBlock(network, weightMap, *bottleneck_csp4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");
auto bottleneck_csp6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");
auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.7");
auto spp8 = SPP(network, weightMap, *conv7->getOutput(0), get_width(1024, gw), get_width(1024, gw), 5, 9, 13, "model.8");
/* ------ yolov5 head ------ */
auto bottleneck_csp9 = C3(network, weightMap, *spp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.9");
auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), get_width(512, gw), 1, 1, 1, "model.10");
auto upsample11 = network->addResize(*conv10->getOutput(0));
assert(upsample11);
upsample11->setResizeMode(ResizeMode::kNEAREST);
upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());
ITensor* inputTensors12[] = { upsample11->getOutput(0), bottleneck_csp6->getOutput(0) };
auto cat12 = network->addConcatenation(inputTensors12, 2);
auto bottleneck_csp13 = C3(network, weightMap, *cat12->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.13");
auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), get_width(256, gw), 1, 1, 1, "model.14");
auto upsample15 = network->addResize(*conv14->getOutput(0));
assert(upsample15);
upsample15->setResizeMode(ResizeMode::kNEAREST);
upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());
ITensor* inputTensors16[] = { upsample15->getOutput(0), bottleneck_csp4->getOutput(0) };
auto cat16 = network->addConcatenation(inputTensors16, 2);
auto bottleneck_csp17 = C3(network, weightMap, *cat16->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.17");
// yolo layer 0
IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);
auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), get_width(256, gw), 3, 2, 1, "model.18");
ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };
auto cat19 = network->addConcatenation(inputTensors19, 2);
auto bottleneck_csp20 = C3(network, weightMap, *cat19->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.20");
//yolo layer 1
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), get_width(512, gw), 3, 2, 1, "model.21");
ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors22, 2);
auto bottleneck_csp23 = C3(network, weightMap, *cat22->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);
std::vector<IConvolutionLayer*> dets = { det0, det1, det2 };
std::string lname = "best20230810";
auto yolo = addYoLoLayer(network, weightMap, lname, dets);
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)
