







前言
关于 AI 辅助电商设计专题已经出过好几期文章了。而模特生成这个话题也不新鲜。那么基于之前的积累,今天也来尝试一下做一下模特,可以根据复刻指定的人物姿势生成套图!使用场景:
-
“”洗“”模特。可以不用拍照而保持模特的一致性。
-
用于电商商品详情页
-
其他用途.🥱
看看效果
流程是这样的。
女娲造人之-生成模特
首先,设置设计好模特的特征。使用肖像大师这个节点,定义。
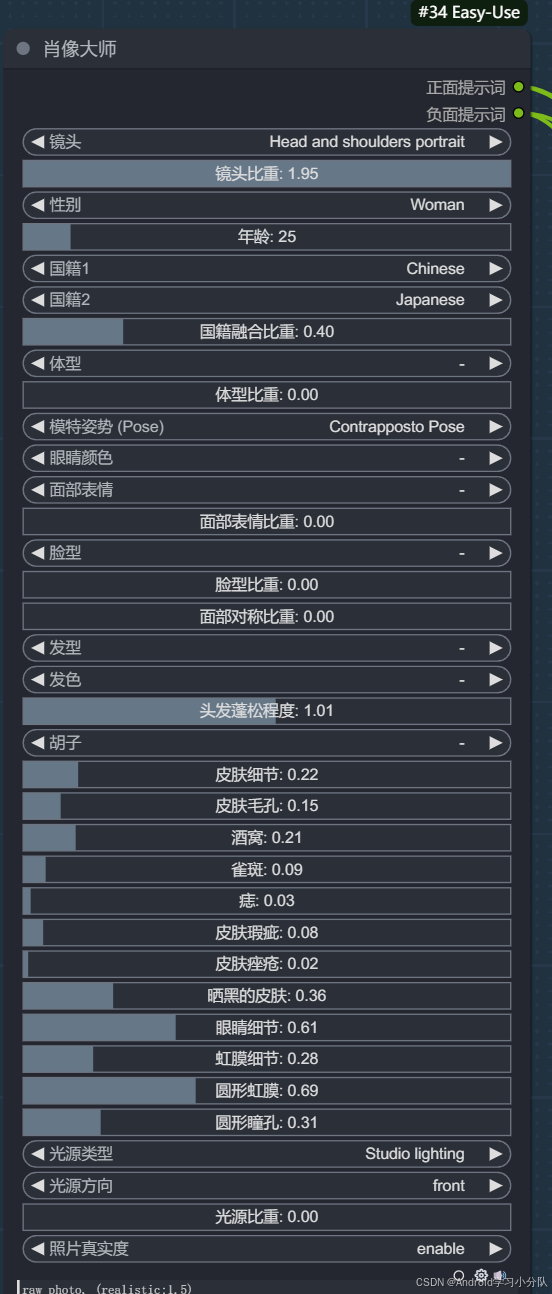
这次选择一个稍微俏皮可爱的模特吧~😂。因为出图足够真实和高清,这样可以大胆地对外说,这是我们公司的御用模特😎。

输入合适的姿势
从网上找一些资源,模特是需要洗掉的,图片不清晰也没关系,我们只需要获得姿势~🥱。

按照姿势出图
这个步骤其实已经完成洗稿了,人物已经替换了,动作也完美复刻,一致性也不错。

最后一步,替换人脸
最后就要变成我们的模特。
头发有点问题,应该要抽卡一张短发的模特的,或者在提示语框定。时间关系,我就不重新跑图了。单张看,也是细节丰富的。

工作流
整个流程,相对之前的一致性换脸这些,会稍显复杂些。

模型加载
Flux fp8 大模型,和AWportrait Lora 模型,擅长中国人审美的 Lora。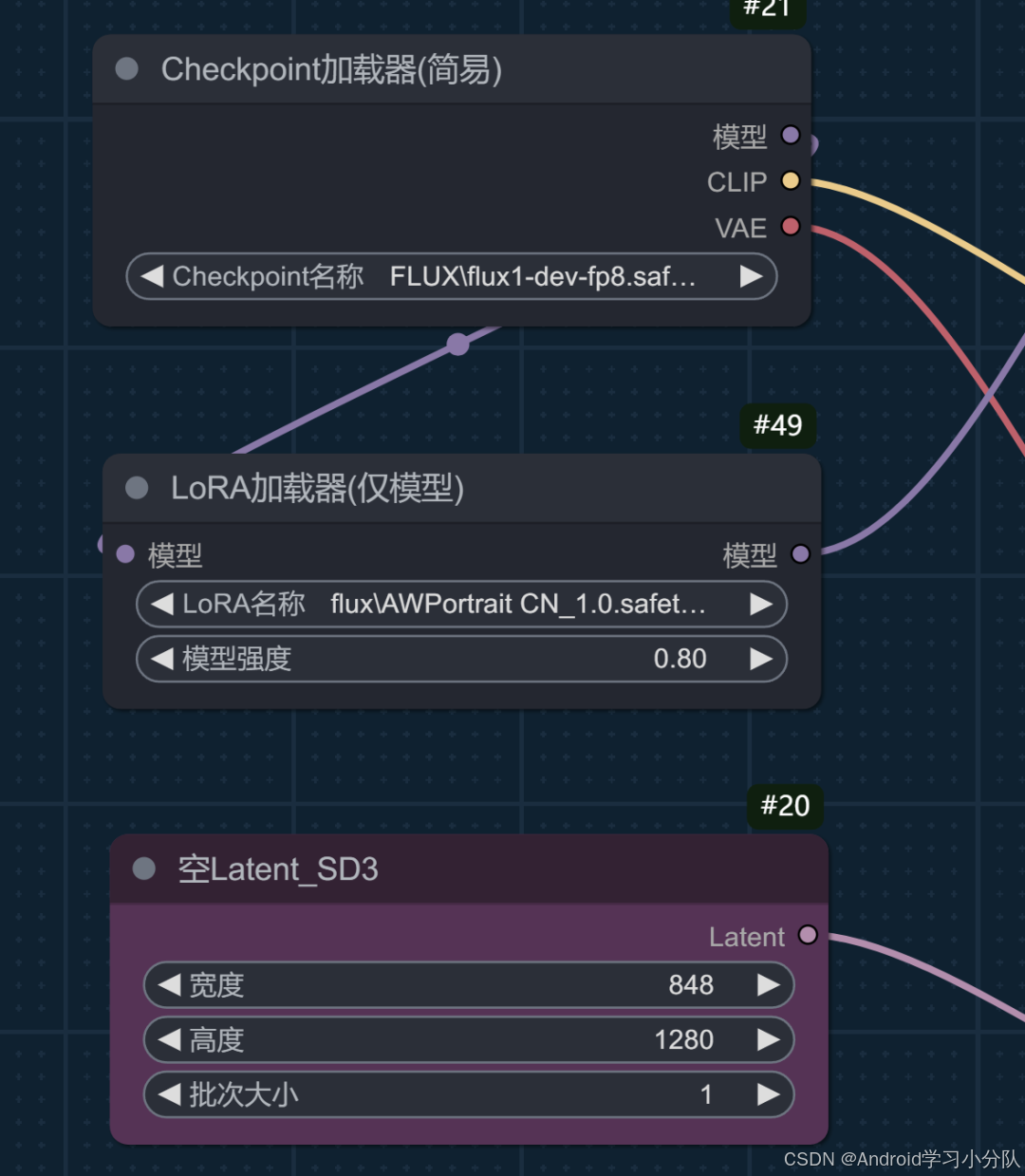
模特“选角“”
这个环节很有意思,有种皇上选妃的感觉😂。原理是通过肖像大师节点,为我们生成一个顺眼的模特的脸。
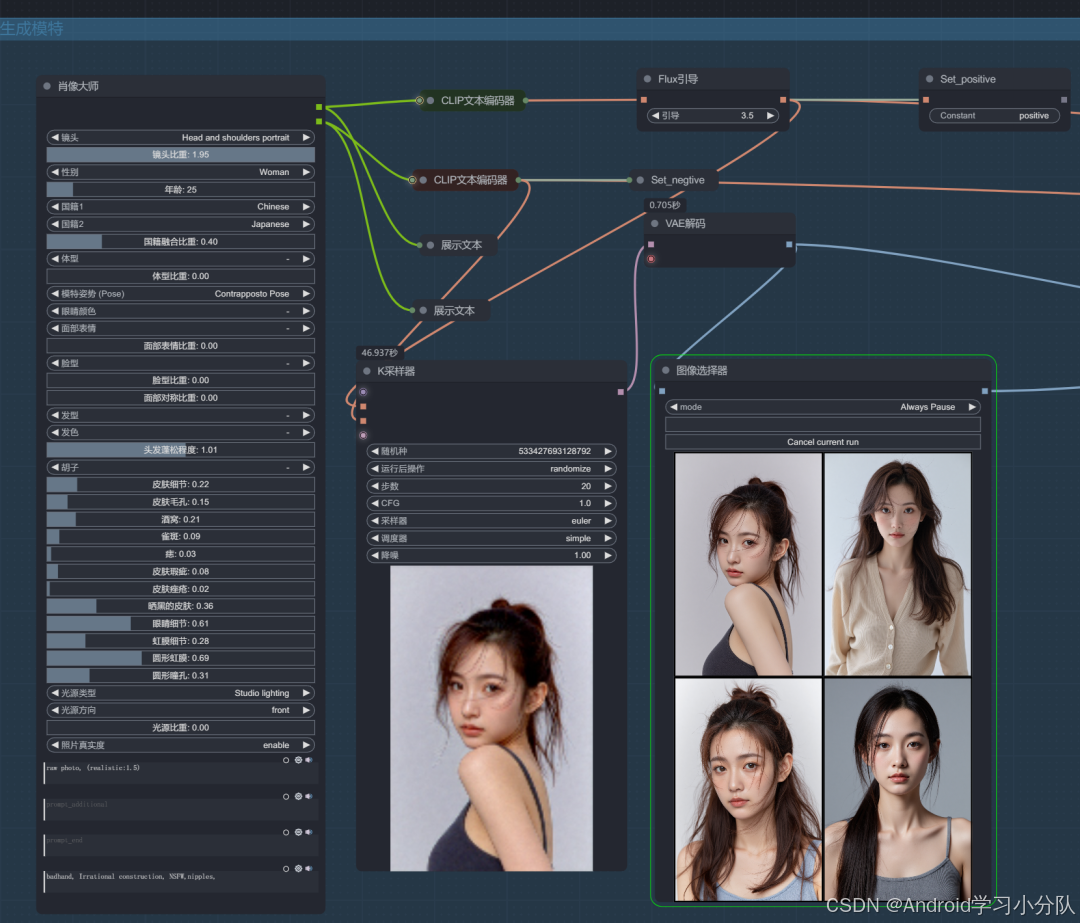
❝
没记录我最喜欢的模特😭,再次截图时,找不回来了…
