






项目名称:电商数仓
项目流程图:
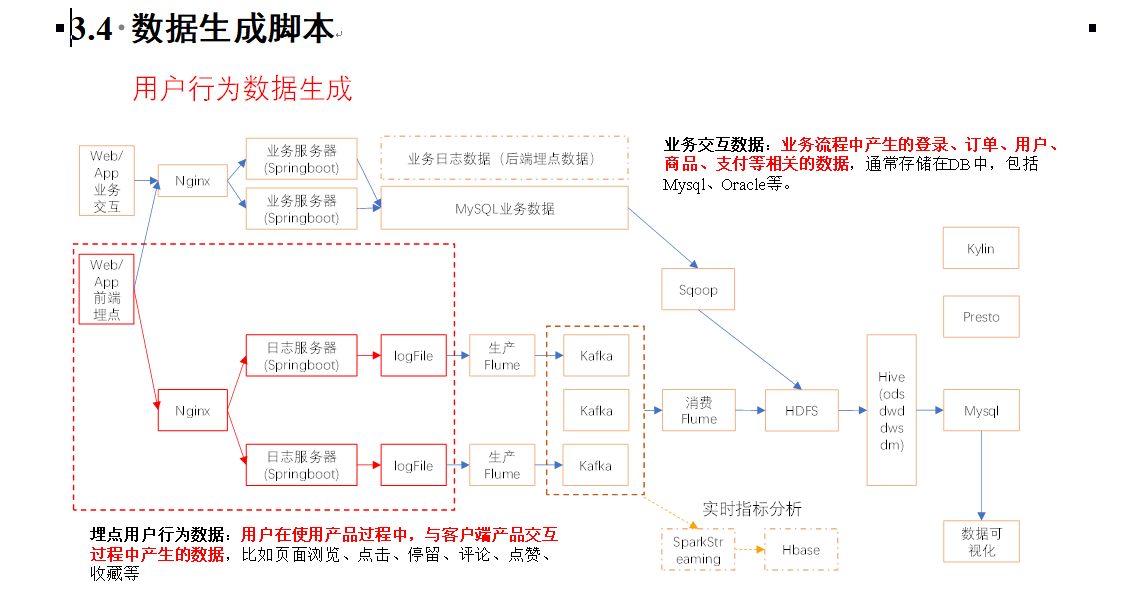
1、首先编写数据生成脚本:
创建maven工程:og-collector
所有脚本编写完成后打成jar包的形式,放到/opt/modules路径下
2、安装Hadoop,并配置相关文件
3、配置zookeeper
4、执行jar程序,可以在/tmp/logs下查看生成的数据(可以在/home/hadoop/bin目录下创建脚本lg.sh,后续直接执行脚本即可)
5、安装flume,自定义了两个拦截器,分别是:ETL拦截器、日志类型区分拦截器
etl拦截器:过滤时间戳不合法和Json数据不完整的日志
日志类型区分拦截器:将启动日志和事件日志区分开来,方便发往Kafka的不同Topic。
同样创建Maven工程:flume-interceptor
5.1、Flume ETL拦截器LogETLInterceptor
5.2、Flume日志过滤工具类LogUtils
5.3、Flume日志类型区分拦截器LogTypeInterceptor
5.4、打包:放入/opt/modules/flume/lib目录下
5.5、可以编写日志采集Flume启动停止脚本,在/home/hadoop/bin目录下创建脚本f1.sh
6、安装kafka
6.1、启动脚本:在/home/hadoop/bin目录下创建脚本kf.sh
6.2、进入到/opt/modules/kafka/目录下分别创建:启动日志主题(topic_start)、事件日志主题(topic_event)
7、日志消费Flume
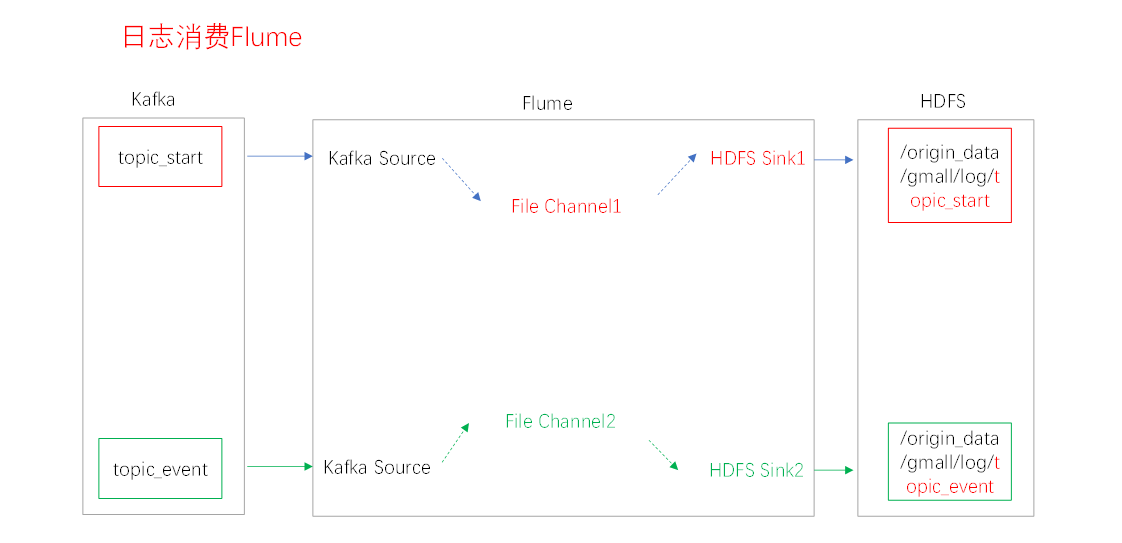
7.1、Flume的具体配置:
/opt/modules/flume/conf目录下创建kafka-flume-hdfs.conf文件
7.2、可以配置日志消费Flume启动停止脚本:在/home/hadoop/bin目录下创建脚本f2.sh
8、数仓分层
8.1、ODS(原始数据层):保持数据原貌不做处理
8.2、DWD(明细数据层):对ODS层数据进行清洗(去除空、脏数据,超过极限范围的数据)
8.3、DWS层(服务数据层):以DWD层为基础,进行轻度汇总
8.4、ADS层(数据应用层):为各种统计报表提供数据
9、数仓环境搭建准备Hive&Mysql
这里配置了Hive的运行引擎为Tez(原因:Tez引擎性能优于MR)
10、开始搭建数仓各层
10.1、ODS层(存放原始数据):