std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);
#endif
std::cout << "Building engine, please wait for a while..." << std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "Build engine successfully!" << std::endl;
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*)(mem.second.values));
}
return engine;
}
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, float& gd, float& gw, std::string& wts_name) {
// Create builder
IBuilder* builder = createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();
// Create model to populate the network, then set the outputs and create an engine
ICudaEngine* engine = build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);
assert(engine != nullptr);
// Serialize the engine
(*modelStream) = engine->serialize();
// Close everything down
engine->destroy();
builder->destroy();
config->destroy();
}
inline void doInference(IExecutionContext& context, cudaStream_t& stream, void** buffers, float* input, float* output, int batchSize) {
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
}
void Detection::Initialize(const char* model_path, int num)
{
if (num < 0 || num>3) {
cout << "=================="
"0, yolov5s"
"1, yolov5m"
"2, yolov5l"
"3, yolov5x" << endl;
return;
}
cout << "Net use :" << yolo_nets[num].netname << endl;
this->gd = yolo_nets[num].gd;
this->gw = yolo_nets[num].gw;
//��ʼ��GPU����
cudaSetDevice(DEVICE);
std::ifstream file(model_path, std::ios::binary);
if (!file.good()) {
std::cerr << "read " << model_path << " error!" << std::endl;
return;
}
file.seekg(0, file.end);
size = file.tellg(); //ͳ��ģ���ֽ�����С
file.seekg(0, file.beg);
trtModelStream = new char[size]; // ����ģ���ֽ�����С�Ŀռ�
assert(trtModelStream);
file.read(trtModelStream, size); // ��ȡ�ֽ�����trtModelStream
file.close();
// prepare input data ------NCHW---------------------
runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
assert(engine->getNbBindings() == 2);
inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
CUDA_CHECK(cudaStreamCreate(&stream));
std::cout << "Engine Initialize successfully!" << endl;
}
void Detection::setClassNum(int num)
{
CLASS_NUM = num;
}
int Detection::Detecting(cv::Mat& img, std::vector<cv::Rect>& Boxes, std::vector<const char*>& ClassLables)
{
if (img.empty()) {
std::cout << "read image failed!" << std::endl;
return -1;
}
if (img.rows < 320 || img.cols < 320) {
std::cout << "img.rows: " << img.rows << "\timg.cols: " << img.cols << std::endl;
std::cout << "image height<640||width<640!" << std::endl;