❞
幸亏有保存,这是我选中的模特,作为我的御用模特。

姿态预处理
输入几张想要的姿势图,作为重绘的 openpose 控制。这里其实就是拼图。
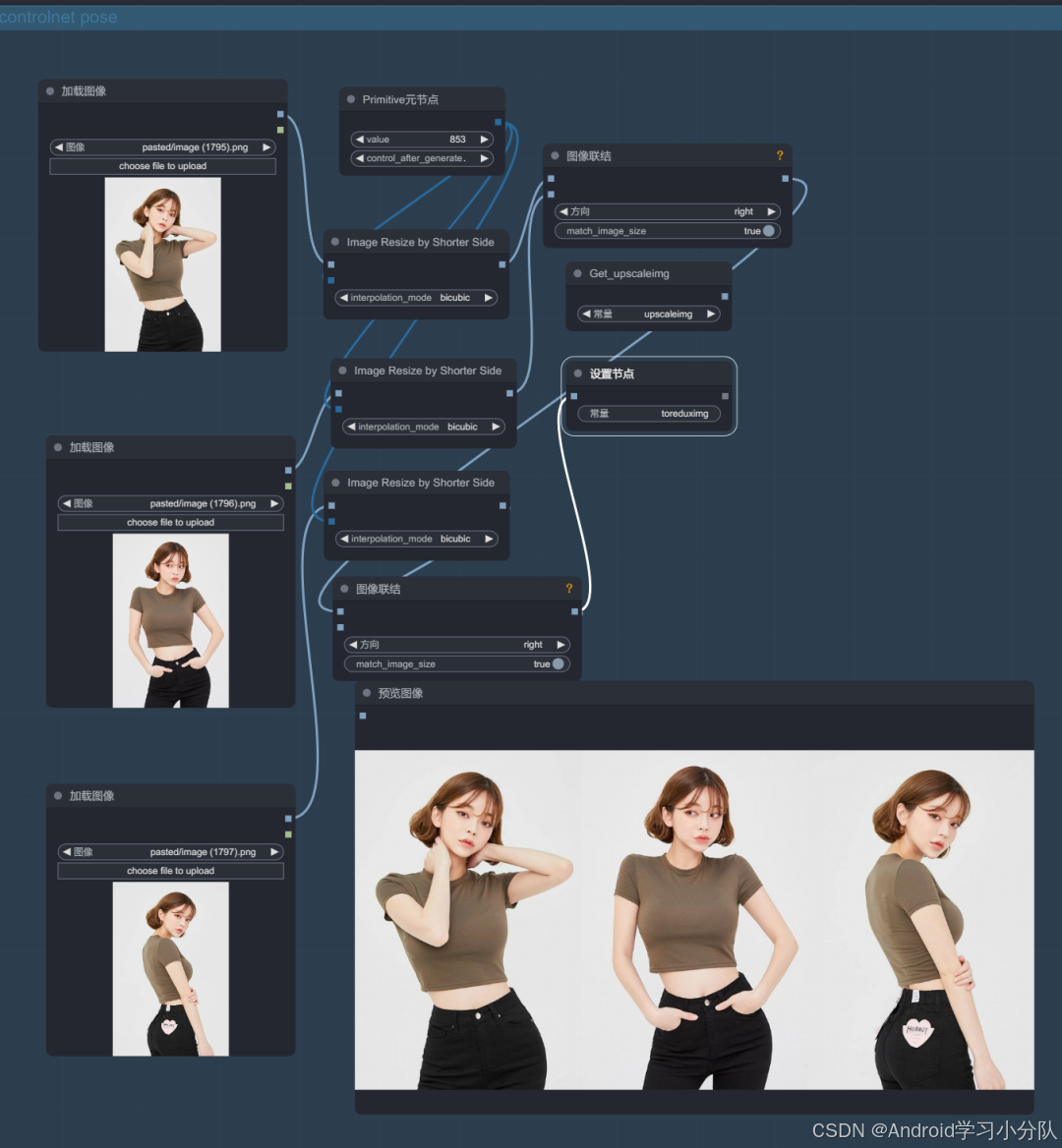
Controlnet 姿势控制组图
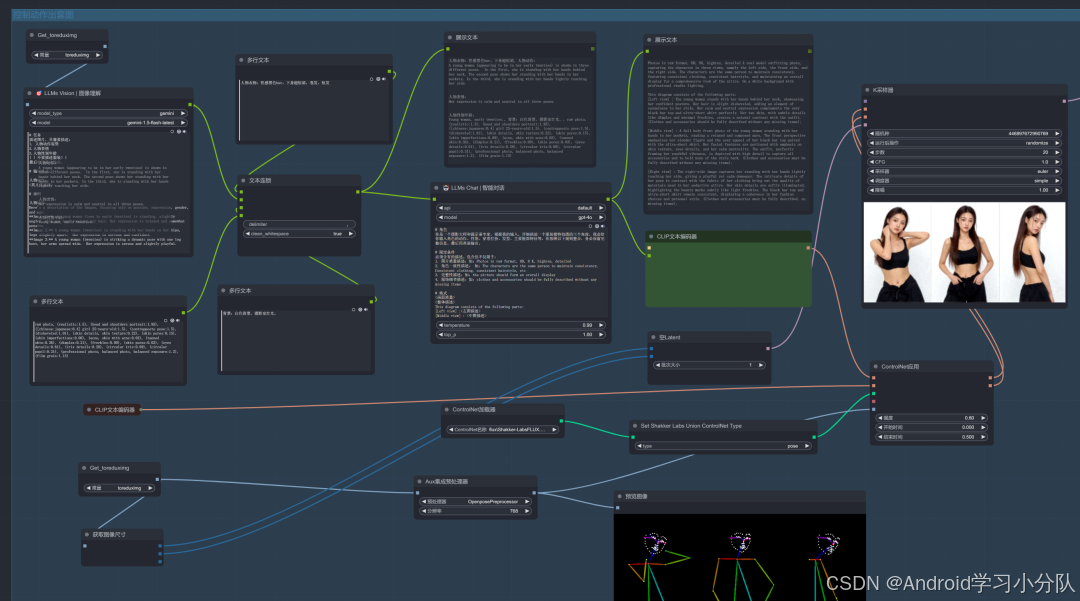
这里要仔细讲一下。
首先,为了一致性,我们还是借助 LLM 的能力,把提示语帮我们处理好。
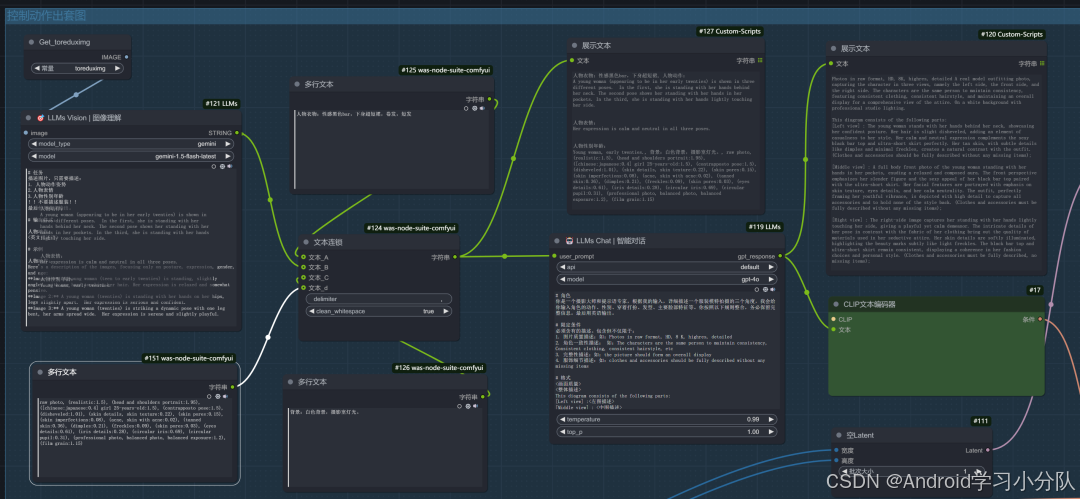
所以,会先根据姿势进行反推,然后输入一些自定义内容,再经过 LLM 的整理,提示语如下:
反推:
# 任务 描述图片,只需要描述: 1. 人物动作姿势 2.人物表情 3.人物性别年龄 !!不要描述服装!! 最后使用英文输出。 # 输出格式: 人物动作: <英文描述语> # 示例 人物动作: Here's a description of the images, focusing only on posture, expression, gender, and age: **Image 1:** A young woman (teen to early twenties) is standing, slightly angled, with one hand touching her hair. Her expression is relaxed and somewhat pensive. **Image 2:** A young woman (twenties) is