在home/ hadoop /bin目录下创建脚本:vim ods_log.sh
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/opt/modules/hive-sc/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo "===日志日期为 $do_date==="
sql="
load data inpath '/origin_data/gmall/log/topic_start/$do_date' into table "$APP".ods_start_log partition(dt='$do_date');
load data inpath '/origin_data/gmall/log/topic_event/$do_date' into table "$APP".ods_event_log partition(dt='$do_date');
"
$hive -e "$sql"10.2、DWD层(明细数据层):
启动表:
在/home/ hadoop /bin目录下创建脚本:vim dwd_start_log.sh
#!/bin/bash
# 定义变量方便修改
APP=gmall
hive=/opt/module/hive/bin/hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table "$APP".dwd_start_log
PARTITION (dt='$do_date')
select
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
from "$APP".ods_start_log
where dt='$do_date';
"
$hive -e "$sql"基础明细表:明细表用于存储ODS层原始表转换过来的明细数据
需要用到UDF和UDTF。
自定义UDF函数(解析公共字段)
自定义UDTF函数(解析具体事件字段)
打包上传hivefunction-1.0-SNAPSHOT上传到hadoop102的/opt/module/hive/
10.3、DWS层
目标:统计当日、当周、当月活动的每个设备明细
10.4、 ADS层
目标:当日、当周、当月活跃设备数















 3882
3882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









