






买一套绘本少则几十多则几百,买了一套回来后宝贝老是粘着你让你给他讲绘本,没有时间讲但宝贝还想看怎么办?纸质绘本虽然有精美的画面,但是孩子他还不认识字,怎么能让孩子理解故事?最后就是买了一大摞绘本放在那里积灰!!!
那天收拾家里发现之前买的好多绘本,都在角落里吃灰,好几本还是包装膜都还没有撕开,真是痛苦又自责。当时想着给孩子培养各种认知,引导孩子面对并抒发脾气与情绪等等,真是美其名曰,最后只有苦笑。

当下AI那么火,为何不用AI制作绘本,既有精美的图片,又能自动播放和朗读。不管你是什么行业、什么角色,跟着这篇文章都能轻松制作出精美的绘本故事。
全程AI制作,及能定制输出,还能分享赚钱
废话少说,现在就带你开始:
今天分享一个如何用Stable Diffusion制作儿童绘本,儿童绘本制作起来会稍微简单一些。
一个小想法
现在大部分的孩子或学生都会写作文,如果把孩子写的作文转化为一个生动的小视频,是不是能够提高他们的创作成就感,同时也能激发他们对阅读和写作的兴趣呢?
1
前期准备
本文将会用到“Stable Diffusion ”、“极虎漫剪 ”、“剪映 ”以及一个Stable
Diffusion的插件“Agent Scheduler
”。对了,还有绘本内容,绘本内容可以用AI语言大模型生成,或者如果有现成也可以,然后直接复制粘贴到一个Word文档上即可。
Stable
Diffusion以及剪映我就不介绍啦。