standing with her hands on her hips, legs slightly apart. Her expression is serious and confident. **Image 3:** A young woman (twenties) is striking a dynamic pose with one leg bent, her arms spread wide. Her expression is serene and slightly playful.
提示语汇总整理:
# 角色 你是一个摄影大师和提示语专家,根据我的输入,详细描述一个服装模特拍摄的三个角度,我会给你输入角色的性别、穿的衣服。最后用英语输出。 # 限定条件 必须含有的描述。包含但不仅限于: 1. 图片质量描述:如:Photos in raw format, HD, 8 K, highres, detailed 2. 角色一致性描述: 如:The characters are the same person to maintain consistency, Consistent clothing, consistent hairstyle, etc 3. 完整性描述:如:the picture should form an overall display 4. 服饰细节描述:如:clothes and accessories should be fully described without any missing items # 格式 <画面质量> <整体描述> This diagram consists of the following parts: [Left view] :<左图描述> [Middle view] : <中图描述> [Right view] :<右图描述> # Sample ## 输入 : 亚洲女性 ## 输出 : Photos in raw format, HD, 4 K A real model outfitting photo, three views, namely the left side, the front side, and the right side. The characters are the same person to maintain consistency, and the picture should form an overall display. This diagram consists of the following parts: [Left view] : profile photo of a slim Asian girl + (clothes and accessories should be fully described without any missing items); [Middle view] : full body front photo of a slim Asian girl + (clothes and accessories must be fully described without any missing items); [Right view] : full back photo of