






AI视频生成领域还有高手?
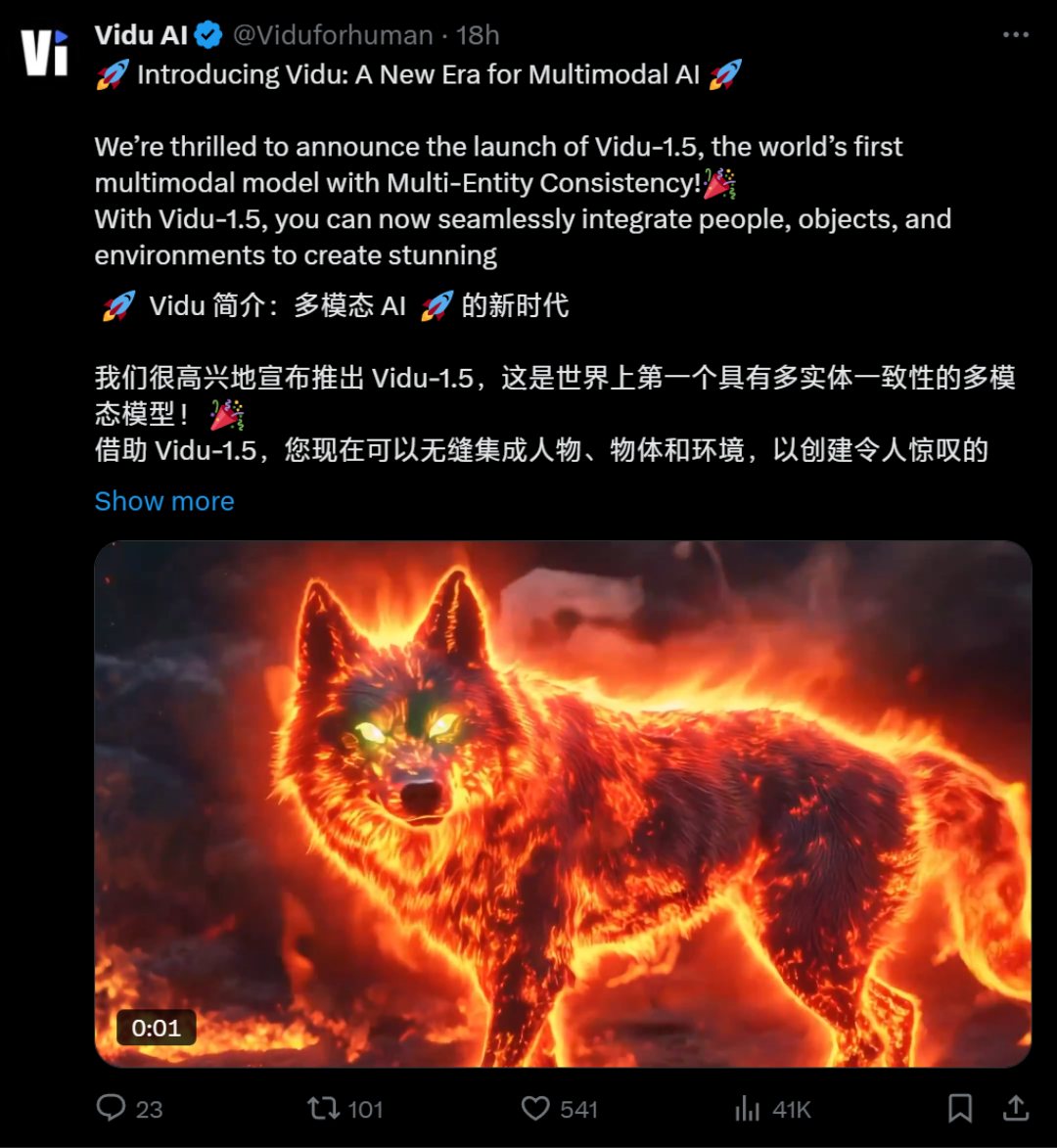
真是离大谱了,全球首个支持多图融合生成的AI视频模型,它来了!
现在,你只需要上传3张参考图,就能将这3张图中的主体融合进一条视频中,这意味着你能够精准控制视频生成的效果了…


这个AI视频模型就是Vidu AI刚发布的Vidu-1.5。
可能大家对Vidu AI有些陌生,它是今年4月份,继Sora之后,国内首个支持长视频、高一致性、高动态性的视频大模型,而它的团队是由清华大学和中国的AI初创公司生数科技联合开发。
但是在后续它的影响力并不如可灵、海螺等一众国产AI视频模型。
直到11月13日,他们正式上线了Vidu-1.5模型,成为全球首个解决“多主体一致性”问题的AI视频模型。
这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