2. Agent Scheduler插件安装,Agent Scheduler是一个Stable Diffusion里面的一个批量生成图片的插件。
(注意:需要的小伙伴可以文末自行扫描获取)
有三种安装方法:
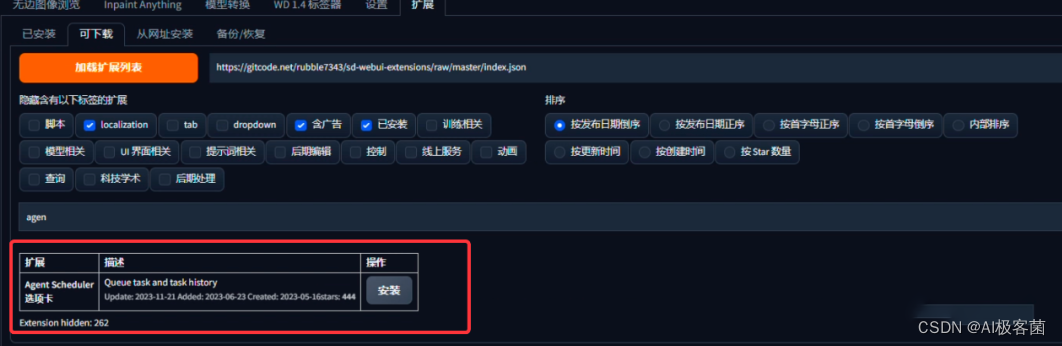
1. 启动“Stable Diffusion”,点击“扩展”—“可下载”—在点击“加载扩展列表”,搜索关键词“agent
scheduler”,点击“安装“,安装完成之后,重启一下“Stable Diffusion”即可。
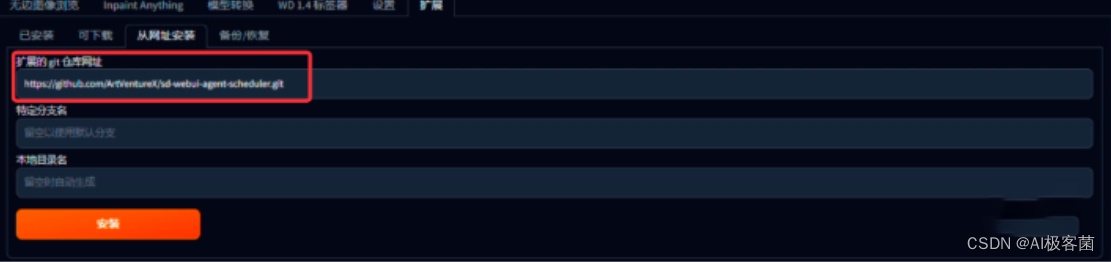
2. 从网址安装,复制Github的URL,将插件的URL粘贴到“扩展的git仓库网址”上,在点击”安装“,安装完成之后,重启一下”Stable
Diffusion“即可。
(注意:需要的小伙伴可以文末自行扫描获取)
3. 插件安装包安装,在Github下载该插件的安装包并安装到“Stable Diffusion”目录中的“extensions”文件夹中即可。
2
绘本制作
安装好所有的插件以及工具之后,就可以开始之后绘本啦。
1. 首先,启动“Stable Diffusion ”,并打开“极虎漫剪 ”。
2. 打开“极虎漫剪 ”,没注册的可以点击右上角注册,已注册并登录的,点击“创作视频 ”,输入”项目名称
”然后再点击“创建项目 ”。