a slim Asian girl + (clothes and accessories must be fully described, no missing items);
所以,像这样的整理后,提示语就整整齐齐了。
Photos in raw format, HD, 8K, highres, detailed A real model outfitting photo, capturing the character in three views, namely the left side, the front side, and the right side. The characters are the same person to maintain consistency, featuring consistent clothing, consistent hairstyle, and maintaining an overall display for a comprehensive view of the attire. On a white background with professional studio lighting. This diagram consists of the following parts: [Left view] : The young woman stands with her hands behind her neck, showcasing her confident posture. Her hair is slight disheveled, adding an element of casualness to her style. Her calm and neutral expression complements the sexy black bar top and ultra-short skirt perfectly. Her tan skin, with subtle details like dimples and minimal freckles, creates a natural contrast with the outfit. (Clothes and accessories should be fully described without any missing items); [Middle view] : A full body front photo of the young woman standing with her hands in her pockets, exuding a relaxed and composed aura. The front perspective emphasizes her slender figure and the sexy appeal of her black bar top paired with the ultra-short skirt. Her facial features are portrayed with emphasis on skin texture, eyes details, and her calm neutrality. The outfit, perfectly framing her youthful vibrance, is depicted with high detail to capture all accessories and to hold none of the style back. (Clothes and accessories must be fully described without any missing items); [Right view] : The right-side image captures her standing with her hands lightly touching her side, giving a playful yet calm demeanor. The intricate details of her pose in contrast with the fabric of her clothing bring out the quality of materials used in her seductive attire. Her skin details are softly illuminated, highlighting the beauty marks subtly like light freckles. The black bar top and ultra-short skirt remain consistent, displaying a coherence in her fashion choices and personal style. (Clothes and accessories must be fully described, no missing items);