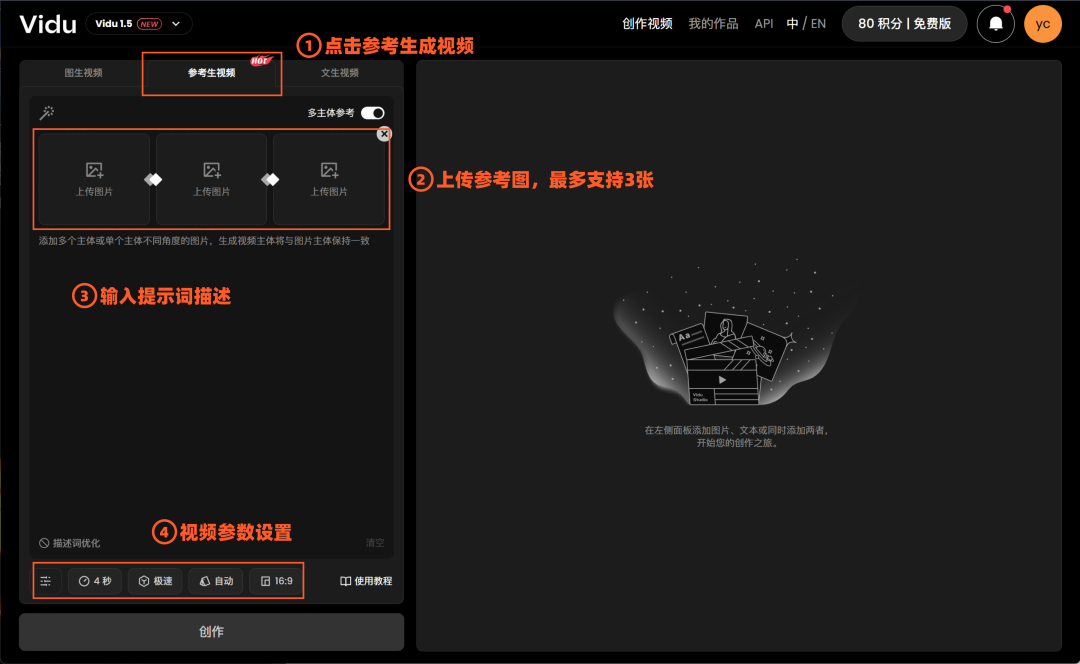
简单来说,这个功能支持上传1-3张参考图,来实现对图片中多主体的交互控制,以及主体与环境的融合控制。
用官方演示的视频为例,上传“黑人小哥、机甲套装、城市街景”这3张图片,Vidu就能自动提取图片中的人物、服装和场景,并将这三中元素无缝融合,生成一段“穿着机甲的黑人小哥,走在夜晚城市街道”的视频。


你可以用它做广告创意片,比如丢给Vidu AI这三张图片,红色的椅子、人物模特、饮料产品,就可以得到一段这样的视频。

你也可以上传人物、服装和T台场景,就能实现模特换装+走秀的视频效果了,我已经能想到这功能在电商行业中的应用场景了,电商领域的工作流又将迎来革新…


不只是真实的人物场景,在三视图的插画场景中,它也能给你搞定人物转身,并且主体非常的准确。
这玩意真的是颠覆性的更新,你以前只能上传一张图片,然后通过提示词来控制视频内容,大部分情况下,一段不错的视频效果是需要反复抽图。
而现在Vidu AI能上传多张图片进行融合,精准的控制多元主体。
真的,AIGC的商业化应用离不开“精准控制”这4个字,很显然,Vidu AI已经往前迈了一大步。
现在,你就可以在Vidu AI体验这个功能,每个账户有3次免费生成机会。
登录Vidu AI官网:https://www.vidu.studio/
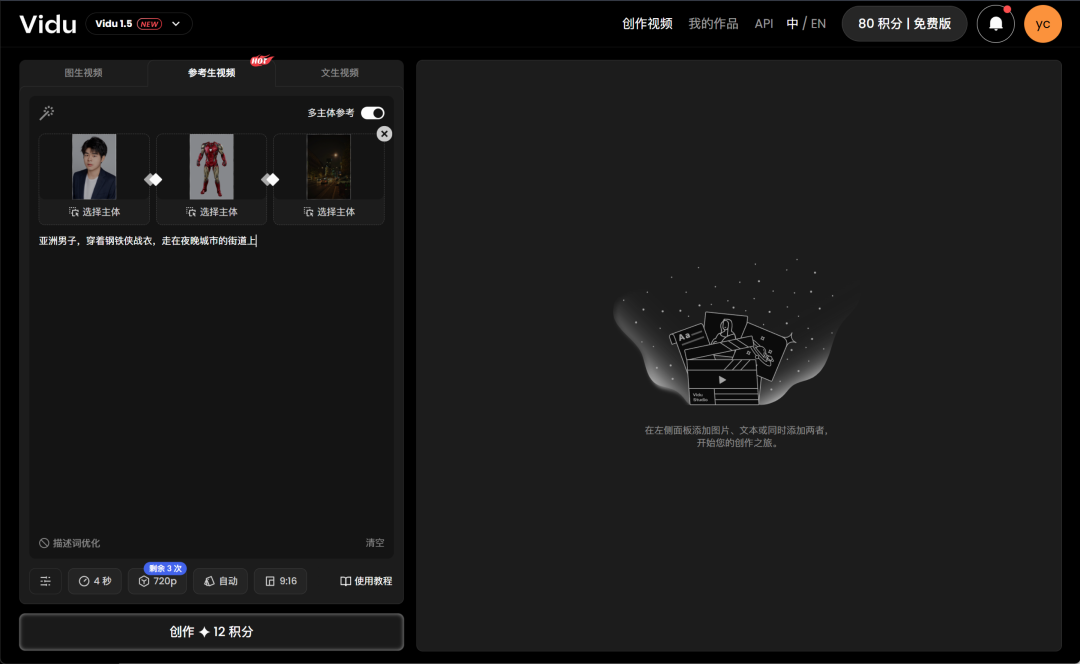
用我在某真蓝拍的人物照玩一下。
我要穿着钢铁侠的战衣,走在夜晚的街道上。那么我就需要准备这3张图,分别是人物原图(面部放大一些)、钢铁侠的战衣(把头部去掉)、夜晚的街景图。