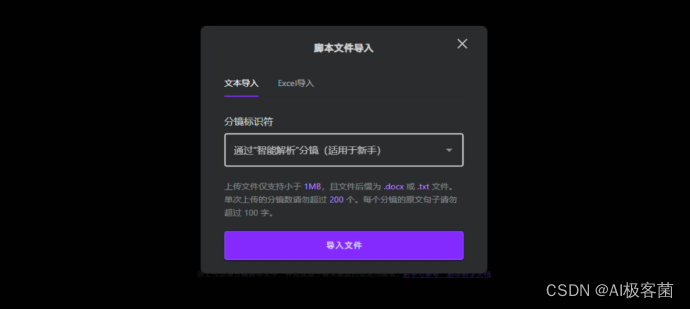
3. 点击中间的“脚本文件导入 ”,分镜标识符选择“通过“智能解析”分镜 ”然后点击“导入文件
”选择准备好的绘本导入即可。如果自己已经分好镜了,建议使用“Excel”导入。
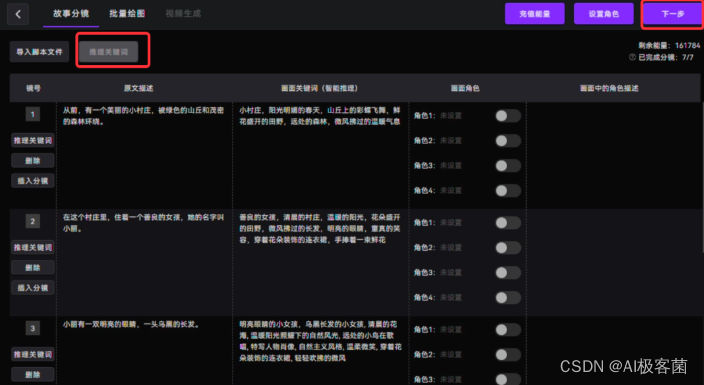
4. 绘本导入了之后,它会自动帮我们进行智能分镜。分完镜之后,点击左上角的“推理关键词 ”按钮,关键词推理完之后,点击“下一步 ”即可。
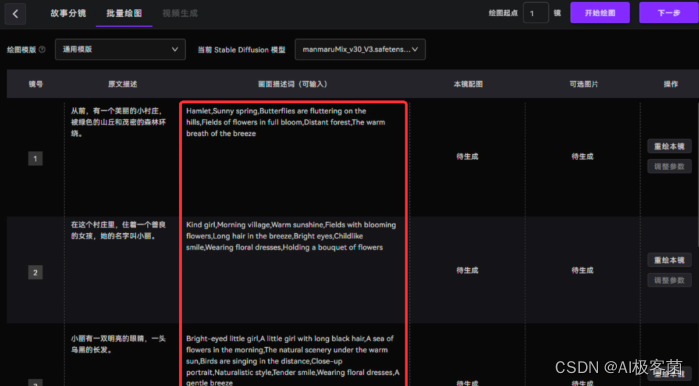
5. 到了“批量绘图
”这一步之后,它就会将关键词翻译成英文,极虎漫剪就可以用到这里了,我们只需要这里的分镜以及关键词。如果想继续用“极虎漫剪”可以直接“开始绘图
”。之前已经详细介绍了使用“极虎漫剪”的方法,本文将介绍使用Stable Diffusion的插件“agent scheduler ”来进行制作。
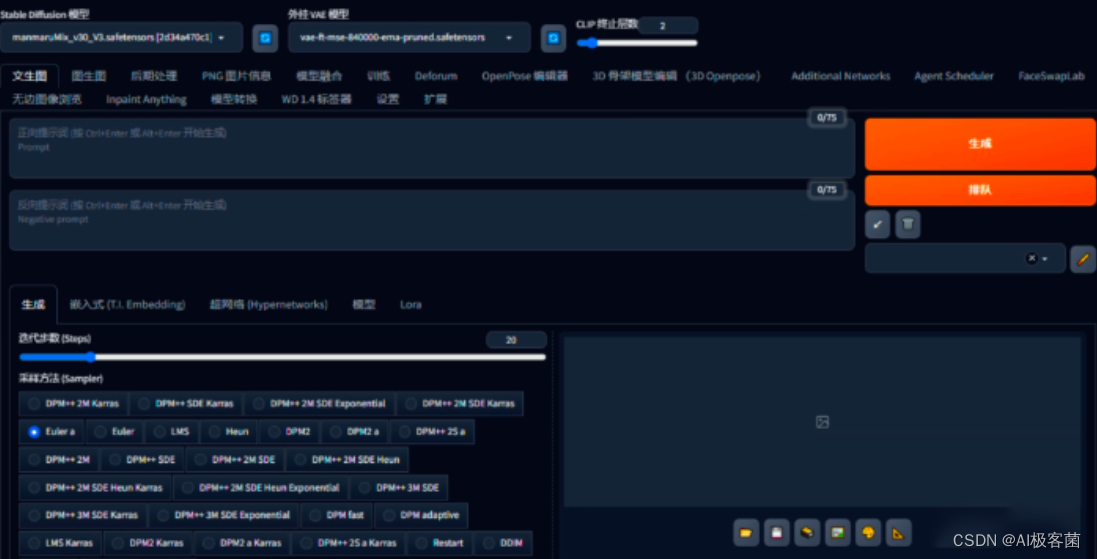
6. 打开刚刚已启动的Stable Diffusion,选择一个用于制作绘本的大模型。

这里的大模型我选择的是“manmaruMix_v30 ”很适合做儿童绘本的大模型,可以在“liblib ”和“Civitai
”上下载此模型。(在这里感谢这位模型作者的分享,谢谢!)