return -1;
}
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[i] = (float)uc_pixel[2] / 255.0;
data[i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
// Run inference
auto start = std::chrono::system_clock::now();
doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
std::vector<Yolo::Detection> batch_res;
nms(batch_res, &prob[0], CONF_THRESH, NMS_THRESH);
for (size_t j = 0; j < batch_res.size(); j++) {
cv::Rect r = get_rect(img, batch_res[j].bbox);
Boxes.push_back(r);
ClassLables.push_back(classes[(int)batch_res[j].class_id]);
cv::rectangle(img, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
cv::putText(
img,
classes[(int)batch_res[j].class_id],
cv::Point(r.x, r.y - 2),
cv::FONT_HERSHEY_COMPLEX,
1.8,
cv::Scalar(0xFF, 0xFF, 0xFF),
2
);
}
return 0;
}
Detection::Detection() {}
Detection::~Detection()
{
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
}
Connect::Connect()
{}
Connect::~Connect()
{}
YOLOV5* Connect::Create_YOLOV5_Object()
{
return new Detection; //ע��˴�
}
void Connect::Delete_YOLOV5_Object(YOLOV5* _bp)
{
if (_bp)
delete _bp;
}
//Detection.h
#pragma once
// 任何项目上不应定义此符号。这样,源文件中包含此文件的任何其他项目都会将
// YOLOV5_API 函数视为是从 DLL 导入的,而此 DLL 则将用此宏定义的
// 符号视为是被导出的。
#include "pch.h"
#include "yololayer.h"
#include <chrono>
#include "cuda_utils.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"
class CLASS_DECLSPEC Connect
{
public:
Connect();
~Connect();
public:
YOLOV5* Create_YOLOV5_Object();
void Delete_YOLOV5_Object(YOLOV5* _bp);
};
class Detection :public YOLOV5
{
public:
Detection();
~Detection();
void Initialize(const char* model_path, int num);
void setClassNum(int num);
int Detecting(cv::Mat& frame, std::vector<cv::Rect>& Boxes, std::vector<const char*>& ClassLables);
private:
char netname[20] = { 0 };
float gd = 0.0f, gw = 0.0f;
//需要修改的地方:classes
const char* classes[2] = { "brick","aggregate" };
Net_config yolo_nets[4] = {
{0.33, 0.50, "yolov5s"},
{0.67, 0.75, "yolov5m"},
{1.00, 1.00, "yolov5l"},
{1.33, 1.25, "yolov5x"}
};
//需要修改的地方:class_num
int CLASS_NUM = 2;
float data[1 * 3 * 640 * 640];
float prob[1 * 6001];
size_t size = 0;
int inputIndex = 0;
int outputIndex = 0;
char* trtModelStream = nullptr;
void* buffers[2] = { 0 };
nvinfer1::IExecutionContext* context;
cudaStream_t stream;
nvinfer1::IRuntime* runtime;
nvinfer1::ICudaEngine* engine;
};
2、编写Cmake文件并生成
创建CMakeLists.txt,需要添加如下代码:
cmake_minimum_required(VERSION 2.6)
project(yolov5) #1
set(OpenCV_DIR "D:\\Program Files\\opencv\\build") #2
set(OpenCV_INCLUDE_DIRS ${OpenCV_DIR}\\include) #3