然后提示词可以这样描述:亚洲男子,穿着钢铁侠战衣,走在夜晚城市的街道上。
你别说,这胖脸还真像… 每次长肉先从脸开始,太离谱了。
不知道为什么前面走了一个人,C位都被占了。但是这画面控制的真好啊,可以看看我上传的图片。
我最喜欢的老马,不能错过了!我想看看穿着裙子在沙滩上跳舞的首富,马斯克!提示词:马斯克穿着黑色的裙子,在沙滩上跳舞

好家伙,这衣服“串”了吧,上身西服,下半身裙子,真的抽象。
这次生成的并不准确,要不是没免费次数了,我还得好好调一下。
这里翻车也能看出,该功能目前还未完善,还有优化空间,但是这个技术确实是一个重要的创新。
Vidu 1.5模型是基于多模态学习技术,整合视觉、文本和声音等多种信息源,使AI能理解和处理不同形式的数据。同样也是采用了Diffusion模型和Transformer模型的融合架构。
但这次的“多主体一致性”功能却不是采用主流的LoRA微调方案,因为这一方案通常需要庞大的数据输入和复杂的训练过程,成本高昂且容易导致模型过拟合。
它是基于通用模型能力的提升,通过输入1-3张图片,实现多角度、多主体、多元素的一致性生成。
并且它将LLM模型的上下文学习能力,引入到视频模型中,把所有的问题统一为简单的输入和输出。
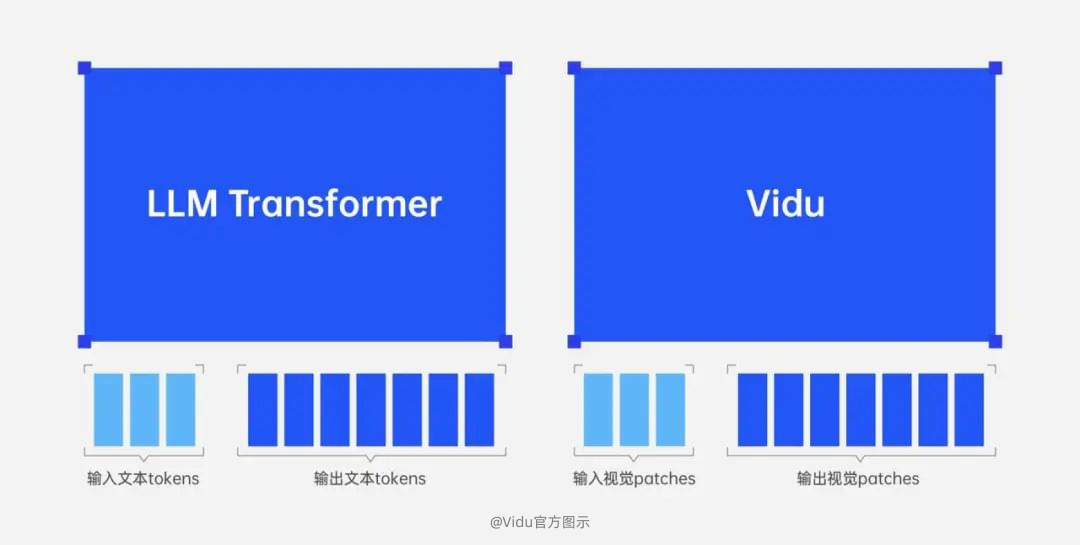
要知道,大语言模型能够理解复杂的指令/问题和长文本信息,并且能连贯的输出符合情景的回答/内容,借助的技术之一就是“上下文学习”能力。
而Vidu 1.5模型现在拥有了这项能力,这意味着曾是大语言模型独有的优势,如今已在视觉模型中得以体现。
这也标志着,视觉模型也如语言模型一样实现了“大跨越”。视觉模型将具备更强的认知能力,而AGI时代正在加速到来…
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