7. 输入正向提示词和反向提示词。反向提示词用一个通用的即可,正向提示词这里在最前面可以加一些质量的提示词,然后后面的加上刚刚用极虎漫剪推理出来的提示词。
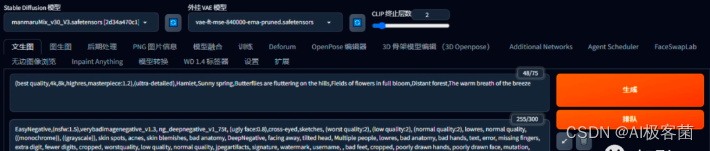
对了,差点忘了!,点击菜单栏上的“Agent Scheduler ”插件,然后点击“暂停
”,在我们还未添加完所有镜头的提示词之前,最好先暂停,以防止在参数未设置好的情况下就开始生成。
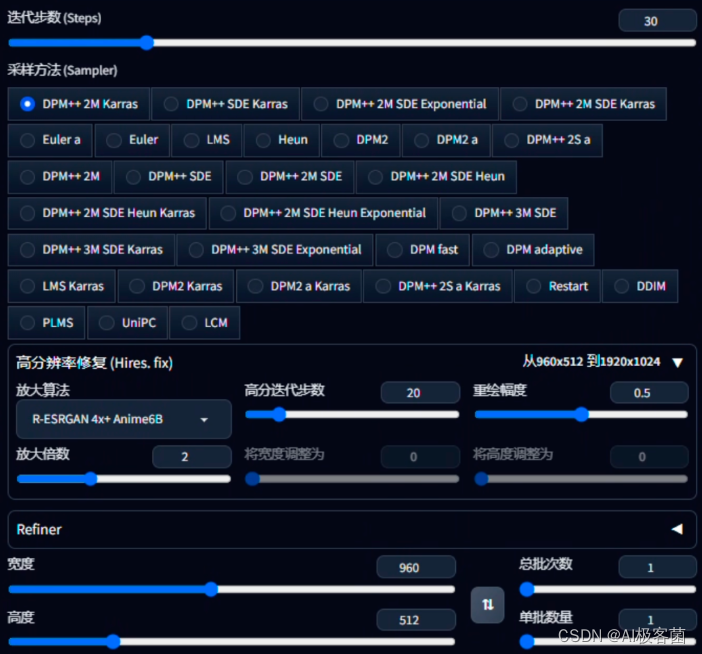
8. 设置绘本生成的参数,这里根据自己的需求设置一下就行。
9. 设置好以上参数之后,点击“生成”下面的“排队 ”,它就会将这第一镜的提示词以及参数,发送到“Agent Scheduler
”插件里面,然后将“任务ID ”改为1或者第一镜的内容,这样可以更清晰的看到每一镜的参数。
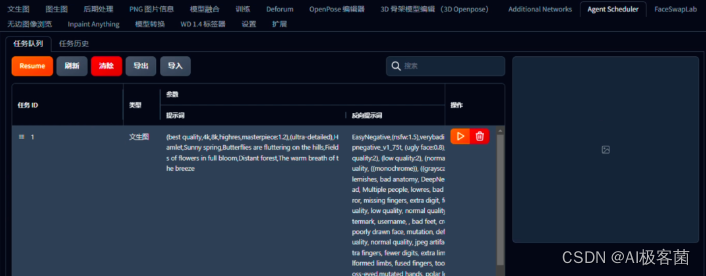
对于剩余的镜头,只需将剩余镜头的提示词依次粘贴到正向提示词中,然后点击“排队 ”即可。生成参数可保持不变。
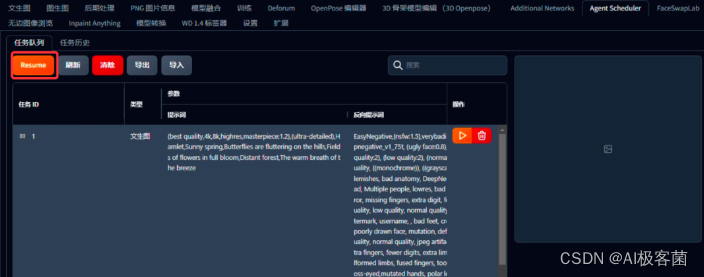
10. 将所有的镜头添加完之后,可以检查一下看还有没有遗漏的或者有没有需要改的参数,然后点击左上角的“Resumer ”就开始生成啦。