set(OpenCV_LIB_DIRS ${OpenCV_DIR}\\x64\\vc15\\lib) #4
set(OpenCV_Debug_LIBS "opencv_world454d.lib") #5
set(OpenCV_Release_LIBS "opencv_world454.lib") #6
set(TRT_DIR "E:\\Tensor_YOLO\\TensorRT-8.4.3.1") #7
set(TRT_INCLUDE_DIRS ${TRT_DIR}\\include) #8
set(TRT_LIB_DIRS ${TRT_DIR}\\lib) #9
set(Dirent_INCLUDE_DIRS "E:\\Tensor_YOLO\\dirent-master\\include") #10
add_definitions(-std=c++11) #需要C++11特性的支持
add_definitions(-DAPI_EXPORTS) #-D 用于指定宏定义的名称
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF) #用于控制编译流程
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(THREADS_PREFER_PTHREAD_FLAG ON)
find_package(Threads) #查找包并返回关于包的细节
# setup CUDA
find_package(CUDA REQUIRED)#cuda需要文件
message(STATUS " libraries: ${CUDA_LIBRARIES}")
message(STATUS " include path: ${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS}) #用于在构建(build)中添加包含目录
####
enable_language(CUDA) # add this line, then no need to setup cuda path in vs
####
include_directories(${PROJECT_SOURCE_DIR}/include) #11
include_directories(${TRT_INCLUDE_DIRS}) #12
link_directories(${TRT_LIB_DIRS}) #13
include_directories(${OpenCV_INCLUDE_DIRS}) #14
link_directories(${OpenCV_LIB_DIRS}) #15
include_directories(${Dirent_INCLUDE_DIRS}) #16
# -D_MWAITXINTRIN_H_INCLUDED for solving error: identifier "__builtin_ia32_mwaitx" is undefined
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -D_MWAITXINTRIN_H_INCLUDED")
find_package(OpenCV QUIET
NO_MODULE
NO_DEFAULT_PATH
NO_CMAKE_PATH
NO_CMAKE_ENVIRONMENT_PATH
NO_SYSTEM_ENVIRONMENT_PATH
NO_CMAKE_PACKAGE_REGISTRY
NO_CMAKE_BUILDS_PATH
NO_CMAKE_SYSTEM_PATH
NO_CMAKE_SYSTEM_PACKAGE_REGISTRY
)
#build_dll
add_library(yolov5 SHARED ${PROJECT_SOURCE_DIR}/common.hpp ${PROJECT_SOURCE_DIR}/yololayer.cu
${PROJECT_SOURCE_DIR}/yololayer.h "Detection.h" "Detection.cpp" "framework.h" "dllmain.cpp""pch.h" )
target_link_libraries(yolov5 "nvinfer" "nvinfer_plugin") #18
target_link_libraries(yolov5 debug ${OpenCV_Debug_LIBS}) #19
target_link_libraries(yolov5 optimized ${OpenCV_Release_LIBS}) #20
target_link_libraries(yolov5 ${CUDA_LIBRARIES}) #21
target_link_libraries(yolov5 Threads::Threads)
打开cmake-gui软件,输入源码路径和编译路径。
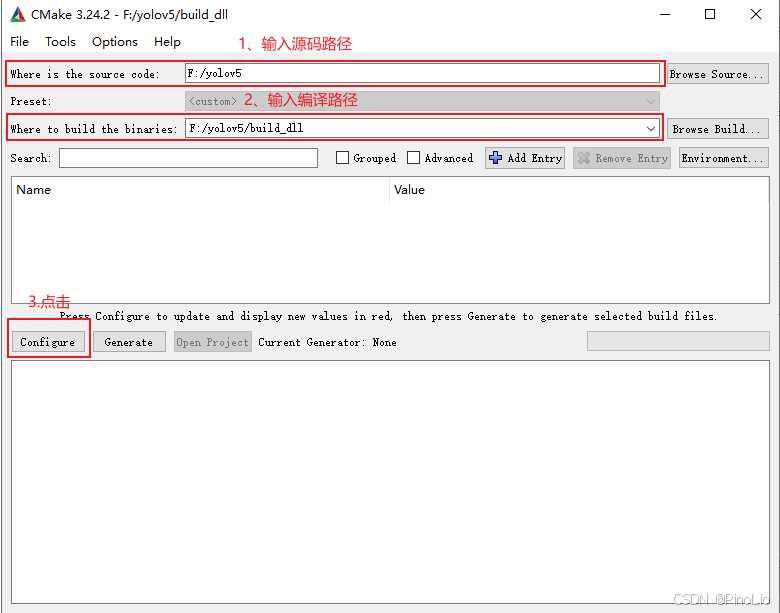
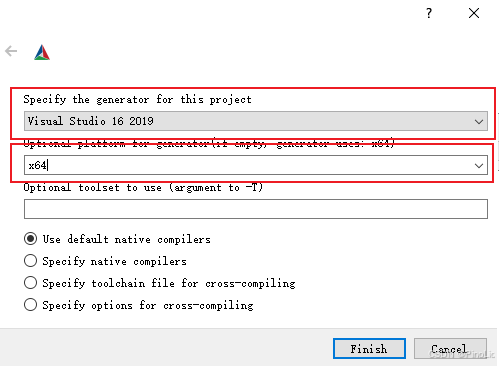
配置完成,如下图所示:
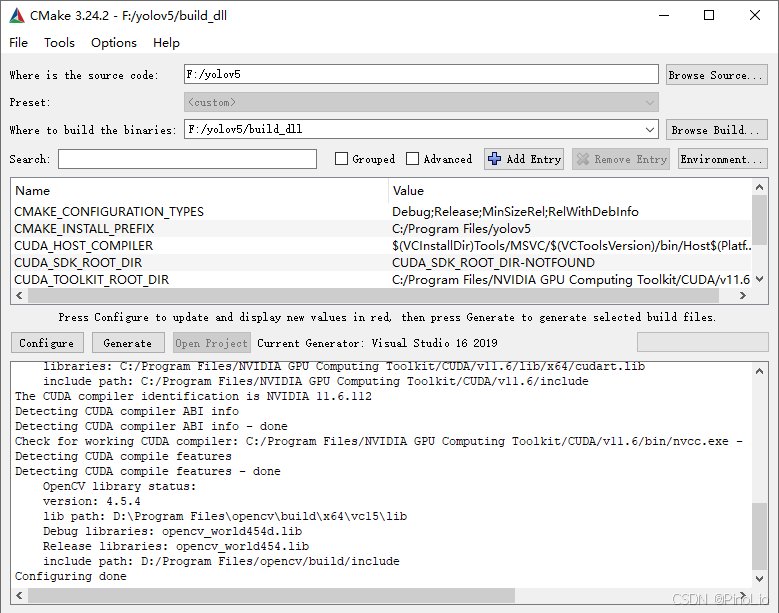
点击Generate生成。在编译路径下有.sln文件,然后打开。
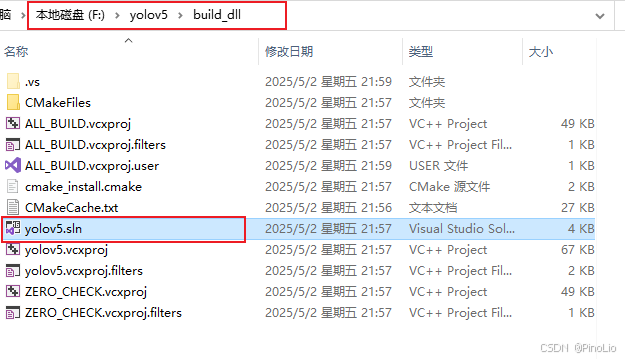
右键重新生成。
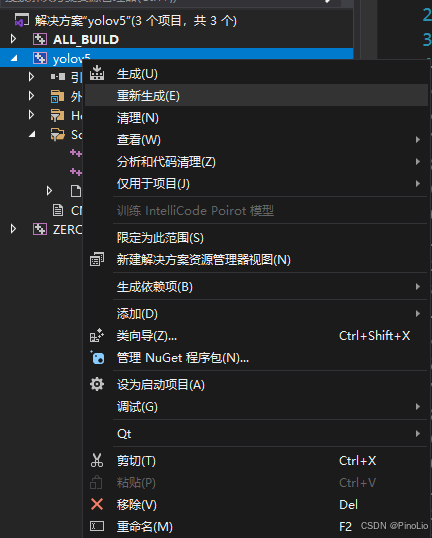
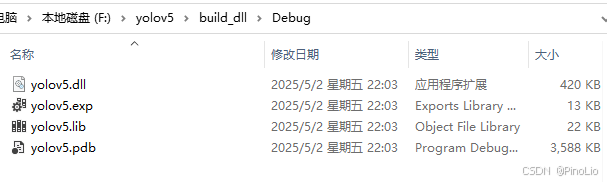
此时,lib和dll文件生成完毕。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









