






基本信息
CIFAR-10是一个包含60000张图片的数据集。其中每张照片为32*32的彩色照片,每个像素点包括RGB三个数值,数值范围为0~255。
这60000张图片分为十个类别"airplane", "automobile", "bird", "cat","deer", "dog", "horse", "ship", "truck"。其中前50000张为训练集,后10000张为测试集。
数据集下载
打开下面的链接进入官网下载
http://www.cs.toronto.edu/~kriz/cifar.html
选择python版本下载

然后解压,得到文件如下:
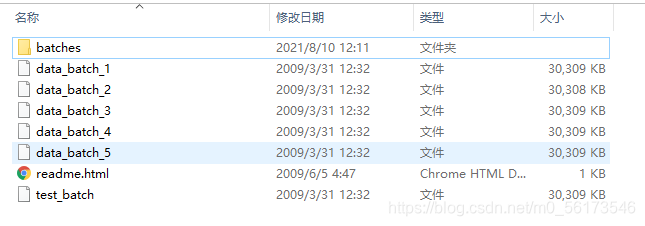
data_batch_1~data_batch_5是训练集数据,每个文件里有10000张图片,test_batch是测试集数据,也含有10000张图片。
转成图片
import numpy as np
import pickle
import imageio
import os
# 解压缩,返回解压后的字典
def unpickle(file):
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='latin1')
fo.close()
return dict
list = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
for z in range(10):
if os.path.exists('train/' + list[z]) == False:
os.makedirs('train/' + list[z])
if os.path.exists('val/' + list[z]) == False:
os.makedirs('val/' + list[z])
# 生成训练集图片,如果需要png格式,只需要改图片后缀名即可。
for j in range(1, 6):
dataName = "data_batch_" + str(j)
# 读取当前目录下的data_batch12345文件,dataName其实也是data_batch文件的路径,本文和脚本文件在同一目录下。
Xtr = unpickle(dataName)
print(dataName + " is loading...")
for i in range(0, 10000):
img = np.reshape(Xtr['data'][i], (3, 32, 32)) # Xtr['data']为图片二进制数据
img = img.transpose(1, 2, 0) # 读取image
picName = 'train/' + list[Xtr['labels'][i]] + '/' + str(i + (j - 1)*10000) + '.png'
# Xtr['labels']为图片的标签,值范围0-9,本文中,train文件夹需要存在,并与脚本文件在同一目录下。
imageio.imwrite(picName, img)
print(dataName + " loaded.")
print("test_batch is loading...")
# 生成测试集图片
testXtr = unpickle("test_batch")
for i in range(0, 10000):
img = np.reshape(testXtr['data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0)
picName = 'val/' + list[testXtr['labels'][i]] + '/' + str(i) + '.png'
imageio.imwrite(picName, img)
print("test_batch loaded.")这些代码需要自己修改一下文件的路径,有8处
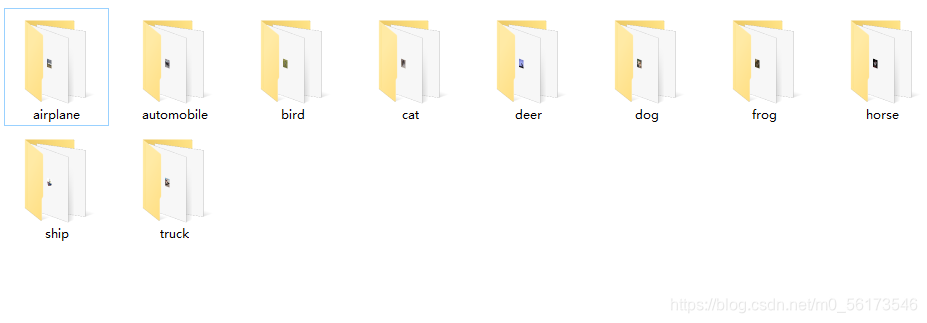
其实这些代码只是在前辈的基础上加了点东西,为了更好适应我自己学习的代码写的,运行完后得到的数据集是这样的。下图为train文件夹中的样子,每个文件中有5000张图片。val文件中的样子和这个一样,只是里边子文件的图片只有1000张而已。

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