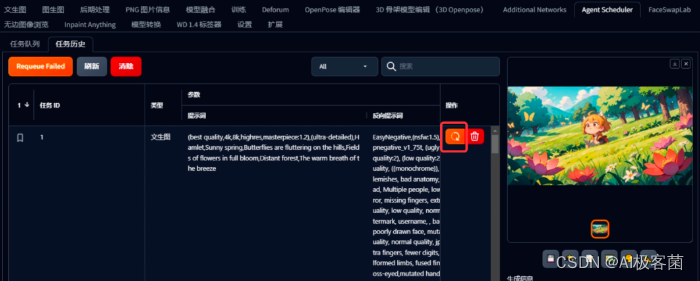
11. 当图片生成完成后,点击“任务历史
”可以查看刚刚生成的所有图片。如果对结果不满意,可以双击列表并调整提示词和参数。在调整后,点击右侧操作区的重新生成按钮,即可重新生成该镜头的图片。对满意的图片可以,点击保存,将图片保存下来。
图片都准备就绪之后,可以通过图片处理工具进行文字添加,由此,静态的绘本便得以呈现。对于希望将其转化为视频的,可以继续往下看。
3
视频合成
在制作视频之前,我们可以利用绘本内容生成一段音频,以便后续更便捷地生成字幕。
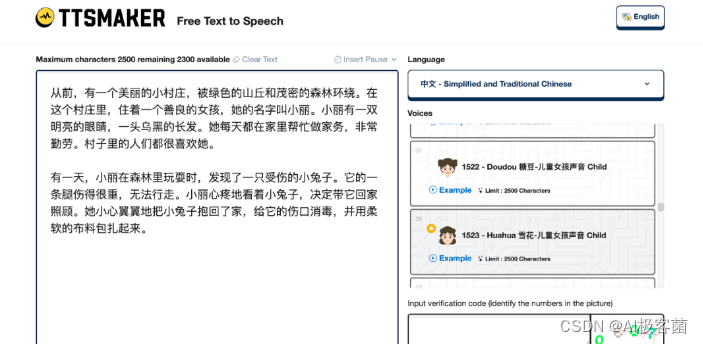
1. 打开“TTSMaker ”,将绘本内容复制并粘贴到输入框中。接着,选择语言以及音色。如果要进行更多设置,可以点击“更多设置
”;若对此保持默认,只需点击“转换为语音 ”,即可生成音频。
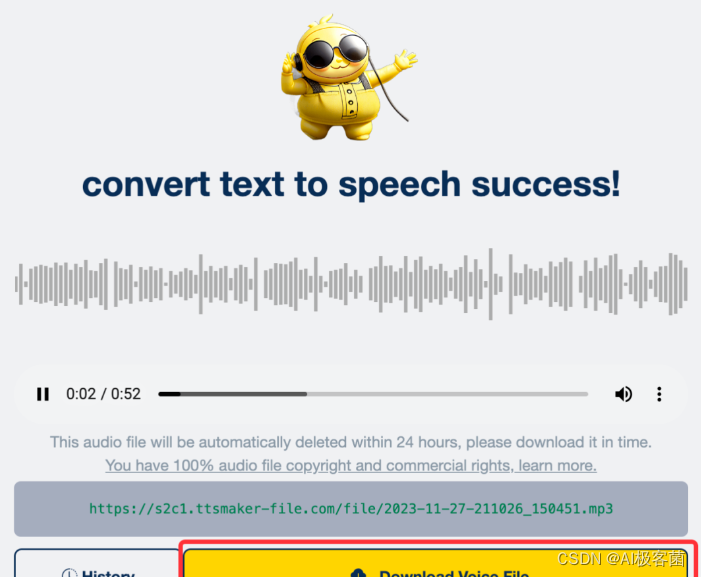
2. 生成完成之后,点击下载音频即可。
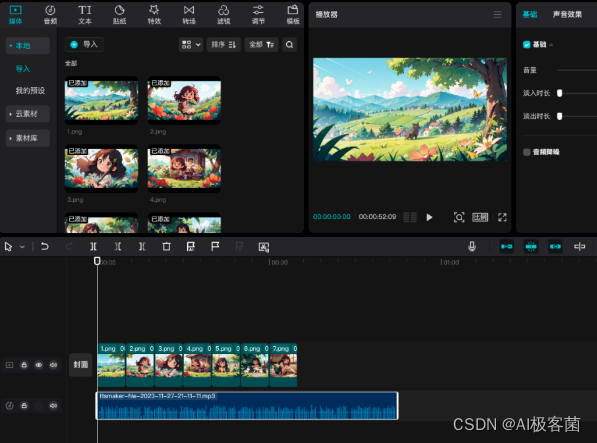
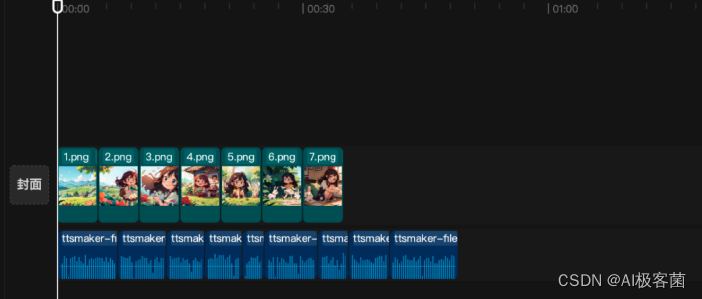
3. 音频生成完之后,打开“剪映 ”,将刚刚准备好的图片以及音频导入到剪映。