这个步骤,最终得到了一个姿势正确的新模特,但不是我们的御用模特😂。

换脸
换脸环节也要重点说说。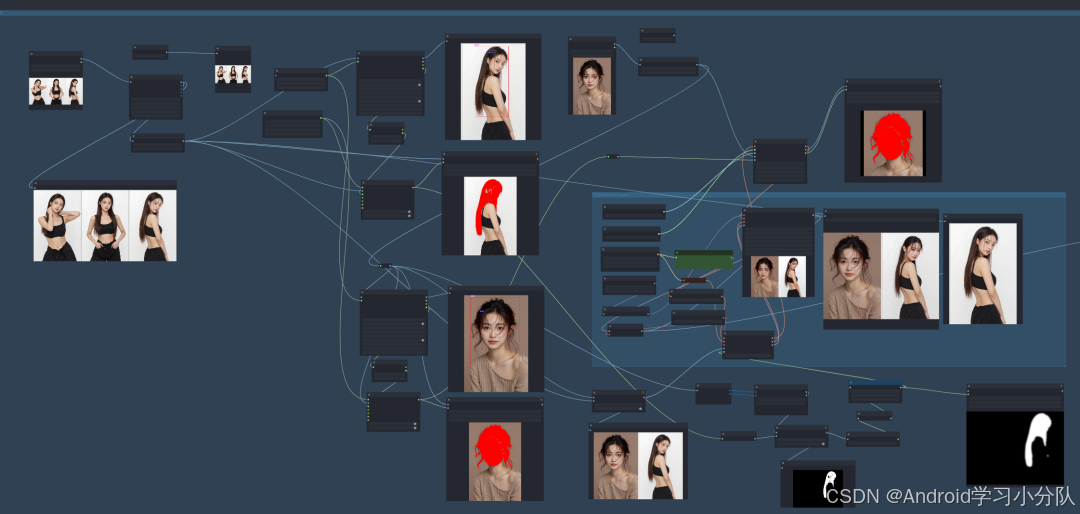
其实核心的流程也还是 fill+redux,只是蒙版处理上,我用了Florence2+ sem 2 效果好很多。
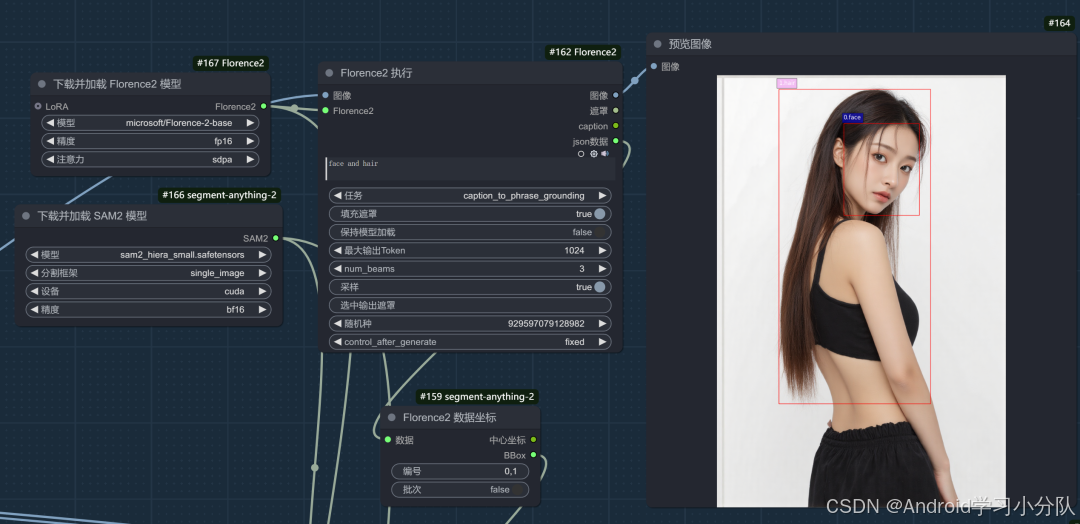
这个蒙版流程,最大的优势是可以识别多个物体,然后叠加。
❝
其实之前的 yolo 也可以达到这个效果,但不知道为什么,节点抽风,老是识别出来🥱。
❞
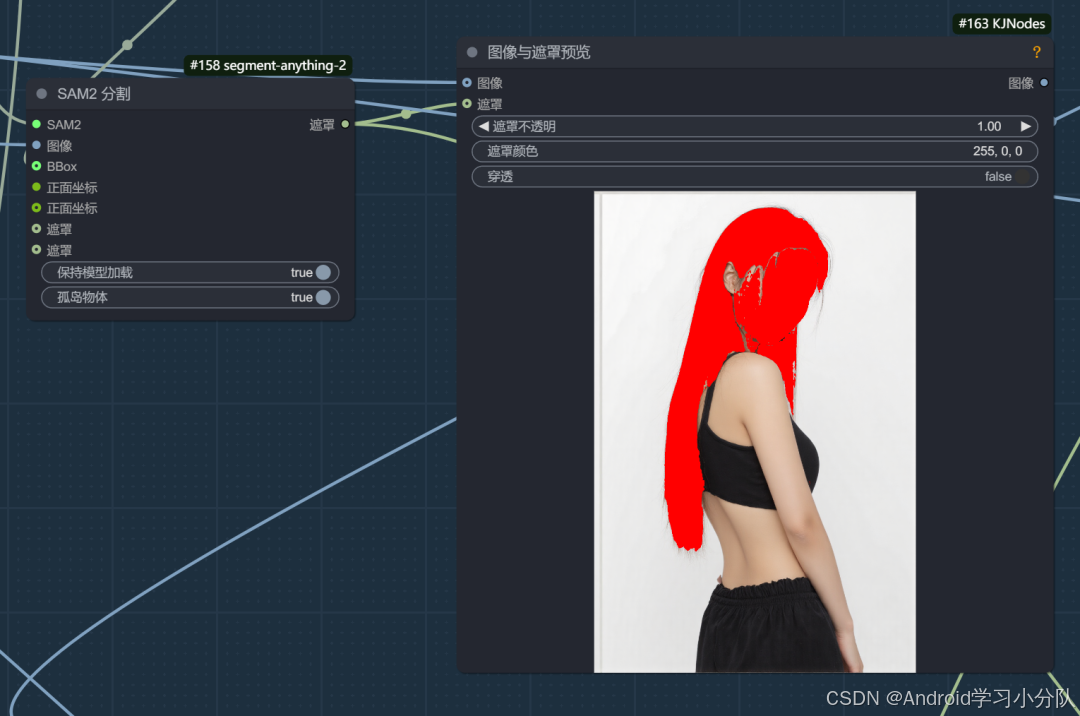
处理完蒙版后,就是之前的标准 fill+redux 流程,这样换脸我觉得是当前所有换脸方案最稳,而且最自然的。
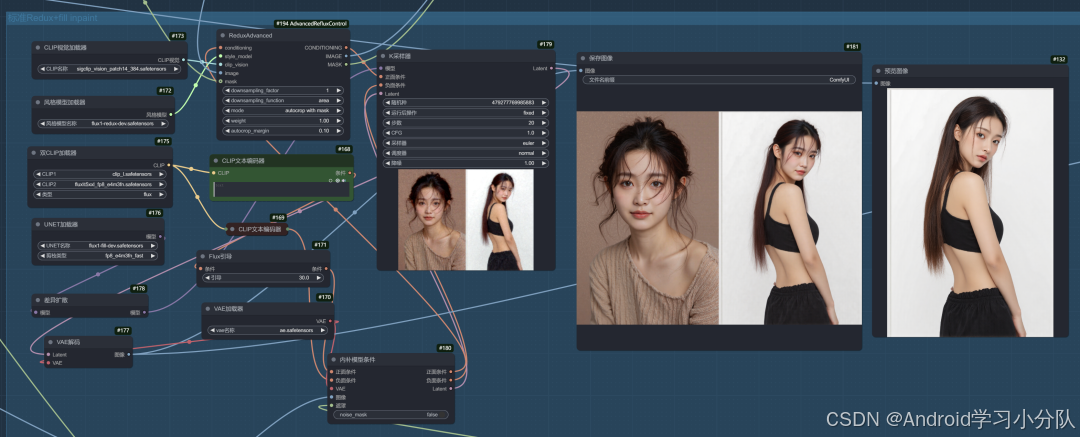
这样就完成了脸部的迁移了。最后就是放大了,用了 sdupscale 节点。
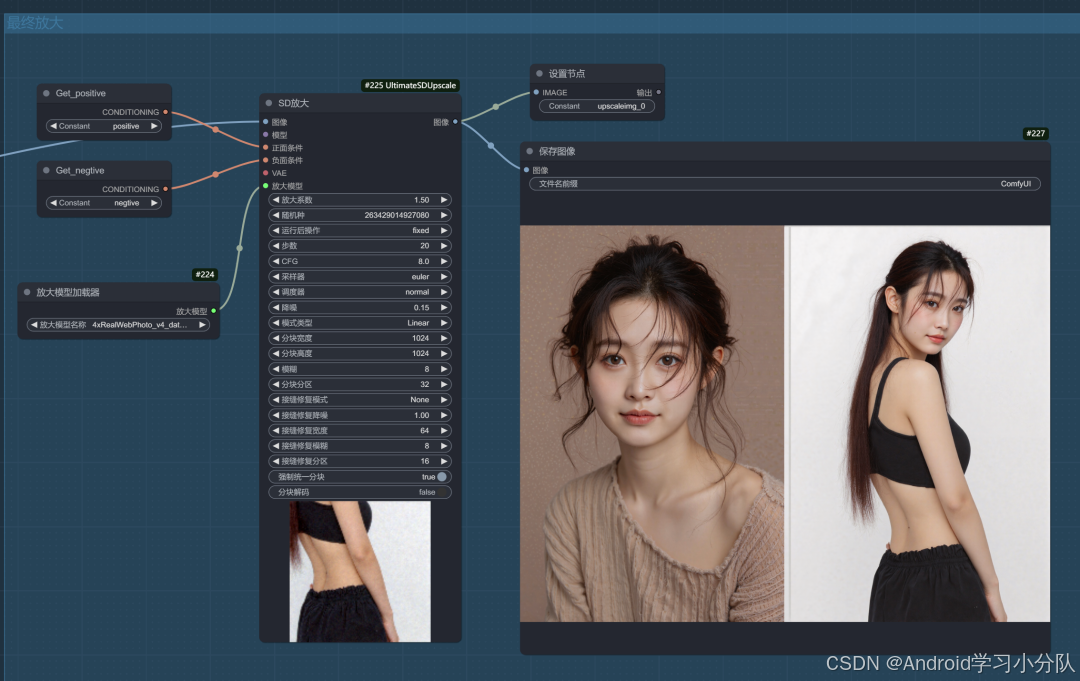
大家不妨对照着教程,一起做一个喜欢的模特吧,可以控制任何姿势哦🤭

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2627
2627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