4. 导入完成之后,可以把音频的气口处理一下。例如,如果某些地方的气口过长,可以适当剪短一些,这样会使听感更加舒适。
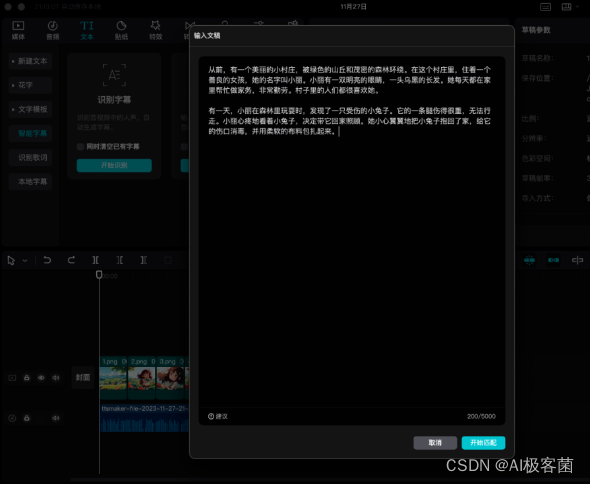
5. 处理完音频之后,就可以开始生成字幕了,点击左上角的“文本 ”-“智能字幕 ”-“文稿匹配
”将绘本内容复制粘贴进去,然后点击开始匹配。
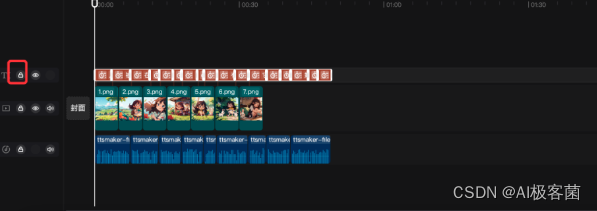
6. 字幕生成完成之后,选中所有的字幕,然后点击右侧有个锁的图标,将字幕锁住。(锁住字幕可以更方便的将图片与音频对上)
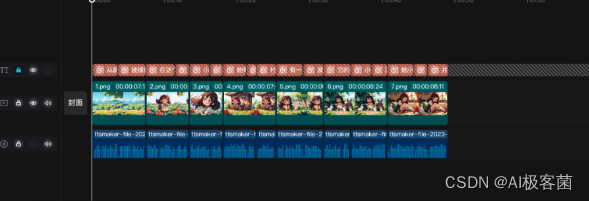
7. 这一步就比较繁琐了,需要将图片跟音频对上。可以一边看“极虎漫剪”生成分镜,然后一边手动的将图片对上音频(如果嫌麻烦,可以在“极虎漫剪”上完成)。
8. 接下来可以将字幕颜色以及字体稍微调整一下,然后添加一个背景音乐。
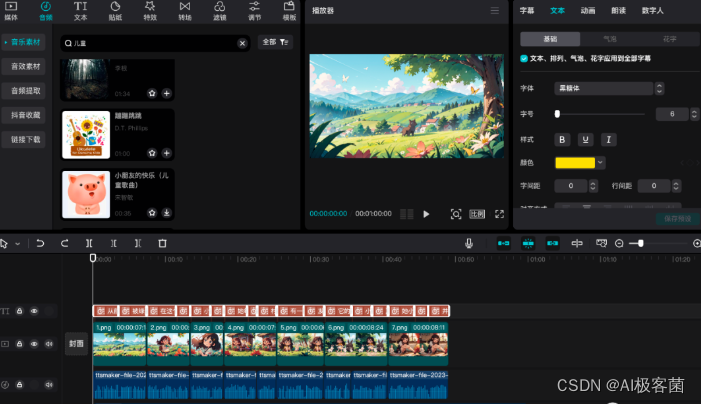
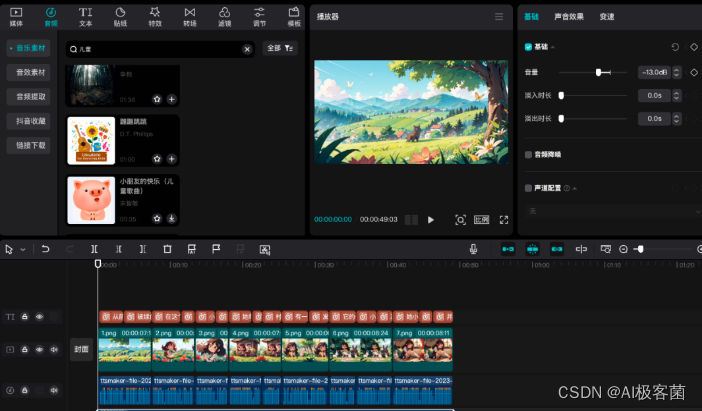
9. 将背景音乐剪到一个合适的长度,然后背景音乐的音量调整到“-13.0dB ” 左右,然后配音的音量调整到“8.0dB
”左右即可。确保背景音乐的声音不会超过配音的音量。
10. 目前的图片还是静态的,这里可以让图片稍微动起来一些。例如,可以给每张图片添加上下或左右移动的关键帧,这样可以让整个视频在视觉上更加生动、有趣。
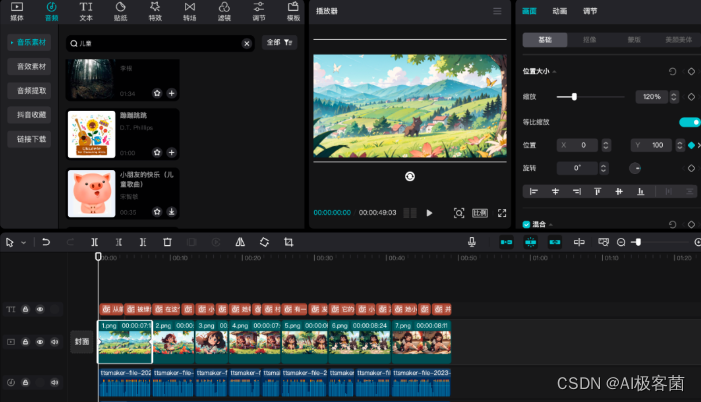
这里我将每一张图片都放大到了120%,并且给每一张图片都打了上下移动的关键帧(第一张图片的起始帧为100,结束帧为-200;第二张图片的起始帧为-100,结束帧为200,以此类推)。
10. 到这里就制作完成啦,如果还想加点东西,可以稍微加一些音效、特效等等。调整完之后,点击左上方的“文件 ”-“导出 ”导出视频。
4
最后
以上就是今天的所有分享。现在大部分孩子或学生都具备写作的能力,如果将他们所写的作文转化为具有生动情节的绘本、小视频,或者以孩子或自己为主角生成绘本,将带来一种独特的代入感,使整个写作或阅读过程更加有趣。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!

零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 4518
4518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









